DBpedia Databus (alpha version)
The DBpedia Databus is a platform that allows to exchange, curate and access data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API. Data governance stays with the data contributors.
Vision
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done automagically on a central communication system (the bus) and then dispersed again in a decentral network to the consumers and applications.
On the databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improve the data at the source.
Open Data vs. Closed (paid) Data
We have studied the data network for 10 years now and we conclude that organisations with open data are struggling to work together properly, although they could and should, but are hindered by technical and organisational barriers. They duplicate work on the same data. On the other hand, companies selling data can not do so in a scalable way. The loser is the consumer with the choice of inferior open data or buying from a djungle-like market.
Publishing data on the databus
If you are grinding your teeth about how to publish data on the web, you can just use the databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
*
Visibility guarantees, that your citations and reputation goes up
*
Besides a web download, we can also provide a Linked Data interface, SPARQL endpoint, Lookup (autocomplete) or many other means of availability (like AWS or Docker images)
*
Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality
*
You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
Data Sellers
If you are selling data, the databus provides numerous opportunities for you. You can link your offering to the open entities in the databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the databus will be a commodity. We are greatly downing the cost for understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need.
If you are lacking a certain kind of data, we can also scout for it and load it onto the databus.
How the Databus works at the moment
We are still in an initial state, but we already load 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
1.
Acquisition: data is downloaded from the source and logged in
2.
Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation and SHACL)
3.
Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well)
4.
Linking: Links are mainly collected from the sources, cleaned and enriched
5.
IDying: All entities found are given a new Databus ID for tracking
6.
Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative
7.
Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources.
8.
A main knowledge graph fused from all the sources, i.e. a transparent aggregate
9.
For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs.
10.
You can compare all data via a webservice (early prototype, just works for Eiffel Tower): _http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...
We aim for a real-time system, but at the moment we are doing a monthly cycle.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly, nor grow.
On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing), so we can guarantee that legal matters are handled correctly. Otherwise professional use is at own risk.
Current Stats
Download
The databus data is available at _http://downloads.dbpedia.org/databus/_ ordered into three main folders:
*
Data: the data that is loaded on the databus at the moment
*
Global: a folder that contains provenance data and the mappings to the new IDs
*
Fusion: the output of the databus
Most notably you can find:
*
Provenance mapping of the new ids in _global/persistence-core/cluster-iri-provenance-ntriples/_ http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-provenance-ntriples/ and _global/persistence-core/global-ids-ntriples/_ http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntriples/
*
The final fused version for the core: _fusion/core/fused/_ http://downloads.dbpedia.org/databus/fusion/core/fused/
*
A detailed JSON-LD file for data comparison: _fusion/core/json/_ http://downloads.dbpedia.org/databus/fusion/core/json/
*
Complements, i.e. the enriched Dutch DBpedia Version: _fusion/core/nl.dbpedia.org/_ http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/
(Note that the file and folder structure are still subject to change)
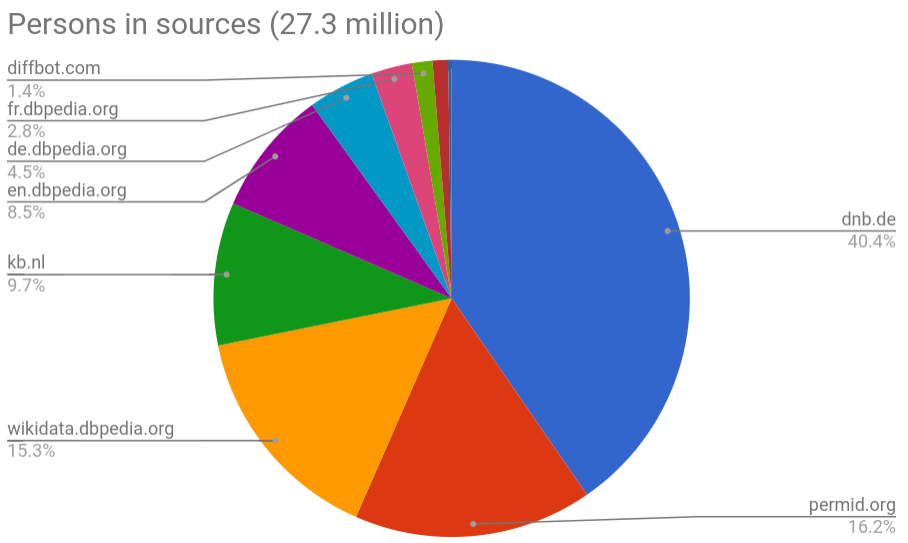
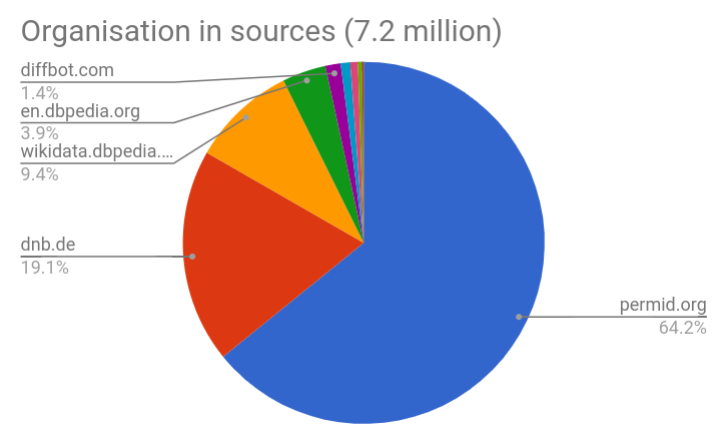
Sources
Glue
Source
Target
Amount
_de.dbpedia.org_ http://de.dbpedia.org/
_www.viaf.org_ http://www.viaf.org/
387,106
_diffbot.com_ http://diffbot.com/
_www.wikidata.org_ http://www.wikidata.org/
516,493
_d-nb.info_ http://d-nb.info/
_viaf.org_ http://viaf.org/
5,382,783
_d-nb.info_ http://d-nb.info/
_dbpedia.org_ http://dbpedia.org/
80,497
_d-nb.info_ http://d-nb.info/
_sws.geonames.org_ http://sws.geonames.org/
50,966
_fr.dbpedia.org_ http://fr.dbpedia.org/
_www.viaf.org_ http://www.viaf.org/
266
_sws.geonames.org_ http://sws.geonames.org/
_dbpedia.org_ http://dbpedia.org/
545,815
_kb.nl_ http://kb.nl/
_viaf.org_ http://viaf.org/
2,607,255
_kb.nl_ http://kb.nl/
_www.wikidata.org_ http://www.wikidata.org/
121,012
_kb.nl_ http://kb.nl/
_dbpedia.org_ http://dbpedia.org/
37,676
_www.wikidata.org_ http://www.wikidata.org/
_https://permid.org_ https://permid.org/
5,133
_wikidata.dbpedia.org_ http://wikidata.dbpedia.org/
_www.wikidata.org_ http://www.wikidata.org/
45,344,233
_wikidata.dbpedia.org_ http://wikidata.dbpedia.org/
_sws.geonames.org_ http://sws.geonames.org/
3,495,358
_wikidata.dbpedia.org_ http://wikidata.dbpedia.org/
_viaf.org_ http://viaf.org/
1,179,550
_wikidata.dbpedia.org_ http://wikidata.dbpedia.org/
_d-nb.info_ http://d-nb.info/
601,665
Plan for the next releases
*
Include more existing data from DBpedia
*
Renew all DBpedia releases in a separate fashion:
o
DBpedia Wikidata is running already: _http://78.46.100.7/wikidata/_
o
Basic extractors like infobox properties and mapping will be active soon
o
Text extraction will take a while
*
Load all data in the comparison tool: _http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...
