Brion Vibber wrote:
On Sun, 2003-09-21 at 18:29, E23 wrote:
>Example: n processes arrive at the same time. If the necessary CPU time
>for every process is t seconds, all processes will finish after t*n
>seconds in a concurrent system.
>
>If, on the other hand, the processes run completely serialized, one
>after another, the first process will finish after t seconds, the second
>one after 2*t seconds and so on up to n*t seconds for the n:th process.
>This gives an average running time of t*n/2 seconds, with a worst case
>time of t*n.
Your formulas work as long as the processes are not waiting for hardware
at any stage. The apache processes don't, significantly, so that's okay.
You wouldn't want to try this with the DB though.
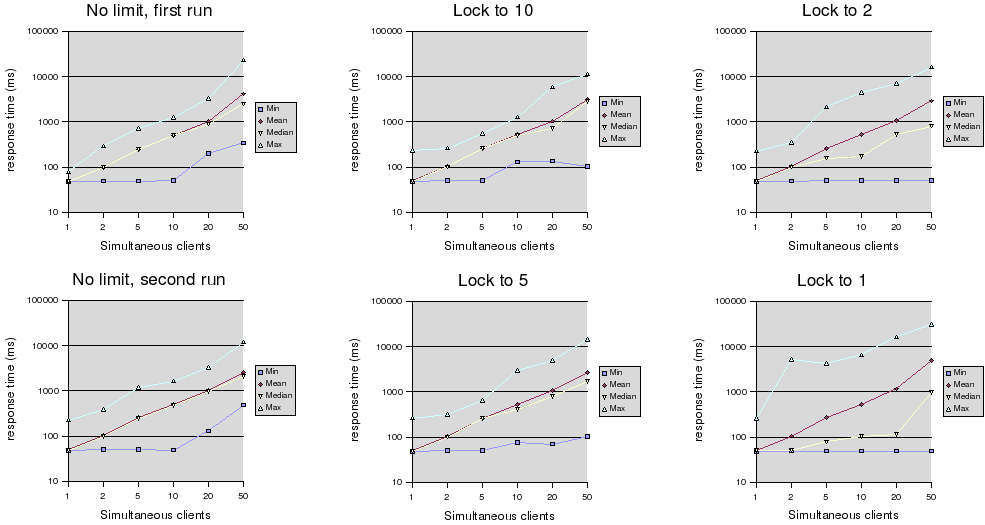
My very naive quick testing shows that while there is
an improvement in
the median time when locking kicks in, there is no significant
difference in average (mean) response time; the shorter times for some
are paid for by a significant increase in the length and proportion of
slow responses for others.
See benchmark:
http://meta.wikipedia.org/wiki/Lock_response_times
http://meta.wikipedia.org/upload/1/1d/Lock-times.png
Of course, I could be doing something wrong, and this benchmark is very
very naive, making no attempt to work with different types of requests.
Could we mitigate the effect of slow queries blocking the server, by
allowing other threads to run once the lock times out? I'm thinking
something like this:
for ( $semIdx=0;
!wait_for_semaphore($semIdx) && $semIdx < 10;
$semIdx++ );
if ( $sem == 10 ) {
print "Sorry too much traffic\n";
} else {
do query
release_semaphore($semIdx);
}
-- Tim Starling
{kind=link}