Secure basically fell over for awhile, generated nothing but proxy errors. I'm not sure that's what really happened. It may have been a complete inability to actually send or receive data, resulting in a timeout of some sort.
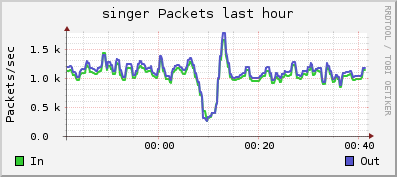
Take a look at the Ganglia graphs. Free memory gone. Big spike in processes. Big drop in network activity!
On 14/03/11 11:48, William Allen Simpson wrote:
Secure basically fell over for awhile, generated nothing but proxy errors. I'm not sure that's what really happened. It may have been a complete inability to actually send or receive data, resulting in a timeout of some sort.
Take a look at the Ganglia graphs. Free memory gone. Big spike in processes. Big drop in network activity!
It was because of the CPU overload on the entire apache cluster which occurred at that time. Secure and every other frontend proxy would have reported errors. Domas and I traced it back to job queue cache invalidations from an edit to [[Template:Reflist]] on the English Wikipedia.
Note that the free memory isn't gone. RRDtool has the very unscientific practice of starting the vertical scale at something other than zero. It rose because processes use memory, and as you noted, the number of processes increased. This is because they were queueing, waiting for the overloaded backend cluster to serve them.
-- Tim Starling
On 11-03-13 06:05 PM, Tim Starling wrote:
On 14/03/11 11:48, William Allen Simpson wrote:
Secure basically fell over for awhile, generated nothing but proxy errors. I'm not sure that's what really happened. It may have been a complete inability to actually send or receive data, resulting in a timeout of some sort.
Take a look at the Ganglia graphs. Free memory gone. Big spike in processes. Big drop in network activity!
It was because of the CPU overload on the entire apache cluster which occurred at that time. Secure and every other frontend proxy would have reported errors. Domas and I traced it back to job queue cache invalidations from an edit to [[Template:Reflist]] on the English Wikipedia.
Note that the free memory isn't gone. RRDtool has the very unscientific practice of starting the vertical scale at something other than zero. It rose because processes use memory, and as you noted, the number of processes increased. This is because they were queueing, waiting for the overloaded backend cluster to serve them.
-- Tim Starling
Interesting. Which part specifically do you think actually caused the extreme load? Having to re-parse a large number of pages as people view them? Did the issue show up from invalidation pre-queue, or did the issue crop up after the jobs were run? Was this just isolated to the secure servers, ie: didn't really effect the whole cluster but was simply an issue because secure doesn't have as large a deployment as non-secure?
~Daniel Friesen (Dantman, Nadir-Seen-Fire) [http://daniel.friesen.name]
On 14/03/11 12:37, Daniel Friesen wrote:
Interesting. Which part specifically do you think actually caused the extreme load? Having to re-parse a large number of pages as people view them?
Yes, regular page views caused the load, after the cache was invalidated.
Did the issue show up from invalidation pre-queue, or did the issue crop up after the jobs were run?
After the jobs were run. The edits were made over a week ago.
Was this just isolated to the secure servers, ie: didn't really effect the whole cluster but was simply an issue because secure doesn't have as large a deployment as non-secure?
It affected the whole cluster. I thought I already said that. Secure is just a single server which acts as a proxy. It decrypts the requests and forwards them back to the main apache cluster. There was no problem with secure, it was reporting errors appropriately.
For now I have added a sleep() to the code to limit invalidations to 100 pages per second per job runner process.
-- Tim Starling
On 14/03/11 19:52, Domas Mituzas wrote:
For now I have added a sleep() to the code to limit invalidations to 100 pages per second per job runner process.
Mass invalidations will create MJ issue in the long tail though... Need poolcounter ;-)
That's why Platonides wrote it for us. Now we just have to package it and deploy it.
There was a CPU spike after my change, but that was probably because 100 invalidations per second was still too fast, rather than a Michael Jackson type of problem.
On IRC, Daniel Friesen suggested pushing new HTML into the parser cache from the job queue instead of invalidating. Maybe after we move the parser cache to disk, that will be a good option.
-- Tim Starling
Thanks for responding. I hoping to help track down the reason we're getting so many Proxy Errors, but sadly this was a general problem.
Don't know what a "MJ issue in the long tail" means?
On 15/03/11 02:44, William Allen Simpson wrote:
Thanks for responding. I hoping to help track down the reason we're getting so many Proxy Errors, but sadly this was a general problem.
Don't know what a "MJ issue in the long tail" means?