*
Load all data into a SPARQL endpoint
*
Create a simple open source software that let’s everybody push data on the databus in an automated way
I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely? Are you a DBPedia maintainer?
Sent: Tuesday, May 08, 2018 at 1:29 PM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de To: "Discussion list for the Wikidata project." wikidata@lists.wikimedia.org Subject: [Wikidata] DBpedia Databus (alpha version)
DBpedia Databus (alpha version)
The DBpedia Databus is a platform that allows to exchange, curate and access data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API. Data governance stays with the data contributors.
Vision
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done automagically on a central communication system (the bus) and then dispersed again in a decentral network to the consumers and applications. On the databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improve the data at the source.
Open Data vs. Closed (paid) Data
We have studied the data network for 10 years now and we conclude that organisations with open data are struggling to work together properly, although they could and should, but are hindered by technical and organisational barriers. They duplicate work on the same data. On the other hand, companies selling data can not do so in a scalable way. The loser is the consumer with the choice of inferior open data or buying from a djungle-like market.
Publishing data on the databus
If you are grinding your teeth about how to publish data on the web, you can just use the databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
Visibility guarantees, that your citations and reputation goes up Besides a web download, we can also provide a Linked Data interface, SPARQL endpoint, Lookup (autocomplete) or many other means of availability (like AWS or Docker images) Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
Data Sellers
If you are selling data, the databus provides numerous opportunities for you. You can link your offering to the open entities in the databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the databus will be a commodity. We are greatly downing the cost for understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need. If you are lacking a certain kind of data, we can also scout for it and load it onto the databus.
How the Databus works at the moment
We are still in an initial state, but we already load 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
Acquisition: data is downloaded from the source and logged in Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation and SHACL) Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well) Linking: Links are mainly collected from the sources, cleaned and enriched IDying: All entities found are given a new Databus ID for tracking Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources. A main knowledge graph fused from all the sources, i.e. a transparent aggregate For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs. You can compare all data via a webservice (early prototype, just works for Eiffel Tower): http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...] We aim for a real-time system, but at the moment we are doing a monthly cycle.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly, nor grow. On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing), so we can guarantee that legal matters are handled correctly. Otherwise professional use is at own risk.
Current Stats
Download
The databus data is available at http://downloads.dbpedia.org/databus/%5Bhttp://downloads.dbpedia.org/databus...] ordered into three main folders:
Data: the data that is loaded on the databus at the moment Global: a folder that contains provenance data and the mappings to the new IDs Fusion: the output of the databus Most notably you can find:
Provenance mapping of the new ids in global/persistence-core/cluster-iri-provenance-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-pro...] and global/persistence-core/global-ids-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntri...] The final fused version for the core: fusion/core/fused/[http://downloads.dbpedia.org/databus/fusion/core/fused/] A detailed JSON-LD file for data comparison: fusion/core/json/[http://downloads.dbpedia.org/databus/fusion/core/json/] Complements, i.e. the enriched Dutch DBpedia Version: fusion/core/nl.dbpedia.org/[http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/] (Note that the file and folder structure are still subject to change)
Sources
Glue
Source Target Amount
de.dbpedia.org[http://de.dbpedia.org/] www.viaf.org[http://www.viaf.org/] 387,106
diffbot.com[http://diffbot.com/] www.wikidata.org[http://www.wikidata.org/] 516,493
d-nb.info[http://d-nb.info/] viaf.org[http://viaf.org/] 5,382,783
d-nb.info[http://d-nb.info/] dbpedia.org[http://dbpedia.org/] 80,497
d-nb.info[http://d-nb.info/] sws.geonames.org[http://sws.geonames.org/] 50,966
fr.dbpedia.org[http://fr.dbpedia.org/] www.viaf.org[http://www.viaf.org/] 266
sws.geonames.org[http://sws.geonames.org/] dbpedia.org[http://dbpedia.org/] 545,815
kb.nl[http://kb.nl/] viaf.org[http://viaf.org/] 2,607,255
kb.nl[http://kb.nl/] www.wikidata.org[http://www.wikidata.org/] 121,012
kb.nl[http://kb.nl/] dbpedia.org[http://dbpedia.org/] 37,676
www.wikidata.org[http://www.wikidata.org/] https://permid.org%5Bhttps://permid.org/] 5,133
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] www.wikidata.org[http://www.wikidata.org/] 45,344,233
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] sws.geonames.org[http://sws.geonames.org/] 3,495,358
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] viaf.org[http://viaf.org/] 1,179,550
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] d-nb.info[http://d-nb.info/] 601,665
Plan for the next releases
Include more existing data from DBpedia Renew all DBpedia releases in a separate fashion:
DBpedia Wikidata is running already: http://78.46.100.7/wikidata/%5Bhttp://78.46.100.7/wikidata/] Basic extractors like infobox properties and mapping will be active soon Text extraction will take a while Load all data in the comparison tool: http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...] Load all data into a SPARQL endpoint Create a simple open source software that let’s everybody push data on the databus in an automated way _______________________________________________ Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata%5Bhttps://lists.wikime...]
Hi Laura,
I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely?
a valid question. DBpedia is quite decentralised and hard to understand in its entirety. So actually some parts are improved and others will be replaced eventually (also an improvement, hopefully).
The main improvement here is that, we don't have large monolithic releases that take forever anymore. Especially the language chapters and also the professional community can work better with the "platform" in terms of turnaround, effective contribution and also incentives for contribution. Another thing that will hopefully improve is that we can more sustainably maintain contributions and add-ons, which were formerly lost between releases. So the structure and processes will be clearer.
The DBpedia in the "main endpoint" will still be there, but in a way that nl.dbpedia.org/sparql or wikidata.dbpedia.org/sparql is there. The new hosted service will be more a knowledge graph of knowledge graph, where you can get either all information in a fused way or you can quickly jump to the sources, compare and do improvements there. Projects and organisations can also upload their data to query it there themselves or share it with others and persist it. Companies can sell or advertise their data. The core consists of the Wikipedia/Wikidata data and we hope to be able to improve it and also send contributors and contributions back to the Wikiverse.
