Also remember that barnstars and PUAs existed before Wikilove and continue to be awarded without using Wikilove.
Pine
Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
I just replicated this analysis. I think you might have made some mistakes.
I took a random sample of non-redirect articles from English Wikipedia and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).
I get a pearson correlation coef of *0.9514766*.
See the attached scatter plot including a linear regression line. See also the regress output below.
Call: lm(formula = page_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Fri, Aug 2, 2013 at 12:24 PM, Floeck, Fabian (AIFB) < fabian.floeck@kit.edu> wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Aaron,
this seems kind of redundant as I already agreed that there is an overall high correlation and you posted this (almost) identical analysis 7 months ago. I don't know if you missed my later emails on the topic, but I already wrote that this "mistake" as you repeatedly put it, was a result of the selective sampling between 5000 and 6000 bytes. Hence, as I already said, my initial observations cannot be transferred to the general population of articles.
Not surprising and congruent with Aarons results, I also get a high linear correlation of 0.96 (random sample of 5000 articles) outside the 5800-6000 sample even if I filter out Disamb articles.
But, as I as well explained, there seem to be some indicators that in smaller size articles, this correlation is not as strong.
I split up the random 5000 article sample I posted last time at the median (3709 bytes) into two parts, each 2500 articles big. For the "higher byte size" part (>3709 bytes) the correlation is 0.964 For the "lesser byte size" part (<3710 bytes ) the correlation is only 0.295
You will of course not see that in your example if you just take all data (of all article sizes) and draw a straight regression line through them. The "blob" on the bottom left might need some further investigation. Maybe you could look at only articles under 5000, 3000, 1000 bytes and see if the correlation changes somehow. My guess is it will be less strong.
BTW: did you try to fit nonlinear models? I did not, and one reason for the bad fit in the lesser size articles could also be that there's a high correlation but not a linear one.
Best,
Fabian
On 04.08.2013, at 11:43, Aaron Halfaker <aaron.halfaker@gmail.commailto:aaron.halfaker@gmail.com> wrote:
I just replicated this analysis. I think you might have made some mistakes.
I took a random sample of non-redirect articles from English Wikipedia and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).
I get a pearson correlation coef of 0.9514766.
See the attached scatter plot including a linear regression line. See also the regress output below.
Call: lm(formula = page_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Fri, Aug 2, 2013 at 12:24 PM, Floeck, Fabian (AIFB) <fabian.floeck@kit.edumailto:fabian.floeck@kit.edu> wrote: Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edumailto:fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ckhttp://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
_______________________________________________ Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.orgmailto:Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<bytes.content_length.scatter.png><ATT00001.c>
-- Dipl.-Medwiss. Fabian Flöck Research Associate
Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: floeck@kit.edumailto:floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Hi Fabian,
I think that the primary reason that articles with smaller byte counts show less consistency is due to templates. A lot of stubs and starts are created with a collection of templates that consume few bytes of wikitext, but balloon into lots of HTML/content. Regardless, there doesn't seem to be much cause for concern, so I saw the issue as resolved.
FWIW, I originally showed up in this conversation because I was skeptical of your initial conclusion: "size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article". Now that we've worked out the strong correlation between wikitext length and readable content length for nearly all articles, I have little interest in looking into the data further.
-Aaron
On Sat, Mar 15, 2014 at 12:47 PM, Floeck, Fabian (AIFB) < fabian.floeck@kit.edu> wrote:
Aaron,
this seems kind of redundant as I already agreed that there is an overall high correlation and you posted this (almost) identical analysis 7 months ago. I don't know if you missed my later emails on the topic, but I already wrote that this "mistake" as you repeatedly put it, was a result of the selective sampling between 5000 and 6000 bytes. Hence, as I already said, my initial observations cannot be transferred to the general population of articles.
Not surprising and congruent with Aarons results, I also get a high linear correlation of 0.96 (random sample of 5000 articles) outside the 5800-6000 sample even if I filter out Disamb articles.
But, as I as well explained, there seem to be some indicators that in smaller size articles, this correlation is not as strong.
I split up the random 5000 article sample I posted last time at the median (3709 bytes) into two parts, each 2500 articles big. For the "higher byte size" part (>3709 bytes) the correlation is 0.964 For the "lesser byte size" part (<3710 bytes ) the correlation is only 0.295
You will of course not see that in your example if you just take all data (of all article sizes) and draw a straight regression line through them. The "blob" on the bottom left might need some further investigation. Maybe you could look at only articles under 5000, 3000, 1000 bytes and see if the correlation changes somehow. My guess is it will be less strong.
BTW: did you try to fit nonlinear models? I did not, and one reason for the bad fit in the lesser size articles could also be that there's a high correlation but not a linear one.
Best,
Fabian
On 04.08.2013, at 11:43, Aaron Halfaker aaron.halfaker@gmail.com wrote:
I just replicated this analysis. I think you might have made some mistakes.
I took a random sample of non-redirect articles from English Wikipedia and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).
I get a pearson correlation coef of *0.9514766*.
See the attached scatter plot including a linear regression line. See also the regress output below.
Call: lm(formula = page_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Fri, Aug 2, 2013 at 12:24 PM, Floeck, Fabian (AIFB) < fabian.floeck@kit.edu> wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT - University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<bytes.content_length.scatter.png><ATT00001.c>
--
Dipl.-Medwiss. Fabian Flöck Research Associate
Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: floeck@kit.edu
WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT - University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Hi, Aaron, I tend to agree with your conclusion, and personally have little interest in the relationship between actual size and readable size. But from technical point of view, I guess you should plot your scatter plot in log-log scale and also calculate the correlation between the logarithm of the variables. The sizes are not normally distributed but log-normally [1], and linear statistics on heavy-tailed distributions are usually spurious.
[1] http://www.plosone.org/article/fetchObject.action?uri=info:doi/10.1371/journ...
Take care,
Taha
On 15 Mar 2014 18:21, "Aaron Halfaker" aaron.halfaker@gmail.com wrote:
Hi Fabian,
I think that the primary reason that articles with smaller byte counts show less consistency is due to templates. A lot of stubs and starts are created with a collection of templates that consume few bytes of wikitext, but balloon into lots of HTML/content. Regardless, there doesn't seem to be much cause for concern, so I saw the issue as resolved.
FWIW, I originally showed up in this conversation because I was skeptical of your initial conclusion: "size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article". Now that we've worked out the strong correlation between wikitext length and readable content length for nearly all articles, I have little interest in looking into the data further.
-Aaron
On Sat, Mar 15, 2014 at 12:47 PM, Floeck, Fabian (AIFB) < fabian.floeck@kit.edu> wrote:
Aaron,
this seems kind of redundant as I already agreed that there is an overall high correlation and you posted this (almost) identical analysis 7 months ago. I don't know if you missed my later emails on the topic, but I already wrote that this "mistake" as you repeatedly put it, was a result of the selective sampling between 5000 and 6000 bytes. Hence, as I already said, my initial observations cannot be transferred to the general population of articles.
Not surprising and congruent with Aarons results, I also get a high linear correlation of 0.96 (random sample of 5000 articles) outside the 5800-6000 sample even if I filter out Disamb articles.
But, as I as well explained, there seem to be some indicators that in smaller size articles, this correlation is not as strong.
I split up the random 5000 article sample I posted last time at the median (3709 bytes) into two parts, each 2500 articles big. For the "higher byte size" part (>3709 bytes) the correlation is 0.964 For the "lesser byte size" part (<3710 bytes ) the correlation is only 0.295
You will of course not see that in your example if you just take all data (of all article sizes) and draw a straight regression line through them. The "blob" on the bottom left might need some further investigation. Maybe you could look at only articles under 5000, 3000, 1000 bytes and see if the correlation changes somehow. My guess is it will be less strong.
BTW: did you try to fit nonlinear models? I did not, and one reason for the bad fit in the lesser size articles could also be that there's a high correlation but not a linear one.
Best,
Fabian
On 04.08.2013, at 11:43, Aaron Halfaker aaron.halfaker@gmail.com wrote:
I just replicated this analysis. I think you might have made some mistakes.
