Pursuant to prior discussions about the need for a research
policy on Wikipedia, WikiProject Research is drafting a
policy regarding the recruitment of Wikipedia users to
participate in studies.
At this time, we have a proposed policy, and an accompanying
group that would facilitate recruitment of subjects in much
the same way that the Bot Approvals Group approves bots.
The policy proposal can be found at:
http://en.wikipedia.org/wiki/Wikipedia:Research
The Subject Recruitment Approvals Group mentioned in the proposal
is being described at:
http://en.wikipedia.org/wiki/Wikipedia:Subject_Recruitment_Approvals_Group
Before we move forward with seeking approval from the Wikipedia
community, we would like additional input about the proposal,
and would welcome additional help improving it.
Also, please consider participating in WikiProject Research at:
http://en.wikipedia.org/wiki/Wikipedia:WikiProject_Research
--
Bryan Song
GroupLens Research
University of Minnesota
Hi all,
For all Hive users using stat1002/1004, you might have seen a deprecation
warning when you launch the hive client - that claims it's being replaced
with Beeline. The Beeline shell has always been available to use, but it
required supplying a database connection string every time, which was
pretty annoying. We now have a wrapper
<https://github.com/wikimedia/operations-puppet/blob/production/modules/role…>
script
setup to make this easier. The old Hive CLI will continue to exist, but we
encourage moving over to Beeline. You can use it by logging into the
stat1002/1004 boxes as usual, and launching `beeline`.
There is some documentation on this here:
https://wikitech.wikimedia.org/wiki/Analytics/Cluster/Beeline.
If you run into any issues using this interface, please ping us on the
Analytics list or #wikimedia-analytics or file a bug on Phabricator
<http://phabricator.wikimedia.org/tag/analytics>.
(If you are wondering stat1004 whaaat - there should be an announcement
coming up about it soon!)
Best,
--Madhu :)
Hey everyone,
we're hosting a dedicated session in June on our joint work with Cornell
and Jigsaw on predicting conversational failure
<https://arxiv.org/abs/1805.05345> on Wikipedia talk pages. This is part of
our contribution to WMF's Anti-Harassment program.
The showcase
<https://www.mediawiki.org/wiki/Wikimedia_Research/Showcase#June_2018> will be
live-streamed <https://www.youtube.com/watch?v=m4vzI0k4OSg> on *Monday,
June 18, 2018* at 11:30 AM (PDT), 18:30 (UTC). (Please note this falls on
a Monday this month).
Conversations Gone Awry. Detecting Early Signs of Conversational
FailureBy *Justine
Zhang and Jonathan Chang, Cornell University*One of the main challenges
online social systems face is the prevalence of antisocial behavior, such
as harassment and personal attacks. In this work, we introduce the task of
predicting from the very start of a conversation whether it will get out of
hand. As opposed to detecting undesirable behavior after the fact, this
task aims to enable early, actionable prediction at a time when the
conversation might still be salvaged. To this end, we develop a framework
for capturing pragmatic devices—such as politeness strategies and
rhetorical prompts—used to start a conversation, and analyze their relation
to its future trajectory. Applying this framework in a controlled setting,
we demonstrate the feasibility of detecting early warning signs of
antisocial behavior in online discussions.
Building a rich conversation corpus from Wikipedia Talk pagesWe present a
corpus of conversations that encompasses the complete history of
interactions between contributors to English Wikipedia's Talk Pages. This
captures a new view of these interactions by containing not only the final
form of each conversation but also detailed information on all the actions
that led to it: new comments, as well as modifications, deletions and
restorations. This level of detail supports new research questions
pertaining to the process (and challenges) of large-scale online
collaboration. As an example, we present a small study of removed comments
highlighting that contributors successfully take action on more toxic
behavior than was previously estimated.
YouTube stream: https://www.youtube.com/watch?v=m4vzI0k4OSg
As usual, you can join the conversation on IRC at #wikimedia-research. And,
you can watch our past research showcases here
<https://www.youtube.com/playlist?list=PLhV3K_DS5YfLQLgwU3oDFiGaU3K7pUVoW>.
Hope to see you there on June 18!
Dario
Curious, what percentage of digital assistants (Alexa, Siri, Cortana,
Google) cite Wikipedia when a person asks a question?
Does the current Wikipedia mobile app support voice search?
Are there any reports on this? Thanks in advance!
Sincere regards,
Stella
--
Stella Yu | STELLARESULTS | 415 690 7827
"Chronicling heritage brands and legendary people."
Hi all!
*If you are not an active user of the EventStreams service, you can ignore
this email.*
We’re in the process of upgrading
<https://phabricator.wikimedia.org/T152015> the backend infrastructure that
powers the EventStreams service. When we switch EventStreams to the new
infrastructure <https://phabricator.wikimedia.org/T185225>, the ‘offsets’
AKA Last-Event-IDs will change.
Connected EventStreams SSE clients will reconnect and not be able to
automatically consume from the exact position in the stream where they left
off. Instead, reconnecting clients will begin consuming from the latest
messages in the stream. This means that connected clients will likely miss
any messages that occurred during the reconnect period. Hopefully this
will be a very small number of messages, as your SSE client should
reconnect quickly.