Are you a DBPedia maintainer?
Yes, I took it as my task to talk to everybody in the community over the last year and draft/aggregate the new strategy and innovate.
All the best, Sebastian
On 08.05.2018 13:42, Laura Morales wrote:
I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely? Are you a DBPedia maintainer?
Sent: Tuesday, May 08, 2018 at 1:29 PM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de To: "Discussion list for the Wikidata project." wikidata@lists.wikimedia.org Subject: [Wikidata] DBpedia Databus (alpha version)
DBpedia Databus (alpha version)
The DBpedia Databus is a platform that allows to exchange, curate and access data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API. Data governance stays with the data contributors.
Vision
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done automagically on a central communication system (the bus) and then dispersed again in a decentral network to the consumers and applications. On the databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improve the data at the source.
Open Data vs. Closed (paid) Data
We have studied the data network for 10 years now and we conclude that organisations with open data are struggling to work together properly, although they could and should, but are hindered by technical and organisational barriers. They duplicate work on the same data. On the other hand, companies selling data can not do so in a scalable way. The loser is the consumer with the choice of inferior open data or buying from a djungle-like market.
Publishing data on the databus
If you are grinding your teeth about how to publish data on the web, you can just use the databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
Visibility guarantees, that your citations and reputation goes up Besides a web download, we can also provide a Linked Data interface, SPARQL endpoint, Lookup (autocomplete) or many other means of availability (like AWS or Docker images) Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
Data Sellers
If you are selling data, the databus provides numerous opportunities for you. You can link your offering to the open entities in the databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the databus will be a commodity. We are greatly downing the cost for understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need. If you are lacking a certain kind of data, we can also scout for it and load it onto the databus.
How the Databus works at the moment
We are still in an initial state, but we already load 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
Acquisition: data is downloaded from the source and logged in Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation and SHACL) Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well) Linking: Links are mainly collected from the sources, cleaned and enriched IDying: All entities found are given a new Databus ID for tracking Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources. A main knowledge graph fused from all the sources, i.e. a transparent aggregate For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs. You can compare all data via a webservice (early prototype, just works for Eiffel Tower): http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...]
We aim for a real-time system, but at the moment we are doing a monthly cycle.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly, nor grow. On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing), so we can guarantee that legal matters are handled correctly. Otherwise professional use is at own risk.
Current Stats
Download
The databus data is available at http://downloads.dbpedia.org/databus/%5Bhttp://downloads.dbpedia.org/databus...] ordered into three main folders:
Data: the data that is loaded on the databus at the moment Global: a folder that contains provenance data and the mappings to the new IDs Fusion: the output of the databus
Most notably you can find:
Provenance mapping of the new ids in global/persistence-core/cluster-iri-provenance-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-pro...] and global/persistence-core/global-ids-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntri...] The final fused version for the core: fusion/core/fused/[http://downloads.dbpedia.org/databus/fusion/core/fused/] A detailed JSON-LD file for data comparison: fusion/core/json/[http://downloads.dbpedia.org/databus/fusion/core/json/] Complements, i.e. the enriched Dutch DBpedia Version: fusion/core/nl.dbpedia.org/[http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/]
(Note that the file and folder structure are still subject to change)
Sources
Glue
Source Target Amount
de.dbpedia.org[http://de.dbpedia.org/] www.viaf.org[http://www.viaf.org/] 387,106
diffbot.com[http://diffbot.com/] www.wikidata.org[http://www.wikidata.org/] 516,493
d-nb.info[http://d-nb.info/] viaf.org[http://viaf.org/] 5,382,783
d-nb.info[http://d-nb.info/] dbpedia.org[http://dbpedia.org/] 80,497
d-nb.info[http://d-nb.info/] sws.geonames.org[http://sws.geonames.org/] 50,966
fr.dbpedia.org[http://fr.dbpedia.org/] www.viaf.org[http://www.viaf.org/] 266
sws.geonames.org[http://sws.geonames.org/] dbpedia.org[http://dbpedia.org/] 545,815
kb.nl[http://kb.nl/] viaf.org[http://viaf.org/] 2,607,255
kb.nl[http://kb.nl/] www.wikidata.org[http://www.wikidata.org/] 121,012
kb.nl[http://kb.nl/] dbpedia.org[http://dbpedia.org/] 37,676
www.wikidata.org[http://www.wikidata.org/] https://permid.org%5Bhttps://permid.org/] 5,133
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] www.wikidata.org[http://www.wikidata.org/] 45,344,233
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] sws.geonames.org[http://sws.geonames.org/] 3,495,358
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] viaf.org[http://viaf.org/] 1,179,550
wikidata.dbpedia.org[http://wikidata.dbpedia.org/] d-nb.info[http://d-nb.info/] 601,665
Plan for the next releases
Include more existing data from DBpedia Renew all DBpedia releases in a separate fashion:
DBpedia Wikidata is running already: http://78.46.100.7/wikidata/%5Bhttp://78.46.100.7/wikidata/] Basic extractors like infobox properties and mapping will be active soon Text extraction will take a while Load all data in the comparison tool: http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...] Load all data into a SPARQL endpoint Create a simple open source software that let’s everybody push data on the databus in an automated way
_______________________________________________ Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata%5Bhttps://lists.wikime...]
Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata
So, in short, DBPedia is turning into a business with a "community edition + enterprise edition" kind of model?
Sent: Tuesday, May 08, 2018 at 2:29 PM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de To: "Discussion list for the Wikidata project" wikidata@lists.wikimedia.org, "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
Hi Laura, I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely? a valid question. DBpedia is quite decentralised and hard to understand in its entirety. So actually some parts are improved and others will be replaced eventually (also an improvement, hopefully). The main improvement here is that, we don't have large monolithic releases that take forever anymore. Especially the language chapters and also the professional community can work better with the "platform" in terms of turnaround, effective contribution and also incentives for contribution. Another thing that will hopefully improve is that we can more sustainably maintain contributions and add-ons, which were formerly lost between releases. So the structure and processes will be clearer. The DBpedia in the "main endpoint" will still be there, but in a way that nl.dbpedia.org/sparql or wikidata.dbpedia.org/sparql is there. The new hosted service will be more a knowledge graph of knowledge graph, where you can get either all information in a fused way or you can quickly jump to the sources, compare and do improvements there. Projects and organisations can also upload their data to query it there themselves or share it with others and persist it. Companies can sell or advertise their data. The core consists of the Wikipedia/Wikidata data and we hope to be able to improve it and also send contributors and contributions back to the Wikiverse. Are you a DBPedia maintainer? Yes, I took it as my task to talk to everybody in the community over the last year and draft/aggregate the new strategy and innovate.
All the best, Sebastian
On 08.05.2018 13:42, Laura Morales wrote: I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely? Are you a DBPedia maintainer?