I took a random sample of non-redirect articles from English Wikipedia and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).
I get a pearson correlation coef of *0.9514766*.
See the attached scatter plot including a linear regression line. See also the regress output below.
Call: lm(formula = page_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Fri, Aug 2, 2013 at 12:24 PM, Floeck, Fabian (AIFB) < fabian.floeck@kit.edu> wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT - University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<bytes.content_length.scatter.png><ATT00001.c>
--
Dipl.-Medwiss. Fabian Flöck Research Associate
Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: floeck@kit.edu
WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT - University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Hi Fabian,
That's interesting. When you say you stripped out the html did you also strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of referencing , broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.edu wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
(note that I posted this yesterday, but the message bounced due to the attached scatter plot. I just uploaded the plot to commons and re-sent)
I just replicated this analysis. I think you might have made some mistakes.
I took a random sample of non-redirect articles from English Wikipedia and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).
I get a pearson correlation coef of *0.9514766*.
See the scatter plot including a linear regression linehttp://commons.wikimedia.org/wiki/File:Bytes.content_length.scatter.correlation.enwiki.png. See also the regress output below.
Call: lm(formula = byte_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers < werespielchequers@gmail.com> wrote:
Hi Fabian,
That's interesting. When you say you stripped out the html did you also strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of referencing , broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.eduwrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of "http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but that's a mere hunch. Anyway, this was not what I was looking for. I wanted to compare really only the readable text you see directly when scrolling through the article. What is another issue is the inclusion of expandable template listings as I mentioned in my first mail. Are the long listings of related articles "main, readable article text"? I suppose not, but we did not filter them out yet.
@Aaron, I'm pretty sure I didn't make a mistake, but before I can answer your mail: What exactly does this content_length API call give you back (I'm not aware of that). Takes the Wikisyntax and strips it of tags and comments? Or the HTML shown in the front-end including all content generated by templates minus all mark-up? Only in the ladder case would this be comparable in any way to what I have done. Please clarify and send me the concrete API call. I don't think your content_length is the length of the readable front-end text as I used it. (On a side note: I'm unsure why you paste the complete results of a linear regression, as a Pearson correlation will perfectly suffice in such a simple bivariate case. They - due to the nature of these statistical methods - of course yield the same results in this case. Or was there any important extra information that I missed in these regression results?).
Best,
Fabian
[1] http://www.crummy.com/software/BeautifulSoup/bs4/doc/ [2] http://en.wikipedia.org/wiki/William_Goldenberg#cite_note-1
On 05.08.2013, at 01:15, Aaron Halfaker aaron.halfaker@gmail.com wrote:
(note that I posted this yesterday, but the message bounced due to the attached scatter plot. I just uploaded the plot to commons and re-sent)
I just replicated this analysis. I think you might have made some mistakes.
I took a random sample of non-redirect articles from English Wikipedia and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).c
I get a pearson correlation coef of 0,9514766.
See the scatter plot including a linear regression line. See also the regress output below.
Call: lm(formula = byte_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers werespielchequers@gmail.com wrote: Hi Fabian,
That's interesting. When you say you stripped out the html did you also strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of referencing , broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.edu wrote: Hi, to whoever is interested in this (and I hope I didn't just repeat someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles. Results for size in characters (w/ whitespaces) after cleaning the HTML out: Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates make it possible. (See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" -- Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size = 0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<ATT00001.c>
Fabian,
I suspect that your primary mistake is in only looking at pages with byte length between 5800 and 6000 bytes. You've severely limited the range of your regressor and therefor invalidated a set of assumptions for the correlation. If you still don't think that you made a mistake, I suggest that you try a scatter plot like the one that I have provided.
Yes, of course I got the HTML from the API in a similar way as you have. Here's an example that gets the parsed content of the most recent revision to Anachronism (at the time of writing this email): http://en.wikipedia.org/w/api.php?action=query&prop=revisions&revids... Note that I am looking up page content by revisions ID. When I generated my page sample, I also gathered the most recent revision ID from the page history so that when I submitted a follow-up call to get the page's content, I would gather the parsed content at the same point in time.
As for the regression, it's more informative than a simple pearson correlation because it separates the fitted slope (beta coef) from the fitness of the model (R^2). Without the regression, I could not have plotted the fitted line over the scatter plot.
I've uploaded my code to bitbucket for your reference. Specifically, see:
- Page sample queryhttps://bitbucket.org/halfak/byte_length/src/bba477bd1dcd1311498de88e0c0c5186c2cf5631/sql/loader/sample_pages.sql?at=default - API querying codehttps://bitbucket.org/halfak/byte_length/src/bba477bd1dcd1311498de88e0c0c5186c2cf5631/bl/page_content_length.py?at=default (also strips HTML & comments based on regexs) - R code for generating plot and statshttps://bitbucket.org/halfak/byte_length/src/bba477bd1dcd1311498de88e0c0c5186c2cf5631/R/page_content_length/correlation.R?at=default
-Aaron
On Aug 6, 2013 4:17 AM, "Floeck, Fabian (AIFB)" fabian.floeck@kit.edu wrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of " http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but that's a mere hunch. Anyway, this was not what I was looking for. I wanted to compare really only the readable text you see directly when scrolling through the article. What is another issue is the inclusion of expandable template listings as I mentioned in my first mail. Are the long listings of related articles "main, readable article text"? I suppose not, but we did not filter them out yet.
@Aaron, I'm pretty sure I didn't make a mistake, but before I can answer your mail: What exactly does this content_length API call give you back (I'm not aware of that). Takes the Wikisyntax and strips it of tags and comments? Or the HTML shown in the front-end including all content generated by templates minus all mark-up? Only in the ladder case would this be comparable in any way to what I have done. Please clarify and send me the concrete API call. I don't think your content_length is the length of the readable front-end text as I used it. (On a side note: I'm unsure why you paste the complete results of a linear regression, as a Pearson correlation will perfectly suffice in such a simple bivariate case. They - due to the nature of these statistical methods - of course yield the same results in this case. Or was there any important extra information that I missed in these regression results?).
Best,
Fabian
[1] http://www.crummy.com/software/BeautifulSoup/bs4/doc/ [2] http://en.wikipedia.org/wiki/William_Goldenberg#cite_note-1
On 05.08.2013, at 01:15, Aaron Halfaker aaron.halfaker@gmail.com wrote:
(note that I posted this yesterday, but the message bounced due to the
attached scatter plot. I just uploaded the plot to commons and re-sent)
I just replicated this analysis. I think you might have made some
mistakes.
I took a random sample of non-redirect articles from English Wikipedia
and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).c
I get a pearson correlation coef of 0,9514766.
See the scatter plot including a linear regression line. See also the
regress output below.
Call: lm(formula = byte_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers <
werespielchequers@gmail.com> wrote:
Hi Fabian,
That's interesting. When you say you stripped out the html did you also
strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt
text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of referencing
, broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some
correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.edu
wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat
someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much
readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the
actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia
(ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles.
Results for size in characters (w/ whitespaces) after cleaning the HTML
out:
Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates
make it possible.
(See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" --
Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size =
0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate
pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<ATT00001.c>
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Thanks both of you,
I suspect that you two are using very different rules to define "readable characters", and for Aaron to get a close correlation and Fabian not to get any correlation implies to me that Fabian is stripping out the things that are not linked to article size, and that Aaron may be leaving such things in.
For reasons that I'm going to pretend I don't understand, we have some articles with a lot of redundant spaces. Others with so few you'd be correct in thinking that certain editors have been making semiautomated edits to strip out those spaces. I suspect that Fabian's formulae ignores redundant spaces, and that Aaron's does not.
I picked on alt text because it is very patchy across the pedia, but usually consistent at article level. I.e if someone has written a whole paragraph of alt text for one picture they have probably done so for every picture in an article, and conversely many articles will have no alt text at all.
