Hi all,
due to a scheduled migration [1] OAuth authorization and management will be
disabled between 21:00–23:00 UTC [2][3[. That means users will not be able
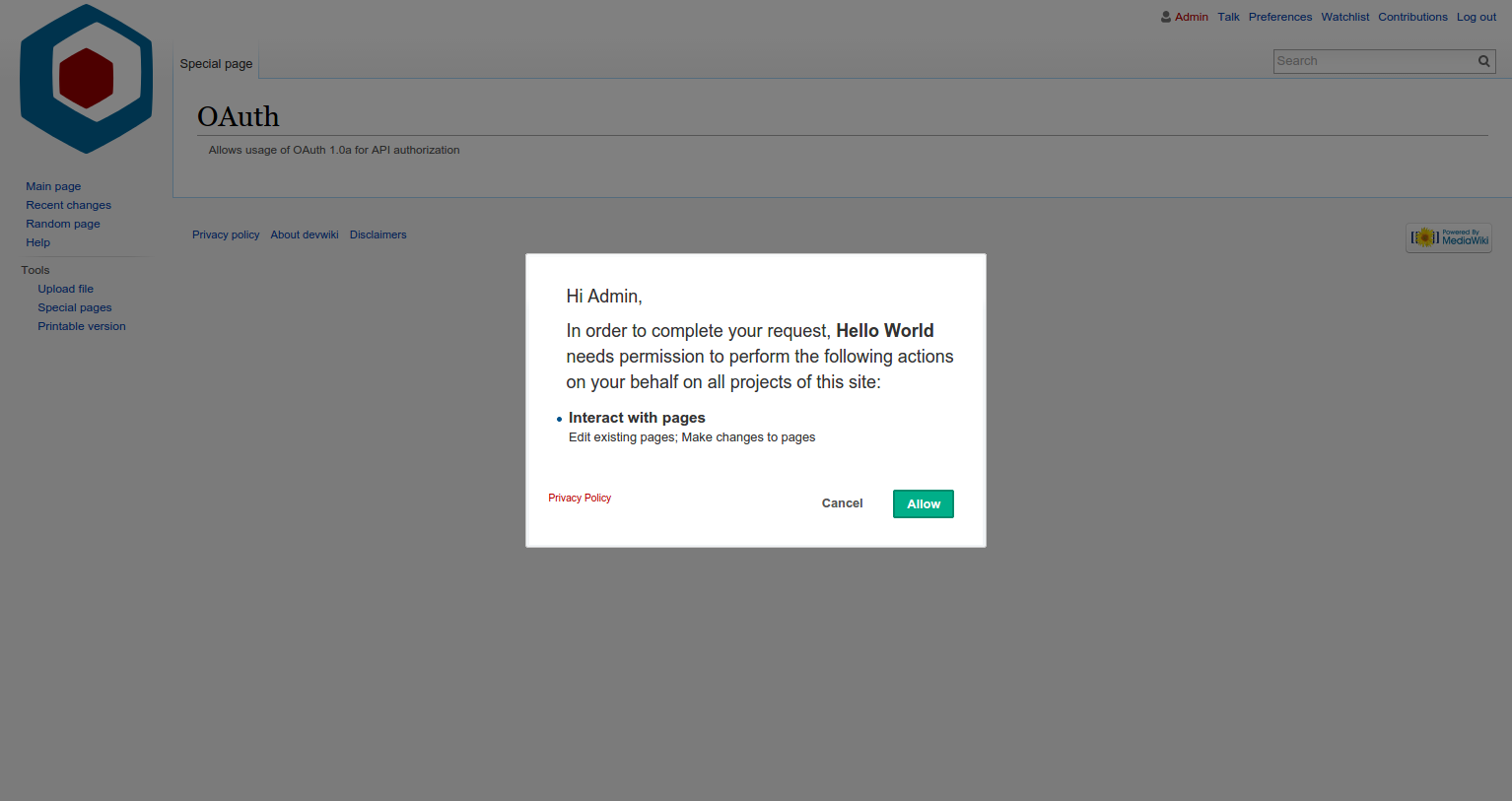
to enable new applications (ie. this dialog [4] will not work)
and developers and OAuth admins won't be able to
propose/approve/disable/etc. consumers. Already authorized applications
should continue to work.