Sent: Tuesday, May 08, 2018 at 1:29 PM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de[mailto:hellmann@informatik.uni-leipzig.de] To: "Discussion list for the Wikidata project." wikidata@lists.wikimedia.org[mailto:wikidata@lists.wikimedia.org] Subject: [Wikidata] DBpedia Databus (alpha version)
DBpedia Databus (alpha version)
The DBpedia Databus is a platform that allows to exchange, curate and access data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API. Data governance stays with the data contributors.
Vision
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done automagically on a central communication system (the bus) and then dispersed again in a decentral network to the consumers and applications. On the databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improve the data at the source.
Open Data vs. Closed (paid) Data
We have studied the data network for 10 years now and we conclude that organisations with open data are struggling to work together properly, although they could and should, but are hindered by technical and organisational barriers. They duplicate work on the same data. On the other hand, companies selling data can not do so in a scalable way. The loser is the consumer with the choice of inferior open data or buying from a djungle-like market.
Publishing data on the databus
If you are grinding your teeth about how to publish data on the web, you can just use the databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
Visibility guarantees, that your citations and reputation goes up Besides a web download, we can also provide a Linked Data interface, SPARQL endpoint, Lookup (autocomplete) or many other means of availability (like AWS or Docker images) Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
Data Sellers
If you are selling data, the databus provides numerous opportunities for you. You can link your offering to the open entities in the databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the databus will be a commodity. We are greatly downing the cost for understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need. If you are lacking a certain kind of data, we can also scout for it and load it onto the databus.
How the Databus works at the moment
We are still in an initial state, but we already load 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
Acquisition: data is downloaded from the source and logged in Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation and SHACL) Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well) Linking: Links are mainly collected from the sources, cleaned and enriched IDying: All entities found are given a new Databus ID for tracking Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources. A main knowledge graph fused from all the sources, i.e. a transparent aggregate For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs. You can compare all data via a webservice (early prototype, just works for Eiffel Tower): http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...]] We aim for a real-time system, but at the moment we are doing a monthly cycle.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly, nor grow. On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing), so we can guarantee that legal matters are handled correctly. Otherwise professional use is at own risk.
Current Stats
Download
The databus data is available at http://downloads.dbpedia.org/databus/%5Bhttp://downloads.dbpedia.org/databus...]] ordered into three main folders:
Data: the data that is loaded on the databus at the moment Global: a folder that contains provenance data and the mappings to the new IDs Fusion: the output of the databus Most notably you can find:
Provenance mapping of the new ids in global/persistence-core/cluster-iri-provenance-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-pro...]] and global/persistence-core/global-ids-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntri...]] The final fused version for the core: fusion/core/fused/[http://downloads.dbpedia.org/databus/fusion/core/fused/%5Bhttp://downloads.d...]] A detailed JSON-LD file for data comparison: fusion/core/json/[http://downloads.dbpedia.org/databus/fusion/core/json/%5Bhttp://downloads.db...]] Complements, i.e. the enriched Dutch DBpedia Version: fusion/core/nl.dbpedia.org/[http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/%5Bhttp://do...]] (Note that the file and folder structure are still subject to change)
Sources
Glue
Source Target Amount
de.dbpedia.org[http://de.dbpedia.org/%5Bhttp://de.dbpedia.org/%5D%5Dwww.viaf.org%5Bhttp://w...]] 387,106
diffbot.com[http://diffbot.com/%5Bhttp://diffbot.com/%5D%5Dwww.wikidata.org%5Bhttp://www...]] 516,493
d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] viaf.org[http://viaf.org/%5Bhttp://viaf.org/]] 5,382,783
d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] dbpedia.org[http://dbpedia.org/%5Bhttp://dbpedia.org/]] 80,497
d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] sws.geonames.org[http://sws.geonames.org/%5Bhttp://sws.geonames.org/]] 50,966
fr.dbpedia.org[http://fr.dbpedia.org/%5Bhttp://fr.dbpedia.org/%5D%5Dwww.viaf.org%5Bhttp://w...]] 266
sws.geonames.org[http://sws.geonames.org/%5Bhttp://sws.geonames.org/]] dbpedia.org[http://dbpedia.org/%5Bhttp://dbpedia.org/]] 545,815
kb.nl[http://kb.nl/%5Bhttp://kb.nl/]] viaf.org[http://viaf.org/%5Bhttp://viaf.org/]] 2,607,255
kb.nl[http://kb.nl/%5Bhttp://kb.nl/%5D%5Dwww.wikidata.org%5Bhttp://www.wikidata.or...]] 121,012
kb.nl[http://kb.nl/%5Bhttp://kb.nl/]] dbpedia.org[http://dbpedia.org/%5Bhttp://dbpedia.org/]] 37,676 www.wikidata.org[http://www.wikidata.org%5D%5Bhttp://www.wikidata.org/%5Bhttp://www.wikidata....]] 5,133
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/%5D%5Dwww.wikidat...]] 45,344,233
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/]] sws.geonames.org[http://sws.geonames.org/%5Bhttp://sws.geonames.org/]] 3,495,358
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/]] viaf.org[http://viaf.org/%5Bhttp://viaf.org/]] 1,179,550
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/]] d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] 601,665
Plan for the next releases
Include more existing data from DBpedia Renew all DBpedia releases in a separate fashion:
DBpedia Wikidata is running already: http://78.46.100.7/wikidata/%5Bhttp://78.46.100.7/wikidata/%5D%5Bhttp://78.4...]] Basic extractors like infobox properties and mapping will be active soon Text extraction will take a while Load all data in the comparison tool: http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...]] Load all data into a SPARQL endpoint Create a simple open source software that let’s everybody push data on the databus in an automated way _______________________________________________ Wikidata mailing list Wikidata@lists.wikimedia.org[mailto:Wikidata@lists.wikimedia.org] https://lists.wikimedia.org/mailman/listinfo/wikidata%5Bhttps://lists.wikime...]]
_______________________________________________ Wikidata mailing listWikidata@lists.wikimedia.org[mailto:Wikidata@lists.wikimedia.org]https://lists.wikimedia.org/mailman/listinfo/wikidata
-- All the best, Sebastian Hellmann
Director of Knowledge Integration and Linked Data Technologies (KILT) Competence Center at the Institute for Applied Informatics (InfAI) at Leipzig University Executive Director of the DBpedia Association Projects: http://dbpedia.org%5Bhttp://dbpedia.org], http://nlp2rdf.org%5Bhttp://nlp2rdf.org], http://linguistics.okfn.org%5Bhttp://linguistics.okfn.org], https://www.w3.org/community/ld4lt%5Bhttp://www.w3.org/community/ld4lt] Homepage: http://aksw.org/SebastianHellmann%5Bhttp://aksw.org/SebastianHellmann] Research Group: http://aksw.org%5Bhttp://aksw.org]
Hi Laura,
On 08.05.2018 15:30, Laura Morales wrote:
So, in short, DBPedia is turning into a business with a "community edition + enterprise edition" kind of model?