Similarly we have headings, and counterintuitively it is the subheadings that add most non display characters. So an article like Peasant's revolt will have 32 equals signs for its 8 headings, but 60 equal signs for its 10 subheadings. 92 bytes which I suspect one or both of you will have stripped out. The actual display text of course omits all 92 of those bytes, but repeats the content of those headings and subheadings in the contents section.
The size of sections varies enormously from one article to another, and if there are three or fewer sections the contents section is not generated at all. I suspect that the average length of section headings also has quite a bit of variance as it is a stylistic choice. So I would expect that a "display bytes" count that simply stripped out the multiple equal signs would still be a pretty good correlation with article size, but a display bytes count that factored in the complication that headings and subheadings are displayed twice as they are repeated in the contents field, would have another factor drifting it away from a good correlation with raw byte count.
But probably the biggest variance will be over infoboxes, tables, picture captions, hidden comments and the like. If you strip all of them out, including perhaps even the headings, captions and table contents, then you are going to get a very poor fit between article length and readable byte size. But I would be surprised if you could get Fabian's minimum display size of 95 bytes from 6,000 byte articles without having at least one article that consisted almost entirely of tables and which had been reduced to a sentence or two of narrative. So my suspicion is that Aaron's plot is at least including the displayed contents of tables et al whilst Fabian is only measuring the prose sections and completely stripping out anything in a table.
Both approaches of course have their merits, and there are even some editors who were recent edit warring to keep articles they cared about free from clutter by infoboxes and tables.
Regards
Jonathan
On 5 August 2013 21:16, Floeck, Fabian (AIFB) fabian.floeck@kit.edu wrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of " http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but that's a mere hunch. Anyway, this was not what I was looking for. I wanted to compare really only the readable text you see directly when scrolling through the article. What is another issue is the inclusion of expandable template listings as I mentioned in my first mail. Are the long listings of related articles "main, readable article text"? I suppose not, but we did not filter them out yet.
@Aaron, I'm pretty sure I didn't make a mistake, but before I can answer your mail: What exactly does this content_length API call give you back (I'm not aware of that). Takes the Wikisyntax and strips it of tags and comments? Or the HTML shown in the front-end including all content generated by templates minus all mark-up? Only in the ladder case would this be comparable in any way to what I have done. Please clarify and send me the concrete API call. I don't think your content_length is the length of the readable front-end text as I used it. (On a side note: I'm unsure why you paste the complete results of a linear regression, as a Pearson correlation will perfectly suffice in such a simple bivariate case. They - due to the nature of these statistical methods - of course yield the same results in this case. Or was there any important extra information that I missed in these regression results?).
Best,
Fabian
[1] http://www.crummy.com/software/BeautifulSoup/bs4/doc/ [2] http://en.wikipedia.org/wiki/William_Goldenberg#cite_note-1
On 05.08.2013, at 01:15, Aaron Halfaker aaron.halfaker@gmail.com wrote:
(note that I posted this yesterday, but the message bounced due to the
attached scatter plot. I just uploaded the plot to commons and re-sent)
I just replicated this analysis. I think you might have made some
mistakes.
I took a random sample of non-redirect articles from English Wikipedia
and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).c
I get a pearson correlation coef of 0,9514766.
See the scatter plot including a linear regression line. See also the
regress output below.
Call: lm(formula = byte_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers <
werespielchequers@gmail.com> wrote:
Hi Fabian,
That's interesting. When you say you stripped out the html did you also
strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt
text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of referencing
, broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some
correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.edu
wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat
someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much
readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the
actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia
(ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles.
Results for size in characters (w/ whitespaces) after cleaning the HTML
out:
Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates
make it possible.
(See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" --
Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size =
0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate
pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<ATT00001.c>
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
I am removing all HTML tags and comments to include only those characters that are shown on the screen. This will include the content of tables without including the markup contained within. In other words, I stripped anything out of the HTML that looked like a tag (e.g. "<foo>" and "</bar>") or a comment ("<!-- [...] -->") but kept the in-between characters, whitespace and all.
It seems much more reasonable to me that the difference is due to the fact that Fabian's dataset is limited to a very narrow range of bytes. To check this hypothesis, I drew a new sample of pages with byte length between 5800 and 6000.
The pearson correlation that I found for that sample is* 0.06466406. *This corresponds nicely to the poor correlation that Fabian found. * * I've update the plot[1] to show the difference visually.
-Aaron
1. http://commons.wikimedia.org/wiki/File:Bytes.content_length.scatter.correlat...
On Tue, Aug 6, 2013 at 6:04 AM, WereSpielChequers < werespielchequers@gmail.com> wrote:
Thanks both of you,
I suspect that you two are using very different rules to define "readable characters", and for Aaron to get a close correlation and Fabian not to get any correlation implies to me that Fabian is stripping out the things that are not linked to article size, and that Aaron may be leaving such things in.
For reasons that I'm going to pretend I don't understand, we have some articles with a lot of redundant spaces. Others with so few you'd be correct in thinking that certain editors have been making semiautomated edits to strip out those spaces. I suspect that Fabian's formulae ignores redundant spaces, and that Aaron's does not.
I picked on alt text because it is very patchy across the pedia, but usually consistent at article level. I.e if someone has written a whole paragraph of alt text for one picture they have probably done so for every picture in an article, and conversely many articles will have no alt text at all.
Similarly we have headings, and counterintuitively it is the subheadings that add most non display characters. So an article like Peasant's revolt will have 32 equals signs for its 8 headings, but 60 equal signs for its 10 subheadings. 92 bytes which I suspect one or both of you will have stripped out. The actual display text of course omits all 92 of those bytes, but repeats the content of those headings and subheadings in the contents section.
The size of sections varies enormously from one article to another, and if there are three or fewer sections the contents section is not generated at all. I suspect that the average length of section headings also has quite a bit of variance as it is a stylistic choice. So I would expect that a "display bytes" count that simply stripped out the multiple equal signs would still be a pretty good correlation with article size, but a display bytes count that factored in the complication that headings and subheadings are displayed twice as they are repeated in the contents field, would have another factor drifting it away from a good correlation with raw byte count.
But probably the biggest variance will be over infoboxes, tables, picture captions, hidden comments and the like. If you strip all of them out, including perhaps even the headings, captions and table contents, then you are going to get a very poor fit between article length and readable byte size. But I would be surprised if you could get Fabian's minimum display size of 95 bytes from 6,000 byte articles without having at least one article that consisted almost entirely of tables and which had been reduced to a sentence or two of narrative. So my suspicion is that Aaron's plot is at least including the displayed contents of tables et al whilst Fabian is only measuring the prose sections and completely stripping out anything in a table.
Both approaches of course have their merits, and there are even some editors who were recent edit warring to keep articles they cared about free from clutter by infoboxes and tables.
Regards
Jonathan
On 5 August 2013 21:16, Floeck, Fabian (AIFB) fabian.floeck@kit.eduwrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of " http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but that's a mere hunch. Anyway, this was not what I was looking for. I wanted to compare really only the readable text you see directly when scrolling through the article. What is another issue is the inclusion of expandable template listings as I mentioned in my first mail. Are the long listings of related articles "main, readable article text"? I suppose not, but we did not filter them out yet.
@Aaron, I'm pretty sure I didn't make a mistake, but before I can answer your mail: What exactly does this content_length API call give you back (I'm not aware of that). Takes the Wikisyntax and strips it of tags and comments? Or the HTML shown in the front-end including all content generated by templates minus all mark-up? Only in the ladder case would this be comparable in any way to what I have done. Please clarify and send me the concrete API call. I don't think your content_length is the length of the readable front-end text as I used it. (On a side note: I'm unsure why you paste the complete results of a linear regression, as a Pearson correlation will perfectly suffice in such a simple bivariate case. They - due to the nature of these statistical methods - of course yield the same results in this case. Or was there any important extra information that I missed in these regression results?).