After the migration, the central wiki for OAuth authentication will be Meta
instead of mediawiki.org. This should not have any user impact (except for
OAuth admins and developers who need to use that wiki from then on).
[1] https://phabricator.wikimedia.org/T108648
[2]
http://www.timeanddate.com/worldclock/fixedtime.html?msg=OAuth+maintenance&…
[3] this is a worst case estimate; the actual downtime will probably be a
lot shorter than that.
[4]
https://phab.wmfusercontent.org/file/data/ah4oipxtzpgqx45bnduj/PHID-FILE-yd…
We haven't announced this survey on wikitech-l yet, so if you run a wiki
outside of those run by the WMF, please take the time to fill out the
survey at <http://hexm.de/MWSurvey>. More information about the survey
and its purpose can be found at
<https://www.mediawiki.org/wiki/2015_MediaWiki_User_Survey>.
That said, we received a report (T104010) from the Analytics team today
that most downloads of MediaWiki are coming from China. The report
indicated there were twice as many downloads from China as the U.S. in
June.
I don't know of a good way to reach these users -- I wasn't even aware
of them till today. Through our efforts at outreach so far we've
uncovered a number of private wikis that we wouldn't have been able to
discover otherwise, but I'd like to extend our reach even farther.
Can we add a link to the survey to the top of
https://www.mediawiki.org/wiki/Download until the end of July?
--
Mark A. Hershberger
NicheWork LLC
717-271-1084
Hi all,
as part of the ongoing project for collecting javascript errors [0] we have
been collecting metrics about CORS enabled script loading support; that
project is finished now, here is a short report. After the recent move to
load everything from the same domain [1] enabling CORS is not needed
anymore, but I figured the numbers could still be interesting.
tl;dr version: enabling CORS would probably cause problems in about 0.1% of
our script loads.
== What is CORS enabled script loading? ==
Most people probably know CORS or Cross-Origin Resource Sharing [2][3] as a
way of sending AJAX requests to a different domain. You send a normal AJAX
request, the browser detects that it is going to a different domain than
the website you are on (which could be used for CSRF [4] attacks) and
refuses to return the results of the request unless the target server
permits it by setting certain HTTP headers.
Actually, CORS - as defined by the WHATWG Fetch standard [5] - is more
generic than that: it is a protocol on top of HTTP that can be used to add
extra permissions to any kind of request. One way browsers make use of that
is to provide a "crossorigin" HTML attribute [6], which can be set on
certain elements to get more information about them.
Specifically, using <script crossorigin="anonymous" src="..."></script>
instead of just <script src="..."></script> will mean that the browser uses
a CORS request to fetch the script if it is on a different domain, and
certain restrictions on error information will be lifted.
== Why did we care about it? ==
Browsers provide information about Javascript errors via the onerror event,
which has various interesting uses. Unfortunately, this information is not
available when the error happens in a script that is loaded from a
different domain; we get a nondescript "Script error. line 0" instead.
Fortunately, that limitation can be lifted in modern browsers by fetching
the script via CORS. Unfortunately the CORS specification requires browsers
to threat CORS authorization errors as network errors. In other words, if
one requests a script with crossorigin="anonymous" and the response does
not have the right CORS headers set, the browser will treat that as a 404
error and not run the script at all.
That does not sound like a big deal since we are loading most Javascript
files from our own servers, and can fully control what headers are set, but
we ran into occasional problems in the past when using CORS (MediaViewer
uses CORS-enabled image loading to get access to certain performance
statistics): some people use proxies or firewalls which strip CORS headers
from the responses as some sort of misguided security effort, causing the
request to fail. We wanted to know how many users would be affected by this
if we loaded ResourceLoader scripts via CORS.