No, definitely not. We were asked by many companies to make an enterprise edition, but we concluded that this would diminish the quality of available open data.
So the core tools are more a GitHub for data, where you can fork, mix, republish. The business model is a https://en.wikipedia.org/wiki/Clearing_house_(finance) where you can do the transactions yourself or pay if you would like the convenience of somebody else doing the work. This is an adaption of business models from open source software.
There is also a vision of producing economic Linked Data. Many bubbles in the LOD cloud have deteriorated a lot, since they have run out of funding for maintenance. In the future, we hope to provide a revenue stream for them via the clearing house mechanisms, i.e. files free, queryable via SPARQL/Linked Data as a paid service.
Also since the data is open, there should be no conflict to synchronize with Wikidata and make Wikidata richer.
All the best, Sebastian
Sent: Tuesday, May 08, 2018 at 2:29 PM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de To: "Discussion list for the Wikidata project" wikidata@lists.wikimedia.org, "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
Hi Laura,
I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely?
a valid question. DBpedia is quite decentralised and hard to understand in its entirety. So actually some parts are improved and others will be replaced eventually (also an improvement, hopefully). The main improvement here is that, we don't have large monolithic releases that take forever anymore. Especially the language chapters and also the professional community can work better with the "platform" in terms of turnaround, effective contribution and also incentives for contribution. Another thing that will hopefully improve is that we can more sustainably maintain contributions and add-ons, which were formerly lost between releases. So the structure and processes will be clearer. The DBpedia in the "main endpoint" will still be there, but in a way that nl.dbpedia.org/sparql or wikidata.dbpedia.org/sparql is there. The new hosted service will be more a knowledge graph of knowledge graph, where you can get either all information in a fused way or you can quickly jump to the sources, compare and do improvements there. Projects and organisations can also upload their data to query it there themselves or share it with others and persist it. Companies can sell or advertise their data. The core consists of the Wikipedia/Wikidata data and we hope to be able to improve it and also send contributors and contributions back to the Wikiverse.
Are you a DBPedia maintainer? Yes, I took it as my task to talk to everybody in the community over the last year and draft/aggregate the new strategy and innovate.
All the best, Sebastian
On 08.05.2018 13:42, Laura Morales wrote: I don't understand, is this just another project built on DBPedia, or a project to replace DBPedia entirely? Are you a DBPedia maintainer?
Sent: Tuesday, May 08, 2018 at 1:29 PM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de[mailto:hellmann@informatik.uni-leipzig.de] To: "Discussion list for the Wikidata project." wikidata@lists.wikimedia.org[mailto:wikidata@lists.wikimedia.org] Subject: [Wikidata] DBpedia Databus (alpha version)
DBpedia Databus (alpha version)
The DBpedia Databus is a platform that allows to exchange, curate and access data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API. Data governance stays with the data contributors.
Vision
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done automagically on a central communication system (the bus) and then dispersed again in a decentral network to the consumers and applications. On the databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improve the data at the source.
Open Data vs. Closed (paid) Data
We have studied the data network for 10 years now and we conclude that organisations with open data are struggling to work together properly, although they could and should, but are hindered by technical and organisational barriers. They duplicate work on the same data. On the other hand, companies selling data can not do so in a scalable way. The loser is the consumer with the choice of inferior open data or buying from a djungle-like market.
Publishing data on the databus
If you are grinding your teeth about how to publish data on the web, you can just use the databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
Visibility guarantees, that your citations and reputation goes up Besides a web download, we can also provide a Linked Data interface, SPARQL endpoint, Lookup (autocomplete) or many other means of availability (like AWS or Docker images) Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
Data Sellers
If you are selling data, the databus provides numerous opportunities for you. You can link your offering to the open entities in the databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the databus will be a commodity. We are greatly downing the cost for understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need. If you are lacking a certain kind of data, we can also scout for it and load it onto the databus.
How the Databus works at the moment
We are still in an initial state, but we already load 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
Acquisition: data is downloaded from the source and logged in Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation and SHACL) Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well) Linking: Links are mainly collected from the sources, cleaned and enriched IDying: All entities found are given a new Databus ID for tracking Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources. A main knowledge graph fused from all the sources, i.e. a transparent aggregate For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs. You can compare all data via a webservice (early prototype, just works for Eiffel Tower): http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...]]
We aim for a real-time system, but at the moment we are doing a monthly cycle.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly, nor grow. On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing), so we can guarantee that legal matters are handled correctly. Otherwise professional use is at own risk.
Current Stats
Download
The databus data is available at http://downloads.dbpedia.org/databus/%5Bhttp://downloads.dbpedia.org/databus...]] ordered into three main folders:
Data: the data that is loaded on the databus at the moment Global: a folder that contains provenance data and the mappings to the new IDs Fusion: the output of the databus
Most notably you can find:
Provenance mapping of the new ids in global/persistence-core/cluster-iri-provenance-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-pro...]] and global/persistence-core/global-ids-ntriples/[http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntri...]] The final fused version for the core: fusion/core/fused/[http://downloads.dbpedia.org/databus/fusion/core/fused/%5Bhttp://downloads.d...]] A detailed JSON-LD file for data comparison: fusion/core/json/[http://downloads.dbpedia.org/databus/fusion/core/json/%5Bhttp://downloads.db...]] Complements, i.e. the enriched Dutch DBpedia Version: fusion/core/nl.dbpedia.org/[http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/%5Bhttp://do...]]