Best,
Fabian
[1] http://www.crummy.com/software/BeautifulSoup/bs4/doc/ [2] http://en.wikipedia.org/wiki/William_Goldenberg#cite_note-1
On 05.08.2013, at 01:15, Aaron Halfaker aaron.halfaker@gmail.com wrote:
(note that I posted this yesterday, but the message bounced due to the
attached scatter plot. I just uploaded the plot to commons and re-sent)
I just replicated this analysis. I think you might have made some
mistakes.
I took a random sample of non-redirect articles from English Wikipedia
and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).c
I get a pearson correlation coef of 0,9514766.
See the scatter plot including a linear regression line. See also the
regress output below.
Call: lm(formula = byte_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers <
werespielchequers@gmail.com> wrote:
Hi Fabian,
That's interesting. When you say you stripped out the html did you also
strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt
text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of
referencing , broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some
correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.edu
wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat
someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much
readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for
the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia
(ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles.
Results for size in characters (w/ whitespaces) after cleaning the HTML
out:
Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates
make it possible.
(See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" --
Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size =
0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate
pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<ATT00001.c>
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics. Kind regards Ziko
Am Dienstag, 6. August 2013 schrieb Aaron Halfaker :
I am removing all HTML tags and comments to include only those characters that are shown on the screen. This will include the content of tables without including the markup contained within. In other words, I stripped anything out of the HTML that looked like a tag (e.g. "<foo>" and "</bar>") or a comment ("<!-- [...] -->") but kept the in-between characters, whitespace and all.
It seems much more reasonable to me that the difference is due to the fact that Fabian's dataset is limited to a very narrow range of bytes. To check this hypothesis, I drew a new sample of pages with byte length between 5800 and 6000.
The pearson correlation that I found for that sample is* 0.06466406. *This corresponds nicely to the poor correlation that Fabian found.
I've update the plot[1] to show the difference visually.
-Aaron
http://commons.wikimedia.org/wiki/File:Bytes.content_length.scatter.correlat...
On Tue, Aug 6, 2013 at 6:04 AM, WereSpielChequers < werespielchequers@gmail.com> wrote:
Thanks both of you,
I suspect that you two are using very different rules to define "readable characters", and for Aaron to get a close correlation and Fabian not to get any correlation implies to me that Fabian is stripping out the things that are not linked to article size, and that Aaron may be leaving such things in.
For reasons that I'm going to pretend I don't understand, we have some articles with a lot of redundant spaces. Others with so few you'd be correct in thinking that certain editors have been making semiautomated edits to strip out those spaces. I suspect that Fabian's formulae ignores redundant spaces, and that Aaron's does not.
I picked on alt text because it is very patchy across the pedia, but usually consistent at article level. I.e if someone has written a whole paragraph of alt text for one picture they have probably done so for every picture in an article, and conversely many articles will have no alt text at all.
Similarly we have headings, and counterintuitively it is the subheadings that add most non display characters. So an article like Peasant's revolt will have 32 equals signs for its 8 headings, but 60 equal signs for its 10 subheadings. 92 bytes which I suspect one or both of you will have stripped out. The actual display text of course omits all 92 of those bytes, but repeats the content of those headings and subheadings in the contents section.
The size of sections varies enormously from one article to another, and if there are three or fewer sections the contents section is not generated at all. I suspect that the average length of section headings also has quite a bit of variance as it is a stylistic choice. So I would expect that a "display bytes" count that simply stripped out the multiple equal signs would still be a pretty good correlation with article size, but a display bytes count that factored in the complication that headings and subheadings are displayed twice as they are repeated in the contents field, would have another factor drifting it away from a good correlation with raw byte count.
But probably the biggest variance will be over infoboxes, tables, picture captions, hidden comments and the like. If you strip all of them out, including perhaps even the headings, captions and table contents, then you are going to get a very poor fit between article length and readable byte size. But I would be surprised if you could get Fabian's minimum display size of 95 bytes from 6,000 byte articles without having at least one article that consisted almost entirely of tables and which had been reduced to a sentence or two of narrative. So my suspicion is that Aaron's plot is at least including the displayed contents of tables et al whilst Fabian is only measuring the prose sections and completely stripping out anything in a table.
Both approaches of course have their merits, and there are even some editors who were recent edit warring to keep articles they cared about free from clutter by infoboxes and tables.
Regards
Jonathan
On 5 August 2013 21:16, Floeck, Fabian (AIFB) fabian.floeck@kit.eduwrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of " http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but
Hi Ziko,
You'll find that articles like that changed radically at the beginning of this year. At that point we moved from a system where all 200 or more articles on Berlin contained 200 or more intrawiki links to the other 200 articles on Berlin, to one where the Intrawiki links are all on Wikidata. That had a very dramatic effect on very stubby articles the Aceh article on Berlin droppedhttp://ak.wikipedia.org/w/index.php?title=Berlin&diff=15464&oldid=15203by 3716 bytes to just 110, and many minor and poorly served languages would be likely to have very short articles on Berlin, dozens still don't have one at all.
I doubt if this accounts for the differences that Fabian and Aaron are experiencing as I've been assuming that they are both looking at current data and I think Fabian mentioned EN.
The change in the way we hold interwiki links also had a radical effect on bot editing numbers as it used to be that each time another language version of the Berlin article was created over 200 other languages version would have a bot edit adding that intrawiki link. I'm assuming that someone sometime is going to pick up on this and report it as a radical slump in editing of Wikipedia's minor languages. But in reality it is just as much a cosmetic and misleading side effect of a change in the way we automate things as measuring the raw edit counts on EN wikipedia since the edit filters were introduced in 2009 and assuming that because we now stop most vandalism from reaching the wiki we have a fall in edit numbers.
Jonathan
On 6 August 2013 01:12, Ziko van Dijk zvandijk@gmail.com wrote:
Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics. Kind regards Ziko
Am Dienstag, 6. August 2013 schrieb Aaron Halfaker :
I am removing all HTML tags and comments to include only those characters
that are shown on the screen. This will include the content of tables without including the markup contained within. In other words, I stripped anything out of the HTML that looked like a tag (e.g. "<foo>" and "</bar>") or a comment ("<!-- [...] -->") but kept the in-between characters, whitespace and all.
It seems much more reasonable to me that the difference is due to the fact that Fabian's dataset is limited to a very narrow range of bytes. To check this hypothesis, I drew a new sample of pages with byte length between 5800 and 6000.
The pearson correlation that I found for that sample is* 0.06466406. *This corresponds nicely to the poor correlation that Fabian found.
I've update the plot[1] to show the difference visually.
-Aaron
http://commons.wikimedia.org/wiki/File:Bytes.content_length.scatter.correlat...
On Tue, Aug 6, 2013 at 6:04 AM, WereSpielChequers < werespielchequers@gmail.com> wrote:
Thanks both of you,
I suspect that you two are using very different rules to define "readable characters", and for Aaron to get a close correlation and Fabian not to get any correlation implies to me that Fabian is stripping out the things that are not linked to article size, and that Aaron may be leaving such things in.
For reasons that I'm going to pretend I don't understand, we have some articles with a lot of redundant spaces. Others with so few you'd be correct in thinking that certain editors have been making semiautomated edits to strip out those spaces. I suspect that Fabian's formulae ignores redundant spaces, and that Aaron's does not.
I picked on alt text because it is very patchy across the pedia, but usually consistent at article level. I.e if someone has written a whole paragraph of alt text for one picture they have probably done so for every picture in an article, and conversely many articles will have no alt text at all.
Similarly we have headings, and counterintuitively it is the subheadings that add most non display characters. So an article like Peasant's revolt will have 32 equals signs for its 8 headings, but 60 equal signs for its 10 subheadings. 92 bytes which I suspect one or both of you will have stripped out. The actual display text of course omits all 92 of those bytes, but repeats the content of those headings and subheadings in the contents section.
The size of sections varies enormously from one article to another, and if there are three or fewer sections the contents section is not generated at all. I suspect that the average length of section headings also has quite a bit of variance as it is a stylistic choice. So I would expect that a "display bytes" count that simply stripped out the multiple equal signs would still be a pretty good correlation with article size, but a display bytes count that factored in the complication that headings and subheadings are displayed twice as they are repeated in the contents field, would have another factor drifting it away from a good correlation with raw byte count.