== What did we find? ==
For the last few months, we run the measurements on every 1 in 1000
pageloads, by downloading two small script files, one with and one without
CORS. CORS loading failed but normal loading succeeded in 0.16% of the
requests. (Only browser which were feature-detected to suport CORS were
counted.) In 0.12% both failed and in 0.03% the CORS loading failed and the
normal loading succeeded. (Exact queries can be found in [7], the logging
code in [8] and the data in the ImageMetricsCorsSupport schema [9].)
So it seems that there is about 0.15% failure ratio for any script load
(due to shaky connections and other network errors, probably), and enabling
CORS for script loading would roughly double that failure ratio.
The numbers were reasonably stable over time; there was some geographical
variance, with China leading with an 1% CORS failure rate, and all other
countries in the 0-0.5% range.
[0] see
https://www.mediawiki.org/wiki/Requests_for_comment/Server-side_Javascript_…
and https://phabricator.wikimedia.org/project/profile/976/ if you are
interested in that.
[1] https://phabricator.wikimedia.org/T95448
[2] https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
[3] http://www.w3.org/TR/cors/
[4] https://en.wikipedia.org/wiki/Cross-site_request_forgery
[5] https://fetch.spec.whatwg.org/#http-cors-protocol
[6]
https://html.spec.whatwg.org/multipage/infrastructure.html#cors-settings-at…
[7] https://phabricator.wikimedia.org/T507
[8] https://gerrit.wikimedia.org/r/#/c/230982/
[9] https://meta.wikimedia.org/wiki/Schema:ImageMetricsCorsSupport
Hello!
The Search Team in the Discovery Department is implementing a maximum
search query length <https://phabricator.wikimedia.org/T107947>. There are
two main reasons to do this:
1. Extremely long queries are almost always gibberish from things like
malfunctioning scrapers. These queries skew our statistics about the
usefulness of our search. Implementing a limit will reduce the magnitude of
skew.
2. Extremely long queries have a disproportionate impact on performance.
On its own this isn't enough, but considering point 1 above, limiting them
is unlikely to impact any actual users. Implementing a limit will improve
performance.
We've chosen a hard limit of 300 characters. If your query exceeds this,
you will be told that your query exceeds the maximum length. Based on our
analysis of typical query lengths
<https://phabricator.wikimedia.org/T107947#1515387>, this change should
impact almost nobody. If you think you'll be adversely affected, please
reach out to us and we'll work with you to figure something out.
Thanks!
Dan
--
Dan Garry
Lead Product Manager, Discovery
Wikimedia Foundation
tl;dr should OAuth [1] (the system by which external tools can register to
be "Wikimedia applications" and users can grant them the right to act in
their name) rely on community-maintained description pages or profile forms
filled by application authors?
---------------
Hi all,
I would like to request wider input to decide which way Extension:OAuth
should go. An OAuth application needs to provide various pieces of
information (a description; a privacy policy; a link to the author; a link
to the application; links to the source code, developer documentation and
bug tracker; and icons and screenshots). There are two fundamentally
different approaches to do this: either maintain the information as
editable wiki pages and have the software extract it from there; or make
the developer of the application provide the information via some web form
on a Special:* page and store it in the database. Extension description
pages are an example of the first approach; profile pages in pretty much
any non-MediaWiki software are an example of the second one.
Some of the benefits and drawbacks of using wiki pages:
* they require very little development;
* it's a workflow we have a lot of experience with, and have high-quality
tools to support it (templates, editing tools, automated updates etc.);
* the information schema can be extended without the need to update
software / change DB schemas;
* easier to open up editing to anyone since there are mature change
tracking / anti-abuse tools in MediaWiki (but even so, open editing would
be somewhat scary - some fields might have legal strings attached or become
attack vectors);
* limited access control (MediaWiki namespace pages could be used, as they
are e.g. for gadgets, to limit editing of certain information to admins,
but something like "owner can edit own application + OAuth admins can edit
all aplications" is not possible);
* hard to access from the software in a structured way - one could rely on
naming conventions (e.g. the icon is always at File:OAuth-<application
name>-icon.png) or use Wikidata somehow, but both of those sound awkward;
* design/usability/interface options are limited.