(Note that the file and folder structure are still subject to change)
Sources
Glue
Source Target Amount
de.dbpedia.org[http://de.dbpedia.org/%5Bhttp://de.dbpedia.org/%5D%5Dwww.viaf.org%5Bhttp://w...]] 387,106
diffbot.com[http://diffbot.com/%5Bhttp://diffbot.com/%5D%5Dwww.wikidata.org%5Bhttp://www...]] 516,493
d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] viaf.org[http://viaf.org/%5Bhttp://viaf.org/]] 5,382,783
d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] dbpedia.org[http://dbpedia.org/%5Bhttp://dbpedia.org/]] 80,497
d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] sws.geonames.org[http://sws.geonames.org/%5Bhttp://sws.geonames.org/]] 50,966
fr.dbpedia.org[http://fr.dbpedia.org/%5Bhttp://fr.dbpedia.org/%5D%5Dwww.viaf.org%5Bhttp://w...]] 266
sws.geonames.org[http://sws.geonames.org/%5Bhttp://sws.geonames.org/]] dbpedia.org[http://dbpedia.org/%5Bhttp://dbpedia.org/]] 545,815
kb.nl[http://kb.nl/%5Bhttp://kb.nl/]] viaf.org[http://viaf.org/%5Bhttp://viaf.org/]] 2,607,255
kb.nl[http://kb.nl/%5Bhttp://kb.nl/%5D%5Dwww.wikidata.org%5Bhttp://www.wikidata.or...]] 121,012
kb.nl[http://kb.nl/%5Bhttp://kb.nl/]] dbpedia.org[http://dbpedia.org/%5Bhttp://dbpedia.org/]] 37,676 www.wikidata.org[http://www.wikidata.org%5D%5Bhttp://www.wikidata.org/%5Bhttp://www.wikidata....]] 5,133
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/%5D%5Dwww.wikidat...]] 45,344,233
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/]] sws.geonames.org[http://sws.geonames.org/%5Bhttp://sws.geonames.org/]] 3,495,358
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/]] viaf.org[http://viaf.org/%5Bhttp://viaf.org/]] 1,179,550
wikidata.dbpedia.org[http://wikidata.dbpedia.org/%5Bhttp://wikidata.dbpedia.org/]] d-nb.info[http://d-nb.info/%5Bhttp://d-nb.info/]] 601,665
Plan for the next releases
Include more existing data from DBpedia Renew all DBpedia releases in a separate fashion:
DBpedia Wikidata is running already: http://78.46.100.7/wikidata/%5Bhttp://78.46.100.7/wikidata/%5D%5Bhttp://78.4...]] Basic extractors like infobox properties and mapping will be active soon Text extraction will take a while Load all data in the comparison tool: http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&am...]] Load all data into a SPARQL endpoint Create a simple open source software that let’s everybody push data on the databus in an automated way
_______________________________________________ Wikidata mailing list Wikidata@lists.wikimedia.org[mailto:Wikidata@lists.wikimedia.org] https://lists.wikimedia.org/mailman/listinfo/wikidata%5Bhttps://lists.wikime...]]
Wikidata mailing listWikidata@lists.wikimedia.org[mailto:Wikidata@lists.wikimedia.org]https://lists.wikimedia.org/mailman/listinfo/wikidata
-- All the best, Sebastian Hellmann
Director of Knowledge Integration and Linked Data Technologies (KILT) Competence Center at the Institute for Applied Informatics (InfAI) at Leipzig University Executive Director of the DBpedia Association Projects: http://dbpedia.org%5Bhttp://dbpedia.org], http://nlp2rdf.org%5Bhttp://nlp2rdf.org], http://linguistics.okfn.org%5Bhttp://linguistics.okfn.org], https://www.w3.org/community/ld4lt%5Bhttp://www.w3.org/community/ld4lt] Homepage: http://aksw.org/SebastianHellmann%5Bhttp://aksw.org/SebastianHellmann] Research Group: http://aksw.org%5Bhttp://aksw.org]
So basically...
where you get "compute" heavy (querying SPARQL)... you are going to charge fees for providing that compute heavy query service.
where you are not "compute" heavy (providing download bandwidth to get files) ... you are not going to charge fees.
-Thad
Is this a question for Sebastian, or are you talking on behalf of the project?
Sent: Tuesday, May 08, 2018 at 5:10 PM From: "Thad Guidry" thadguidry@gmail.com To: "Discussion list for the Wikidata project" wikidata@lists.wikimedia.org Cc: "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
So basically...
where you get "compute" heavy (querying SPARQL)... you are going to charge fees for providing that compute heavy query service. where you are not "compute" heavy (providing download bandwidth to get files) ... you are not going to charge fees. -Thad
I am asking Sebastian about the rationale for paid service.
On Tue, May 8, 2018 at 2:47 PM Laura Morales lauretas@mail.com wrote:
Is this a question for Sebastian, or are you talking on behalf of the project?
Sent: Tuesday, May 08, 2018 at 5:10 PM From: "Thad Guidry" thadguidry@gmail.com To: "Discussion list for the Wikidata project" < wikidata@lists.wikimedia.org> Cc: "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
So basically...
where you get "compute" heavy (querying SPARQL)... you are going to charge fees for providing that compute heavy query service. where you are not "compute" heavy (providing download bandwidth to get files) ... you are not going to charge fees. -Thad
Sebastian,
Is there a document/paper that summarizes the rationales, vision, and technical details behind DBpedia's Databus. Also, since a few other companies already tried to recombine and publish structured data in a more principled way before, what is different here?
Cheers. -N.
On Tue, May 8, 2018 at 1:57 PM, Thad Guidry thadguidry@gmail.com wrote:
I am asking Sebastian about the rationale for paid service.
On Tue, May 8, 2018 at 2:47 PM Laura Morales lauretas@mail.com wrote:
Is this a question for Sebastian, or are you talking on behalf of the project?
Sent: Tuesday, May 08, 2018 at 5:10 PM From: "Thad Guidry" thadguidry@gmail.com To: "Discussion list for the Wikidata project" < wikidata@lists.wikimedia.org> Cc: "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
So basically...
where you get "compute" heavy (querying SPARQL)... you are going to charge fees for providing that compute heavy query service. where you are not "compute" heavy (providing download bandwidth to get files) ... you are not going to charge fees. -Thad
Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata
Hi Nicolas, Thad,
On 14.05.2018 22:42, Nicolas Torzec wrote:
Sebastian,
Is there a document/paper that summarizes the rationales, vision, and technical details behind DBpedia's Databus. Also, since a few other companies already tried to recombine and publish structured data in a more principled way before, what is different here?
these are legit questions. If you mention other companies, I would start to wonder which ones exactly. I chatted with Jamie Taylor about Freebase and he agreed (or maybe just wanted to be nice...) that we are solving many aspects which were flawed there. Do you know of any other successful models? I would need to know specifics in order to compare.
We basically took the top of the cream of what was developed over the last years and discussed models that would incentivize open data as well as bringing in the money to maintain open data. The system here is fundamentally different from any approach that copies and aggregates data. I know that nowadays you would hear the sentence "we built a pipeline" in every other presentation. But data is not oil and one way pipelines do not make sources better.
Since we are "alpha" there is no documentation yet, but we are developing the whole system with around 10 organisations at different ends of the databus. The data is available already for download.
So basically...
where you get "compute" heavy (querying SPARQL)... you are going to charge fees for providing that compute heavy query service. where you are not "compute" heavy (providing download bandwidth to get files) ... you are not going to charge fees.
The latest read is the handout for Europeana Tech, which should clarify this point: https://docs.google.com/document/d/1OkHBpvQ0h5Qnifn5XKYVV2fiMjsdaooNg1iqS4rC...
I was more expecting technical questions here, but it seems there is interest in how the economics work. However, this part is not easy to write for me.
All the best, Sebastian
Cheers. -N.