But probably the biggest variance will be over infoboxes, tables, picture captions, hidden comments and the like. If you strip all of them out, including perhaps even the headings, captions and table contents, then you are going to get a very poor fit between article length and readable byte size. But I would be surprised if you could get Fabian's minimum display size of 95 bytes from 6,000 byte articles without having at least one article that consisted almost entirely of tables and which had been reduced to a sentence or two of narrative. So my suspicion is that Aaron's plot is at least including the displayed contents of tables et al whilst Fabian is only measuring the prose sections and completely stripping out anything in a table.
Both approaches of course have their merits, and there are even some editors who were recent edit warring to keep articles they cared about free from clutter by infoboxes and tables.
Regards
Jonathan
On 5 August 2013 21:16, Floeck, Fabian (AIFB) fabian.floeck@kit.eduwrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of " http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Hello,
Thanks for pointing this out - Wikidata and other evolutions might change something, yes. But still... For example, sometimes WP in Upper Sorabian (hsb.WP) copies whole lists of literature from German Wikipedia, or the secction weblinks etc. That's all "encyclopedic content" then in hsb.WP, but it does not reflect work in the hsb language, and it adds no extra value for the hsb readers. Those books and weblinks, of course, are in German. Nothing to do about - an impression about the size and quality of a language must consider quantitative and qualitative aspects (from autopsy, looking-with-your-own eyes). But on that we all agree anyway. :-) Ziko
Am Dienstag, 6. August 2013 schrieb WereSpielChequers :
Hi Ziko,
You'll find that articles like that changed radically at the beginning of this year. At that point we moved from a system where all 200 or more articles on Berlin contained 200 or more intrawiki links to the other 200 articles on Berlin, to one where the Intrawiki links are all on Wikidata. That had a very dramatic effect on very stubby articles the Aceh article on Berlin droppedhttp://ak.wikipedia.org/w/index.php?title=Berlin&diff=15464&oldid=15203by 3716 bytes to just 110, and many minor and poorly served languages would be likely to have very short articles on Berlin, dozens still don't have one at all.
I doubt if this accounts for the differences that Fabian and Aaron are experiencing as I've been assuming that they are both looking at current data and I think Fabian mentioned EN.
The change in the way we hold interwiki links also had a radical effect on bot editing numbers as it used to be that each time another language version of the Berlin article was created over 200 other languages version would have a bot edit adding that intrawiki link. I'm assuming that someone sometime is going to pick up on this and report it as a radical slump in editing of Wikipedia's minor languages. But in reality it is just as much a cosmetic and misleading side effect of a change in the way we automate things as measuring the raw edit counts on EN wikipedia since the edit filters were introduced in 2009 and assuming that because we now stop most vandalism from reaching the wiki we have a fall in edit numbers.
Jonathan
On 6 August 2013 01:12, Ziko van Dijk <zvandijk@gmail.com<javascript:_e({}, 'cvml', 'zvandijk@gmail.com');>
wrote:
Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics. Kind regards Ziko
Am Dienstag, 6. August 2013 schrieb Aaron Halfaker :
I am removing all HTML tags and comments to include only those characters that are shown on the screen. This will include the content of tables without including the markup contained within. In other words, I stripped anything out of the HTML that looked like a tag (e.g. "<foo>" and "</bar>") or a comment ("<!-- [...] -->") but kept the in-between characters, whitespace and all.
It seems much more reasonable to me that the difference is due to the fact that Fabian's dataset is limited to a very narrow range of bytes. To check this hypothesis, I drew a new sample of pages with byte length between 5800 and 6000.
The pearson correlation that I found for that sample is* 0.06466406. *This corresponds nicely to the poor correlation that Fabian found.
I've update the plot[1] to show the difference visually.
-Aaron
http://commons.wikimedia.org/wiki/File:Bytes.content_length.scatter.correlat...
On Tue, Aug 6, 2013 at 6:04 AM, WereSpielChequers < werespielchequers@gmail.com> wrote:
Thanks both of you,
I suspect that you two are using very different rules to define "readable characters", and for Aaron to get a close correlation and Fabian not to get any correlation implies to me that Fabian is stripping out the things that are not linked to article size, and that Aaron may be leaving such things in.
For reasons that I'm going to pretend I don't understand, we have some articles with a lot of redundant spaces. Others with so few you'd be correct in thinking that certain editors have been making semiautomated edits to strip out those spaces. I suspect that Fabian's formulae ignores redundant spaces, and that Aaron's does not.
I picked on alt text because it is very patchy across the pedia, but usually consistent at article level. I.e if someone has written a whole paragraph of alt text for one picture they have probably done so for every picture in an article, and conversely many articles will have no alt text at all.
Similarly we have headings, and counterintuitively it is the subheadings that add most non display characters. So an article like Peasant's revolt will have 32 equals signs for its 8 headings, but 60 equal signs for its 10 subheadings. 92 bytes which I suspect one or both of you will have stripped out. The actual display text of course omits all 92 of those bytes, but repeats the content of those headings and subheadings in the contents section.
The size of sections varies enormously from one article to another, and if there are three or fewer sections the contents section is not generated at all. I suspect that the average length of section headings also has quite a bit of variance as it is a stylistic choice. So I would expect that a "display bytes" count that simply stripped out the multiple equal signs would still be a pretty good correlation with article size, but a display bytes count that factored in the complication that headings and subheadings are displayed twice as they are repeated in the contents field, would have another factor drifting it away from a good correlation with raw byte count.
But probably the biggest variance will be over infoboxes, tables, picture captions, hidden comments and the like. If you strip all of them out, including perhaps even the headings, captions and table contents, then you are going to get a very poor fit between article length and readable byte size. But I would be surprised if you could get Fabian's minimum display size of 95 bytes from 6,000 byte articles without having at least one article that consisted almost entirely of tables and which had been reduced to a sentence or two of narrative. So my suspicion is that Aaron's plot is at least including the displayed contents of tables et al whilst Fabian is only measuring the prose se
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org <javascript:_e({}, 'cvml', 'Wiki-research-l@lists.wikimedia.org');> https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Ziko van Dijk, 06/08/2013 02:12:
Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics.
You'd better not disregard it completely, as it is used as a key metric for evaluating e.g. the WMF university programs (whether a good or a bad thing). ;-) I don't know how sophisticated a variant of the metric they use; probably whatever the new metrics.wmflabs.org uses.
Personally, I often find the database size on WikiStats tables a useful one to check the evolution of a single wiki, as it's less fluctuating and harder to cheat than other metrics, short of huge bot imports. It requires greater care in cross-wiki comparisons, of course.
Nemo
@Jonathan: Good point, but I'm actually not stripping the content of tables, just the mark-up of the tables. (Also I leave the whitespaces in and count them, just remove line breaks, as the cleaning leaves a lot of empty lines) I checked the results manually in over 50 cases and what my script outputs is almost exactly what you get when you take the article text of a page and copy and paste it into a text editor or Word from the browser by hand, including tables and infoboxes. So it finds exactly what I wanted, the readable, displayed text portion of an article. Remember that I said I also remove "Disambiguation" articles (indicated by "disambiguation" in the article name or category name. Reason being that I wanted articles with running text). They probably have a higher correlation as they don't use templates very much I think. As for the remaining difference in the corr coefficients, it could also be caused by the manner of cleaning. The shortest I got was "Timeline of architectural styles 1000–present" with 95 chars, but this example reveals that sometimes, you would have to include characters inside pictures (can you tell me by chance how frequent these types of code-generated pictures are?). But there are also these examples like the "Veer Teja Vidhya Mandir School" I mentioned (chars= 404) were the template is simply highly underused and bloats the syntax.
@Federico: You are completely right, size in bytes is a good indicator for many things; you could for example argue it accurately measures the work put into an article by the editors, as constructing the Wikisyntax can be a big part of a good article.