Well, an "MJ issue" is a special kind of performance problem that affects very popular pages, like how popular the [[Michael Jackson]] article was in the few hours after his death. See wikitech-l from around that date. The "long tail" is a buzzword referring to the low-frequency end of a Zipf distribution, i.e. the least popular articles. So it's hard to see how an MJ issue could be in the long tail. I think he just means an MJ issue.
-- Tim Starling
On 11-03-14 03:05 PM, Tim Starling wrote:
On 15/03/11 02:44, William Allen Simpson wrote:
Thanks for responding. I hoping to help track down the reason we're getting so many Proxy Errors, but sadly this was a general problem.
Don't know what a "MJ issue in the long tail" means?
Well, an "MJ issue" is a special kind of performance problem that affects very popular pages, like how popular the [[Michael Jackson]] article was in the few hours after his death. See wikitech-l from around that date. The "long tail" is a buzzword referring to the low-frequency end of a Zipf distribution, i.e. the least popular articles. So it's hard to see how an MJ issue could be in the long tail. I think he just means an MJ issue.
-- Tim Starling
There's http://en.wikipedia.org/wiki/Long_Tail -- ;) and yes I understand the irony of quoting Wikipedia in a discussion about WP on wikitech.
I think he might mean that invalidating the cache of a large number of semi-popular long tail pages (being the long numper pages we serve less hits to, but hit a similar volume of traffic to a page like MW's when you add all of them together) at the same time could create a similar performance issue to the invalidation of a single extremely article article like MJ was. Simply because we're invalidating a number of not top-## pages, but popular enough that the total number of people viewing the collection of pages gets close to the traffic one MJ-popular article gets.
~Daniel Friesen (Dantman, Nadir-Seen-Fire) [http://daniel.friesen.name]
On 3/14/11 6:34 PM, Daniel Friesen wrote:
I think he might mean that invalidating the cache of a large number of semi-popular long tail pages (being the long numper pages we serve less hits to, but hit a similar volume of traffic to a page like MW's when you add all of them together) at the same time could create a similar performance issue to the invalidation of a single extremely article article like MJ was. Simply because we're invalidating a number of not top-## pages, but popular enough that the total number of people viewing the collection of pages gets close to the traffic one MJ-popular article gets.
Sorry, you folks get used to communication via IRC, and then use IRC'ish internal speak.... Anyway, I remember the MJ day, and went back and read that thread.
Whatever happened to Domas' idea that, for things already in the cache and about to be invalidated, a newly parsed instance be stored in memcache before invalidating other caches, so that the article is only parsed once?
William Allen Simpson wrote:
Whatever happened to Domas' idea that, for things already in the cache and about to be invalidated, a newly parsed instance be stored in memcache before invalidating other caches, so that the article is only parsed once?
The mentioned Pool Counter is a daemon which makes serializes parsings, so while the first apache is parsing it, the rest wait instead of doing its own parse.
On 11-03-14 05:14 AM, Tim Starling wrote:
On 14/03/11 19:52, Domas Mituzas wrote:
For now I have added a sleep() to the code to limit invalidations to 100 pages per second per job runner process.
Mass invalidations will create MJ issue in the long tail though... Need poolcounter ;-)
That's why Platonides wrote it for us. Now we just have to package it and deploy it.
There was a CPU spike after my change, but that was probably because 100 invalidations per second was still too fast, rather than a Michael Jackson type of problem.
On IRC, Daniel Friesen suggested pushing new HTML into the parser cache from the job queue instead of invalidating. Maybe after we move the parser cache to disk, that will be a good option.
-- Tim Starling
To avoid pushing frequently used entries out, I also thought of the idea of only replacing caches that exist. ie: If it was parser cached, replace the parser cache with a new version, if not, leave it alone so we don't flush frequently used entries with infrequently used ones. Unless cache replacements still flush a lot of frequently used entries that option might have most of the advantages of updating caches from the job queue while avoiding the biggest pitfalls.
There is also the option of trying to distribute these timewise and break them up into batches so there is time for normal operations to re-cache without doing it all at once. Though that project might be a little more involved since it'll depart from the normal operation of the job queue and have jobs that shouldn't be run off the queue right away. I did always love the idea of a job daemon though.
~Daniel Friesen (Dantman, Nadir-Seen-Fire) [http://daniel.friesen.name]
On 15/03/11 02:56, Daniel Friesen wrote:
To avoid pushing frequently used entries out, I also thought of the idea of only replacing caches that exist.
Yes, but since we are going to move the parser cache to disk anyway, I thought it made sense to optimise for that case.
-- Tim Starling
wikitech-l@lists.wikimedia.org
{kind=link}
{kind=link}
{kind=link}