On Tue, May 8, 2018 at 1:57 PM, Thad Guidry <thadguidry@gmail.com mailto:thadguidry@gmail.com> wrote:
I am asking Sebastian about the rationale for paid service. On Tue, May 8, 2018 at 2:47 PM Laura Morales <lauretas@mail.com <mailto:lauretas@mail.com>> wrote: Is this a question for Sebastian, or are you talking on behalf of the project? Sent: Tuesday, May 08, 2018 at 5:10 PM From: "Thad Guidry" <thadguidry@gmail.com <mailto:thadguidry@gmail.com>> To: "Discussion list for the Wikidata project" <wikidata@lists.wikimedia.org <mailto:wikidata@lists.wikimedia.org>> Cc: "Laura Morales" <lauretas@mail.com <mailto:lauretas@mail.com>> Subject: Re: [Wikidata] DBpedia Databus (alpha version) So basically... where you get "compute" heavy (querying SPARQL)... you are going to charge fees for providing that compute heavy query service. where you are not "compute" heavy (providing download bandwidth to get files) ... you are not going to charge fees. -Thad _______________________________________________ Wikidata mailing list Wikidata@lists.wikimedia.org <mailto:Wikidata@lists.wikimedia.org> https://lists.wikimedia.org/mailman/listinfo/wikidata <https://lists.wikimedia.org/mailman/listinfo/wikidata>
Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata
Thanks Sebastian,
But that handout doesn't clarify much about which data will be free....and which data will not be included in free download datasets. I need clear understand of where there will be a paywall...and where there will not be a paywall. I guess your still working on those economics, so I'll wait after the summer and see where things are then.
I'm all for paid services where they offer value. But not for paid services that offer little to no value.
Thanks, -Thad
Thanks Sebastian.
I'm not questioning the vision or technical approach, and I think you should be even more explicit regarding the benefits of the feedback loop for data providers :)
I was mostly wondering about the (data marketplace) business model based.
Back in 2010-2014, several data marketplaces were launched with the idea of leveraging Semantic Web principles and technologies to provide more advanced data capabilities and improve dataset discovery, consumption, publishing, and monetization. The specific company I had in mind was Kasabi, which was built on top of Talis' Semantic Web platform, but there were others. I don't think it worked out very well for them in the long term, mostly because the market was not there at the time.
Here are some references about Kasabi, to illustrate: - http://www.dataversity.net/kasabi-sees-a-business-model-in-rdf-data/ - https://www.slideshare.net/ldodds/kasabi-linked-data-marketplace - http://cloudofdata.com/2012/02/data-market-chat-leigh-dodds-discusses-kasabi... - https://gigaom.com/2012/07/09/kasabi-shuts-down-says-data-marketplace-too-sl...
Best. -N.
On Mon, May 14, 2018 at 3:00 PM, Thad Guidry thadguidry@gmail.com wrote:
Thanks Sebastian,
But that handout doesn't clarify much about which data will be free....and which data will not be included in free download datasets. I need clear understand of where there will be a paywall...and where there will not be a paywall. I guess your still working on those economics, so I'll wait after the summer and see where things are then.
I'm all for paid services where they offer value. But not for paid services that offer little to no value.
Thanks, -Thad
Hi Laura,
to see a small demo, we would need your data, either your foaf profile or other data, ideally publicly downloadable. Automatic upload is currently being implemented, but I can load it manually or you can wait.
At the moment you can see:
http://88.99.242.78:9009/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F4o4XK&...
a data entry where en wikipedia and wikidata have more granular data than the dutch and german national library
http://88.99.242.78:9009/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2Fe6R5&...
(DNB value could actually be imported, although I am not sure if there is a difference, between a source and a reference, i.e. DNB has this statement, but they don't have a reference themselves)
a data entry where the german national library has the best value.
We also made an infobox mockup for the Eiffel Tower for our grant proposal with a sync button next to the Infobox property:
https://meta.wikimedia.org/wiki/Grants_talk:Project/DBpedia/GlobalFactSync#P...
All the best,
Sebastian
On 15.05.2018 06:35, Laura Morales wrote:
I was more expecting technical questions here, but it seems there is interest in how the economics work. However, this part is not easy to write for me.
I'd personally like to test a demo of the Databus. I'd also like to see a complete list of all the graphs that are available.
Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata
You need my data to show me a demo? I don't understand... it doesn't make sense... Don't you think that people would rather not bother with your demo at all, instead of giving their data to you? You should have a public demo with a demo foaf as well, but anyway if you need my foaf file then you can use this:
@prefix rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# . @prefix rdfs: http://www.w3.org/2000/01/rdf-schema# . @prefix foaf: http://xmlns.com/foaf/0.1/ .
http://example.org/LM a foaf:Person ; foaf:name "Laura" ; foaf:mbox mailto:laura@example.org ; foaf:homepage http://example.org/LM ; foaf:nick "Laura" .
Sent: Friday, May 18, 2018 at 12:04 AM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de To: "Discussion list for the Wikidata project" wikidata@lists.wikimedia.org, "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
Hi Laura, to see a small demo, we would need your data, either your foaf profile or other data, ideally publicly downloadable. Automatic upload is currently being implemented, but I can load it manually or you can wait. At the moment you can see: http://88.99.242.78:9009/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F4o4XK&... a data entry where en wikipedia and wikidata have more granular data than the dutch and german national library http://88.99.242.78:9009/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2Fe6R5&...] (DNB value could actually be imported, although I am not sure if there is a difference, between a source and a reference, i.e. DNB has this statement, but they don't have a reference themselves) a data entry where the german national library has the best value. We also made an infobox mockup for the Eiffel Tower for our grant proposal with a sync button next to the Infobox property: https://meta.wikimedia.org/wiki/Grants_talk:Project/DBpedia/GlobalFactSync#P...] All the best, Sebastian On 15.05.2018 06:35, Laura Morales wrote: I was more expecting technical questions here, but it seems there is interest in how the economics work. However, this part is not easy to write for me. I'd personally like to test a demo of the Databus. I'd also like to see a complete list of all the graphs that are available.
_______________________________________________ Wikidata mailing listWikidata@lists.wikimedia.org[mailto:Wikidata@lists.wikimedia.org]https://lists.wikimedia.org/mailman/listinfo/wikidata
-- All the best, Sebastian Hellmann
Director of Knowledge Integration and Linked Data Technologies (KILT) Competence Center at the Institute for Applied Informatics (InfAI) at Leipzig University Executive Director of the DBpedia Association Projects: http://dbpedia.org%5Bhttp://dbpedia.org], http://nlp2rdf.org%5Bhttp://nlp2rdf.org], http://linguistics.okfn.org%5Bhttp://linguistics.okfn.org], https://www.w3.org/community/ld4lt%5Bhttp://www.w3.org/community/ld4lt] Homepage: http://aksw.org/SebastianHellmann%5Bhttp://aksw.org/SebastianHellmann] Research Group: http://aksw.org%5Bhttp://aksw.org]
But the goal is to load and mix public and/or closed data. For organisations this is the normal process, you discuss the requirements, then you do a demo with their data, so they can see the benefits directly.
So we made the demo for the DNB (https://data.dnb.de/opendata/) and the KB (no download, they sent a link via email).