@Aaron: "You've severely limited the range of your regressor and therefor invalidated a set of assumptions for the correlation." You seem to be very confused about some statistical concepts: 1. You mix up the concept of inference statistics with a descriptive statistical analysis when you tell me that reporting the result of an experiment on a sample (and as nothing more was this declared) is a "mistake". All I said was that in this sample, with my (ad-hoc!) method, this is the result. No inference about the rest of the articles beyond that sample. Turns out that I was correct, no mistake whatsoever. For me it was interesting enough to post to the list that there is no correlation between the two variables in *this* sample. Which is still a very interesting result as obviously, for at least in this byte size range (maybe others?), there is no or just a tiny correlation to the display char size. I'm happy that you took the time to investigate articles outside this sample, that's the kind of input for which I turned to the research list. 2. I didn't "invalidate" anything, I ran a completely appropriate Pearson correlation over a sample I chose, however unrepresentative that sample may be (again: inference vs descriptive statistics). FYI: A correlation doesn't have a regressor, as you don't have to decide what is the independent and the dependent variable. That's regression; which adds no substantial information here imho (you can draw a fitted R^2 line on a scatterplot just fine without doing a regression). Moreover, you repeatedly ignored the fact in your replication that I also filtered out "Disambiguation" articles. Of course, then you wont get the exact same results as me.
As soon as I find the time, I will run my stuff also over a sample outside the limited 5800-6000 byte range to see what comes out.
Best,
Fabian On 06.08.2013, at 10:53, Federico Leva (Nemo) <nemowiki@gmail.commailto:nemowiki@gmail.com> wrote:
Ziko van Dijk, 06/08/2013 02:12: Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics.
You'd better not disregard it completely, as it is used as a key metric for evaluating e.g. the WMF university programs (whether a good or a bad thing). ;-) I don't know how sophisticated a variant of the metric they use; probably whatever the new metrics.wmflabs.orghttp://metrics.wmflabs.org uses.
Personally, I often find the database size on WikiStats tables a useful one to check the evolution of a single wiki, as it's less fluctuating and harder to cheat than other metrics, short of huge bot imports. It requires greater care in cross-wiki comparisons, of course.
Nemo
_______________________________________________ Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.orgmailto:Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edumailto:fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Update:
Not surprising and congruent with Aarons results, I also get a high linear correlation of 0.96 (random sample of 5000 articles) outside the 5800-6000 sample even if I filter out Disamb articles. See scatterplot [1].
So first of all, it can be fairly certainly concluded that our methods of cleaning are quite similar and are not the cause of mayor differences in the measurements. Secondly, this seems to be a very interesting distribution were the overall correlation is very high but in certain sections (I'm using a speculative plural here) of the distribution is very low. That means we can make the statement "In general, byte size and display char length of an article are highly correlated". This is however not automatically valid once you limit the byte size of the articles you look at in any way (for example, by just looking at Featured Articles, Stubs, etc. (I have yet to check these myself)). Then, you will have to check again if the statement holds true for the given subsample.
These results show very nicely that random sampling in a population is not an infallible "universal weapon" for inferring information about all subsamples of a population and should, where possible, always be cross-checked with non-random selective sample analysis.
Next steps I'd like to take is to look at articles above or below a certain size to see if the correlation differs (maybe because a different proportion of their content is made up of templates).
I'll give an update asap.
Best,
Fabian
[1] https://dl.dropboxusercontent.com/u/3021002/scatter_random5000_NOdisamb1.png
On 06.08.2013, at 15:55, Fabian Flöck <fabian.floeck@kit.edumailto:fabian.floeck@kit.edu> wrote:
@Jonathan: Good point, but I'm actually not stripping the content of tables, just the mark-up of the tables. (Also I leave the whitespaces in and count them, just remove line breaks, as the cleaning leaves a lot of empty lines) I checked the results manually in over 50 cases and what my script outputs is almost exactly what you get when you take the article text of a page and copy and paste it into a text editor or Word from the browser by hand, including tables and infoboxes. So it finds exactly what I wanted, the readable, displayed text portion of an article. Remember that I said I also remove "Disambiguation" articles (indicated by "disambiguation" in the article name or category name. Reason being that I wanted articles with running text). They probably have a higher correlation as they don't use templates very much I think. As for the remaining difference in the corr coefficients, it could also be caused by the manner of cleaning. The shortest I got was "Timeline of architectural styles 1000–present" with 95 chars, but this example reveals that sometimes, you would have to include characters inside pictures (can you tell me by chance how frequent these types of code-generated pictures are?). But there are also these examples like the "Veer Teja Vidhya Mandir School" I mentioned (chars= 404) were the template is simply highly underused and bloats the syntax.
@Federico: You are completely right, size in bytes is a good indicator for many things; you could for example argue it accurately measures the work put into an article by the editors, as constructing the Wikisyntax can be a big part of a good article.
@Aaron: "You've severely limited the range of your regressor and therefor invalidated a set of assumptions for the correlation." You seem to be very confused about some statistical concepts: 1. You mix up the concept of inference statistics with a descriptive statistical analysis when you tell me that reporting the result of an experiment on a sample (and as nothing more was this declared) is a "mistake". All I said was that in this sample, with my (ad-hoc!) method, this is the result. No inference about the rest of the articles beyond that sample. Turns out that I was correct, no mistake whatsoever. For me it was interesting enough to post to the list that there is no correlation between the two variables in *this* sample. Which is still a very interesting result as obviously, for at least in this byte size range (maybe others?), there is no or just a tiny correlation to the display char size. I'm happy that you took the time to investigate articles outside this sample, that's the kind of input for which I turned to the research list. 2. I didn't "invalidate" anything, I ran a completely appropriate Pearson correlation over a sample I chose, however unrepresentative that sample may be (again: inference vs descriptive statistics). FYI: A correlation doesn't have a regressor, as you don't have to decide what is the independent and the dependent variable. That's regression; which adds no substantial information here imho (you can draw a fitted R^2 line on a scatterplot just fine without doing a regression). Moreover, you repeatedly ignored the fact in your replication that I also filtered out "Disambiguation" articles. Of course, then you wont get the exact same results as me.
As soon as I find the time, I will run my stuff also over a sample outside the limited 5800-6000 byte range to see what comes out.
Best,
Fabian On 06.08.2013, at 10:53, Federico Leva (Nemo) <nemowiki@gmail.commailto:nemowiki@gmail.com> wrote:
Ziko van Dijk, 06/08/2013 02:12: Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics.
You'd better not disregard it completely, as it is used as a key metric for evaluating e.g. the WMF university programs (whether a good or a bad thing). ;-) I don't know how sophisticated a variant of the metric they use; probably whatever the new metrics.wmflabs.orghttp://metrics.wmflabs.org/ uses.
Personally, I often find the database size on WikiStats tables a useful one to check the evolution of a single wiki, as it's less fluctuating and harder to cheat than other metrics, short of huge bot imports. It requires greater care in cross-wiki comparisons, of course.
Nemo
_______________________________________________ Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.orgmailto:Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edumailto:fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ckhttp://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edumailto:fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Hi Fabian,
I can honestly say I had never seen an article like "Timeline of architectural styles 1000–present" But even with that one and removing everything I could interpret as hidden or code generated I wound up with a lot more than 95 bytes:
6000BC–1000AD • 1000–1750 • 1750–1900 1900–Present Architectural style Architecture timeline Julian calendar Gregorian calendar Neoclassical Georgian Sicilian Baroque English Baroque Rococo Palladianism Jacobean Baroque Elizabethan Mannerism Spanish Colonial Manueline Tudor High Renaissance Renaissance Perpendicular Period Brick Gothic Decorated Period Early English Period Gothic Norman Romanesque Byzantine Roman Ancient Greek Ancient Egyptian Sumerian Neolithic
So my suspicion is that part of the reason that you and Aaron are getting different results is because your methods of extracting display bytes are different. To get just 95 bytes from this article I think that the program you used you would have had to strip out at least some of the linked words.