Some previous discussion on the issue can be found in T58946 [2] and T60193
[3].
Right now OAuth application descriptions are stored in the database, but in
a very rough form (there is just a name and a plaintext description), so
switching to wiki pages would not be that hard. Once we have a well-refined
system, though, transitiong from one option to the other would be more
painful, so I'd rather have a discussion about it now than a year from now.
Which approach would you prefer?
[1] https://www.mediawiki.org/wiki/Extension:OAuth
[2] https://phabricator.wikimedia.org/T58946
[3] https://phabricator.wikimedia.org/T60193
TL;DR: Join us to discuss Templates, Page Components & editing on Thu, 13
August, 12:45 – 14:00 PDT [0].
Hello all,
Recent discussions, including the pre-Wikimania content brainstorming
[2][3], brought up several important questions about the next steps for
MediaWiki's and particularly Wikimedia's content representation, storage,
change propagation, and caching. Many of those questions directly affect
ongoing work, so it would be good to get more clarity on them soon. To this
end, I am proposing we meet every two weeks & discuss one major area at a
time. I think we have enough topics for four meetings over two months
[2][3], after which we can re-evaluate the approach.
As the first topic, I would like to propose *Templates, Page Components &
editing*. Gradual improvements in this area should let us broaden the
support for different devices, improve the editing experience, and speed up
rendering and updates. There has been a lot of discussion and activity on
this recently, including a talk by C.Scott at Wikimania [4], Jon's
Wikidata-driven infoboxes on the mobile site [5], Marius's Lua-based
infobox programming idea [6], and Wikia's declarative infobox components
[7]. This summary task [8] has a list of related resources.
Concretely, we could try to answer these questions:
- Can we find satisfactory general abstractions for page components
(well-formed content blocks)?
- What are the requirements for editing, RL module / metadata
aggregation, dependency tracking?
- Should we evolve wikitext templates into well-formed page components?
Please join us at:
*Thu, 13 August, 12:45 – 14:00 PDT* [0]
- by joining the BlueJeans conference call [1],
- on IRC, in #wikimedia-meeting, or
- in Room 37 in the WMF office.
See you there,
Gabriel
[0]: http://www.timeanddate.com/worldclock/fixedtime.html?iso=20150813T1945
[1]: https://bluejeans.com/2061103652, via phone +14087407256, meeting id
2061103652
[2]: https://phabricator.wikimedia.org/T99088
[3]: https://etherpad.wikimedia.org/p/Content_platform
[4]:
https://upload.wikimedia.org/wikipedia/commons/0/08/Templates_are_dead!_Lon…
[5]: https://en.m.wikipedia.org/wiki/Albert_Einstein?mobileaction=alpha
[6]: https://www.mediawiki.org/wiki/Extension:Capiunto
[7]: http://community.wikia.com/wiki/Thread:841717,
http://infoboxpreview.appspot.com/
[8]: https://phabricator.wikimedia.org/T105845
What is the recommended path for updating extensions if you are still
using the 1.23.x series? After the update announcement today, I tried
downloading the 1.23 version of each of the extensions that we use from
the Extension Distributor. Each of the downloads appears to be the same
as the old version, suggesting none of the fixes has been backported (or
are not required?). Is there a correct way to keep extensions updated if
you stay with the "long term support release"?
--
Jim Tittsler http://www.OnJapan.net/ GPG: 0x01159DB6
Python Starship http://Starship.Python.net/crew/jwt/
Mailman IRC irc://irc.freenode.net/#mailman
{kind=link}
{kind=link}