I was suggesting your foaf file, because you might not have a dataset (maybe from some research project?).
I uploaded my foaf file, but I accidently added wrong links, otherwise it would have fused my DBpedia entry with my wikidata and DNB entry.
However, I am unable to load examples, it only works on real data ;) What would be the point? Even I don't know whether this is you: https://www.wikidata.org/wiki/Q21264248
All the best,
Sebastian
On 18.05.2018 10:39, Laura Morales wrote:
You need my data to show me a demo? I don't understand... it doesn't make sense... Don't you think that people would rather not bother with your demo at all, instead of giving their data to you? You should have a public demo with a demo foaf as well, but anyway if you need my foaf file then you can use this:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <http://example.org/LM> a foaf:Person ; foaf:name "Laura" ; foaf:mbox <mailto:laura@example.org> ; foaf:homepage <http://example.org/LM> ; foaf:nick "Laura" .Sent: Friday, May 18, 2018 at 12:04 AM From: "Sebastian Hellmann" hellmann@informatik.uni-leipzig.de To: "Discussion list for the Wikidata project" wikidata@lists.wikimedia.org, "Laura Morales" lauretas@mail.com Subject: Re: [Wikidata] DBpedia Databus (alpha version)
Hi Laura, to see a small demo, we would need your data, either your foaf profile or other data, ideally publicly downloadable. Automatic upload is currently being implemented, but I can load it manually or you can wait. At the moment you can see: http://88.99.242.78:9009/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F4o4XK&... a data entry where en wikipedia and wikidata have more granular data than the dutch and german national library http://88.99.242.78:9009/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2Fe6R5&...] (DNB value could actually be imported, although I am not sure if there is a difference, between a source and a reference, i.e. DNB has this statement, but they don't have a reference themselves) a data entry where the german national library has the best value. We also made an infobox mockup for the Eiffel Tower for our grant proposal with a sync button next to the Infobox property: https://meta.wikimedia.org/wiki/Grants_talk:Project/DBpedia/GlobalFactSync#P...] All the best, Sebastian
On 15.05.2018 06:35, Laura Morales wrote: I was more expecting technical questions here, but it seems there is interest in how the economics work. However, this part is not easy to write for me. I'd personally like to test a demo of the Databus. I'd also like to see a complete list of all the graphs that are available.
Wikidata mailing listWikidata@lists.wikimedia.org[mailto:Wikidata@lists.wikimedia.org]https://lists.wikimedia.org/mailman/listinfo/wikidata
-- All the best, Sebastian Hellmann
Director of Knowledge Integration and Linked Data Technologies (KILT) Competence Center at the Institute for Applied Informatics (InfAI) at Leipzig University Executive Director of the DBpedia Association Projects: http://dbpedia.org%5Bhttp://dbpedia.org], http://nlp2rdf.org%5Bhttp://nlp2rdf.org], http://linguistics.okfn.org%5Bhttp://linguistics.okfn.org], https://www.w3.org/community/ld4lt%5Bhttp://www.w3.org/community/ld4lt] Homepage: http://aksw.org/SebastianHellmann%5Bhttp://aksw.org/SebastianHellmann] Research Group: http://aksw.org%5Bhttp://aksw.org]
Sebastian Hellmann, 08/05/2018 14:29:
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done
Sounds like Wikidata!
automagically
Except this. There is always some market for pixie dust.
Federico
Hoi, We do not provide useful operations like versioning, cleaning, transformation at Wikidata. We do not compare we do not curate at Wikidata.
So when somewhere else they make it their priority and do a better job at it, rejoice, don't mock. The GREAT thing about DBpedia that they *are *willing to collaborate. Thanks, GerardM
On 15 May 2018 at 07:51, Federico Leva (Nemo) nemowiki@gmail.com wrote:
Sebastian Hellmann, 08/05/2018 14:29:
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done
Sounds like Wikidata!
automagically
Except this. There is always some market for pixie dust.
Federico
Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata
Hi GerardM and Nemo,
it is kind of ok, what Nemo said, because the comparison to pixie dust holds.
We are trying to decentralize a lot, which makes everything seem very vague. Probably the same with Tim Berners-Lee's new project: https://solid.mit.edu/
At first glance they offer the same features as Facebook and Twitter, which makes it hard to believe that they will be successful, the trick is here to provide the right incentives and usefulness, which will make the network effect.
The main problem I see is that data quality follows the pareto-distribution. The more data you have and the better the quality, the harder it gets to be even better. Test-driven validation only makes it more efficient, but does not beat the pareto-distribution. Networked data can help here to enable reuse and kind of cheat pareto, but not beat it. If you crack the incentives/network issue it is pixie dust and makes the thing fly.
Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is doneSounds like Wikidata!
@Nemo: In my experience you can't really upload data to Wikidata. It comes with a lot of barriers. In the beginning, I understood the argument, that you couldn't load DBpedia or Freebase since there were no references. Now I saw stats that half the statements are not referenced anyhow and another third references Wikipedia. https://docs.google.com/presentation/d/1XX-yzT98fglAfFkHoixOI1XC1uwrS6f0u1xj... So in hindsight, Wikidata could have started out with DBpedia easily and would have a much better start and be much more developed.
DBpedia's properties are directly related to the infobox properties as all data is extracted there, which Wikidata aims to cover as well, so a perfect match. So the Wikidata community spend a lot of time adding data that could have been just uploaded right from the start and focused on the references.
There is also Cunningham's law (the inventor of wikis): "the best way to get the right answer on the internet is not to ask a question; it's to post the wrong answer." So the extraction errors would have been an incentive to fix them...
Now Wikidata is dealing with this https://en.wikipedia.org/wiki/Wikipedia:Wikidata/2018_Infobox_RfC and we are concerned that it will not reach its goal to the fullest. We are still very interested to collaborate on this and contribute where we can.
All the best, Sebastian
On 15.05.2018 07:59, Gerard Meijssen wrote:
Hoi, We do not provide useful operations like versioning, cleaning, transformation at Wikidata. We do not compare we do not curate at Wikidata.
So when somewhere else they make it their priority and do a better job at it, rejoice, don't mock. The GREAT thing about DBpedia that they /are /willing to collaborate. Thanks, GerardM
On 15 May 2018 at 07:51, Federico Leva (Nemo) <nemowiki@gmail.com mailto:nemowiki@gmail.com> wrote:
Sebastian Hellmann, 08/05/2018 14:29: Working with data is hard and repetitive. We envision a hub, where everybody can upload data and then useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting is done Sounds like Wikidata! automagically Except this. There is always some market for pixie dust. Federico _______________________________________________ Wikidata mailing list Wikidata@lists.wikimedia.org <mailto:Wikidata@lists.wikimedia.org> https://lists.wikimedia.org/mailman/listinfo/wikidata <https://lists.wikimedia.org/mailman/listinfo/wikidata>
Wikidata mailing list Wikidata@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wikidata
{kind=link}
{kind=link}