Regards
Jonathan
On 6 August 2013 14:55, Floeck, Fabian (AIFB) fabian.floeck@kit.edu wrote:
@Jonathan: Good point, but I'm actually not stripping the content of tables, just the mark-up of the tables. (Also I leave the whitespaces in and count them, just remove line breaks, as the cleaning leaves a lot of empty lines) I checked the results manually in over 50 cases and what my script outputs is almost exactly what you get when you take the article text of a page and copy and paste it into a text editor or Word from the browser by hand, including tables and infoboxes. So it finds exactly what I wanted, the readable, displayed text portion of an article. Remember that I said I also remove "Disambiguation" articles (indicated by "disambiguation" in the article name or category name. Reason being that I wanted articles with running text). They probably have a higher correlation as they don't use templates very much I think. As for the remaining difference in the corr coefficients, it could also be caused by the manner of cleaning. The shortest I got was "Timeline of architectural styles 1000–present" with 95 chars, but this example reveals that sometimes, you would have to include characters inside pictures (can you tell me by chance how frequent these types of code-generated pictures are?). But there are also these examples like the "Veer Teja Vidhya Mandir School" I mentioned (chars= 404) were the template is simply highly underused and bloats the syntax.
@Federico: You are completely right, size in bytes is a good indicator for many things; you could for example argue it accurately measures the work put into an article by the editors, as constructing the Wikisyntax can be a big part of a good article.
@Aaron: "You've severely limited the range of your regressor and therefor invalidated a set of assumptions for the correlation." You seem to be very confused about some statistical concepts:
- You mix up the concept of inference statistics with a descriptive
statistical analysis when you tell me that reporting the result of an experiment on a sample (and as nothing more was this declared) is a "mistake". All I said was that in this sample, with my (ad-hoc!) method, this is the result. No inference about the rest of the articles beyond that sample. Turns out that I was correct, no mistake whatsoever. For me it was interesting enough to post to the list that there is no correlation between the two variables in *this* sample. Which is still a very interesting result as obviously, for at least in this byte size range (maybe others?), there is no or just a tiny correlation to the display char size. I'm happy that you took the time to investigate articles outside this sample, that's the kind of input for which I turned to the research list. 2. I didn't "invalidate" anything, I ran a completely appropriate Pearson correlation over a sample I chose, however unrepresentative that sample may be (again: inference vs descriptive statistics). FYI: A correlation doesn't have a *regressor*, as you don't have to decide what is the independent and the dependent variable. That's regression; which adds no substantial information here imho (you can draw a fitted R^2 line on a scatterplot just fine without doing a regression). Moreover, you repeatedly ignored the fact in your replication that I also filtered out "Disambiguation" articles. Of course, then you wont get the exact same results as me.
As soon as I find the time, I will run my stuff also over a sample outside the limited 5800-6000 byte range to see what comes out.
Best,
Fabian On 06.08.2013, at 10:53, Federico Leva (Nemo) nemowiki@gmail.com wrote:
Ziko van Dijk, 06/08/2013 02:12:
Hello, When in 2008 I made some observations on language versions, it struck me that in some cases the wikisyntax and the "meta article information" was more KB than the whole encyclopedic content of an article. For example, the wikicode of the article "Berlin" in Upper Sorabian consisted of more than 50 % characters for categories, interwiki links etc. This made me largely disregarding the cooncerning features of the Wikimedia statistics.
You'd better not disregard it completely, as it is used as a key metric for evaluating e.g. the WMF university programs (whether a good or a bad thing). ;-) I don't know how sophisticated a variant of the metric they use; probably whatever the new metrics.wmflabs.org uses.
Personally, I often find the database size on WikiStats tables a useful one to check the evolution of a single wiki, as it's less fluctuating and harder to cheat than other metrics, short of huge bot imports. It requires greater care in cross-wiki comparisons, of course.
Nemo
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Hi Aaron,
I'm not sure how Fabian limiting his byte length to 5,500-6,000 would make a difference. But as you've confirmed that your formula includes both the whitespace and the contents of tables, I suspect we just need Fabian to confirm that he ignores both and we have an explanation for the difference between your approaches. And since Fabian's method reduced one article by over 98% to just 95 bytes, I would be very surprised if he is including the text contents of tables. What was your shortest, did you get any with an 80-90% reduction? I'd be surprised if your smallest was under 580 bytes.
Jonathan
On 6 August 2013 00:39, Aaron Halfaker aaron.halfaker@gmail.com wrote:
I am removing all HTML tags and comments to include only those characters that are shown on the screen. This will include the content of tables without including the markup contained within. In other words, I stripped anything out of the HTML that looked like a tag (e.g. "<foo>" and "</bar>") or a comment ("<!-- [...] -->") but kept the in-between characters, whitespace and all.
It seems much more reasonable to me that the difference is due to the fact that Fabian's dataset is limited to a very narrow range of bytes. To check this hypothesis, I drew a new sample of pages with byte length between 5800 and 6000.
The pearson correlation that I found for that sample is* 0.06466406. *This corresponds nicely to the poor correlation that Fabian found.
I've update the plot[1] to show the difference visually.
-Aaron
http://commons.wikimedia.org/wiki/File:Bytes.content_length.scatter.correlat...
On Tue, Aug 6, 2013 at 6:04 AM, WereSpielChequers < werespielchequers@gmail.com> wrote:
Thanks both of you,
I suspect that you two are using very different rules to define "readable characters", and for Aaron to get a close correlation and Fabian not to get any correlation implies to me that Fabian is stripping out the things that are not linked to article size, and that Aaron may be leaving such things in.
For reasons that I'm going to pretend I don't understand, we have some articles with a lot of redundant spaces. Others with so few you'd be correct in thinking that certain editors have been making semiautomated edits to strip out those spaces. I suspect that Fabian's formulae ignores redundant spaces, and that Aaron's does not.
I picked on alt text because it is very patchy across the pedia, but usually consistent at article level. I.e if someone has written a whole paragraph of alt text for one picture they have probably done so for every picture in an article, and conversely many articles will have no alt text at all.
Similarly we have headings, and counterintuitively it is the subheadings that add most non display characters. So an article like Peasant's revolt will have 32 equals signs for its 8 headings, but 60 equal signs for its 10 subheadings. 92 bytes which I suspect one or both of you will have stripped out. The actual display text of course omits all 92 of those bytes, but repeats the content of those headings and subheadings in the contents section.
The size of sections varies enormously from one article to another, and if there are three or fewer sections the contents section is not generated at all. I suspect that the average length of section headings also has quite a bit of variance as it is a stylistic choice. So I would expect that a "display bytes" count that simply stripped out the multiple equal signs would still be a pretty good correlation with article size, but a display bytes count that factored in the complication that headings and subheadings are displayed twice as they are repeated in the contents field, would have another factor drifting it away from a good correlation with raw byte count.
But probably the biggest variance will be over infoboxes, tables, picture captions, hidden comments and the like. If you strip all of them out, including perhaps even the headings, captions and table contents, then you are going to get a very poor fit between article length and readable byte size. But I would be surprised if you could get Fabian's minimum display size of 95 bytes from 6,000 byte articles without having at least one article that consisted almost entirely of tables and which had been reduced to a sentence or two of narrative. So my suspicion is that Aaron's plot is at least including the displayed contents of tables et al whilst Fabian is only measuring the prose sections and completely stripping out anything in a table.
Both approaches of course have their merits, and there are even some editors who were recent edit warring to keep articles they cared about free from clutter by infoboxes and tables.
Regards
Jonathan
On 5 August 2013 21:16, Floeck, Fabian (AIFB) fabian.floeck@kit.eduwrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been done differently, as this was just an ad-hoc experiment. What I did was getting the curl result of " http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X" and running it through BeautifulSoup [1] in Python. Regarding references: yes, all the markup was stripped away which you cannot see in form of readable characters as a human when you look at an article. Take as an example [2]: in the final output (which was the base for counting chars) what is left in characters of this reference is the readable "[1]" and " ^ William Goldenberg at the Internet Movie Database". Regarding alt text: it was completely stripped out. This can arguably be done different, if you see it as "readable main article text" as well. You are sure right that including these would lead to a higher correlation. Looking at samples from the output, the increase in correlation will however not be very big, but that's a mere hunch. Anyway, this was not what I was looking for. I wanted to compare really only the readable text you see directly when scrolling through the article. What is another issue is the inclusion of expandable template listings as I mentioned in my first mail. Are the long listings of related articles "main, readable article text"? I suppose not, but we did not filter them out yet.
@Aaron, I'm pretty sure I didn't make a mistake, but before I can answer your mail: What exactly does this content_length API call give you back (I'm not aware of that). Takes the Wikisyntax and strips it of tags and comments? Or the HTML shown in the front-end including all content generated by templates minus all mark-up? Only in the ladder case would this be comparable in any way to what I have done. Please clarify and send me the concrete API call. I don't think your content_length is the length of the readable front-end text as I used it. (On a side note: I'm unsure why you paste the complete results of a linear regression, as a Pearson correlation will perfectly suffice in such a simple bivariate case. They - due to the nature of these statistical methods - of course yield the same results in this case. Or was there any important extra information that I missed in these regression results?).
Best,
Fabian
[1] http://www.crummy.com/software/BeautifulSoup/bs4/doc/ [2] http://en.wikipedia.org/wiki/William_Goldenberg#cite_note-1
On 05.08.2013, at 01:15, Aaron Halfaker aaron.halfaker@gmail.com wrote:
(note that I posted this yesterday, but the message bounced due to the
attached scatter plot. I just uploaded the plot to commons and re-sent)
I just replicated this analysis. I think you might have made some
mistakes.
I took a random sample of non-redirect articles from English Wikipedia
and compared the byte_length (from database) to the content_length (from API, tags and comments stripped).c
I get a pearson correlation coef of 0,9514766.
See the scatter plot including a linear regression line. See also the
regress output below.
Call: lm(formula = byte_len ~ content_length, data = pages)
Residuals: Min 1Q Median 3Q Max -38263 -419 82 592 37605
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -97.40412 72.46523 -1.344 0.179 content_length 1.14991 0.00832 138.210 <2e-16 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053 F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers <
werespielchequers@gmail.com> wrote:
Hi Fabian,
That's interesting. When you say you stripped out the html did you
also strip out the other parts of the references? Some citation styles will take up more bytes than others, and citation style is supposed to be consistent at the article level.
It would also make a difference whether you included or excluded alt
text from readable material as I suspect it is non granular - ie if someone is going to create alt text for one picture in an article they will do so for all pictures.
More significantly there is a big difference in standards of
referencing , broadly the higher the assessed quality and or the more contentious the article the more references there will be.
I would expect that if you factored that in there would be some
correlation between readable length and bytes within assessed classes of quality, and the outliers would include some of the controversial articles like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) fabian.floeck@kit.edu
wrote:
Hi, to whoever is interested in this (and I hope I didn't just repeat
someone else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much
readable material (excluding pictures) is presented to the reader in the front-end is correlated to the byte size of the Wikisyntax which can be obtained from the DB or API; as people often define the "length" of an article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for
the actual, readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English
Wikipedia (ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as around 5900 bytes is the total en.wiki average for these articles). = 41981 articles.
Results for size in characters (w/ whitespaces) after cleaning the
HTML out:
Min= 95 Max= 49441 Mean=4794.41 Std. Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates
make it possible.
(See e.g. "Veer Teja Vidhya Mandir School", "Martin Callanan" --
Allthough for the ladder you could argue that expandable template listings are not really main "reading" content..)
Effectively, correlation for readable character size with byte size =
0.04 (i.e. none) in the sample.
If someone already did this or a similar analysis, I'd appreciate
pointers.
Best,
Fabian
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<ATT00001.c>
-- Karlsruhe Institute of Technology (KIT) Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck Research Associate
Building 11.40, Room 222 KIT-Campus South D-76128 Karlsruhe
Phone: +49 721 608 4 6584 Fax: +49 721 608 4 6580 Skype: f.floeck_work E-Mail: fabian.floeck@kit.edu WWW: http://www.aifb.kit.edu/web/Fabian_Fl%C3%B6ck
KIT – University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
Wiki-research-l mailing list Wiki-research-l@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
wiki-research-l@lists.wikimedia.org
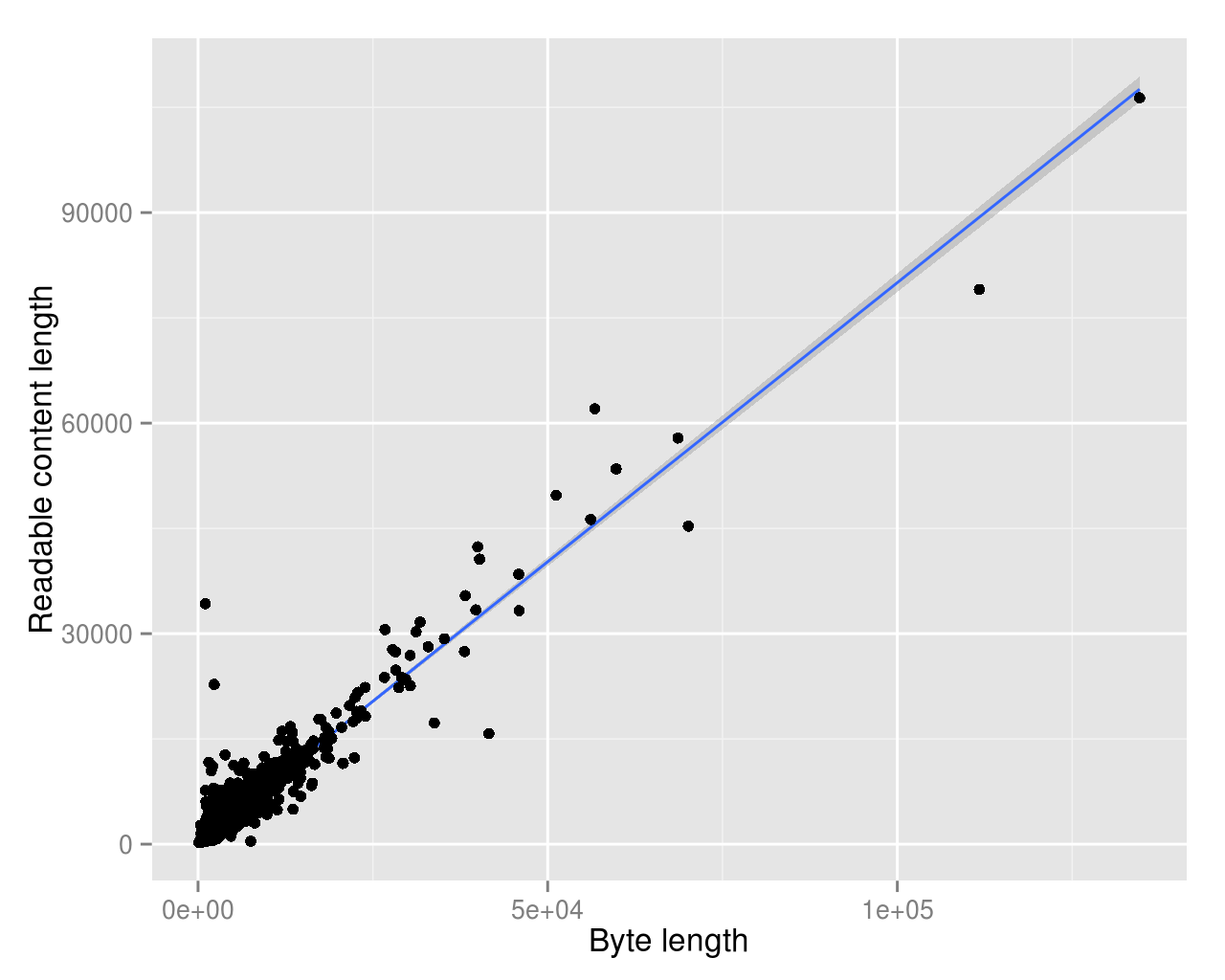{kind=link}