This switch is scheduled to happen on June 5 2018, at around 17:30 UTC.
Let us know if you have any questions.
Thanks!
- Andrew Otto
Senior Systems Engineer, WMF
INTRODUCTION
Machine-utilizable lexicons can enhance a great number of speech and natural language technologies. Scientists, engineers and technologists – linguists, computational linguists and artificial intelligence researchers – eagerly await the advancement of machine lexicons which include rich, structured metadata and machine-utilizable definitions.
Wiktionary, a collaborative project to produce a free-content multilingual dictionary, aims to describe all words of all languages using definitions and descriptions. The Wiktionary project, brought online in 2002, includes 139 spoken languages and American sign language [1].
This letter hopes to inspire exploration into and discussion regarding machine wiktionaries, machine-utilizable crowdsourced lexicons, and services which could exist at https://machine.wiktionary.org/ .
LEXICON EDITIONING
The premise of editioning is that one version of the resource can be more or less frozen, e.g. a 2018 edition, while wiki editors collaboratively work on a next version, e.g. a 2019 edition. Editioning can provide stability for complex software engineering scenarios utilizing an online resource. Some software engineering teams, however, may choose to utilize fresh dumps or data exports of the freshest edition.
SEMANTIC WEB
A machine-utilizable lexicon could include a semantic model of its contents and a SPARQL endpoint.
MACHINE-UTILIZABLE DEFINITIONS
Machine-utilizable definitions, available in a number of knowledge representation formats, can be granular, detailed and nuanced.
There exist a large number of use cases for machine-utilizable definitions. One use case is providing natural language processing components with the capabilities to semantically interpret natural language, to utilize automated reasoning to disambiguate lexemes, phrases and sentences in contexts. Some contend that the best output after a natural language processing component processes a portion of natural language is each possible interpretation, perhaps weighted via statistics. In this way, (1) natural language processing components could process ambiguous language, (2) other components, e.g. automated reasoning components, could narrow sets of hypotheses utilizing dialogue contexts, (3) other components, e.g. automated reasoning components, could narrow sets of hypotheses utilizing knowledgebase content, and (4) mixed-initiative dialogue systems could also ask users questions to narrow sets of hypotheses. Such disambiguation and interpretation would utilize machine-utilizable definitions of senses of lexemes.
CONJUGATION, DECLENSION AND THE URL-BASED SPECIFICATION OF LEXEMES AND LEXICAL PHRASES
A grammatical category [2] is a property of items within the grammar of a language; it has a number of possible values, sometimes called grammemes, which are normally mutually exclusive within a given category. Verb conjugation, for example, may be affected by the grammatical categories of: person, number, gender, tense, aspect, mood, voice, case, possession, definiteness, politeness, causativity, clusivity, interrogativity, transitivity, valency, polarity, telicity, volition, mirativity, evidentiality, animacy, associativity, pluractionality, reciprocity, agreement, polypersonal agreement, incorporation, noun class, noun classifiers, and verb classifiers in some languages [3].
By combining the grammatical categories from each and every language together, we can precisely specify a conjugation or declension. For example, the URL:
https://machine.wiktionary.org/wiki/lookup.php?edition=2018&language=en-US&…
includes an edition, a language of a lemma, a lemma, a lexical category, and conjugates (with ellipses) the verb in a language-independent manner.
We can further specify, via URL query string, the semantic sense of a grammatical element:
https://machine.wiktionary.org/wiki/lookup.php?edition=2018&language=en-US&…
Specifying a grammatical item fully in a URL query string, as indicated in the previous examples, could result in a redirection to another URL.
That is, the URL:
https://machine.wiktionary.org/wiki/lookup.php?edition=2018&language=en-US&…
could redirect to:
https://machine.wiktionary.org/wiki/index.php?edition=2018&id=12345678
or to:
https://machine.wiktionary.org/wiki/2018/12345678/
and the URL with a specified semantic sense:
https://machine.wiktionary.org/wiki/lookup.php?edition=2018&language=en-US&…
could redirect to:
https://machine.wiktionary.org/wiki/index.php?edition=2018&id=12345678&sens…
or to:
https://machine.wiktionary.org/wiki/2018/12345678/4/
The URL https://machine.wiktionary.org/wiki/2018/12345678/ is intended to indicate a conjugation or declension with one or more meanings or senses. The URL https://machine.wiktionary.org/wiki/2018/12345678/4/ is intended to indicate a specific sense or definition of a conjugation or declension. A feature from having URL’s for both conjugations or declensions and for specific meanings or senses is that HTTP request headers can specify languages and content types of the output desired for a particular URL.
The provided examples intended to indicate that each complete, language-independent conjugation or declension can have an ID number as opposed to each headword or lemma. Instead of one ID number for all variations of “fly”, there is one ID number for “flew”, another for “have flown”, another for “flying”, and one for each conjugation or declension. Reasons for indexing the conjugations and declensions instead of traditional headwords or lemmas include that, at least for some knowledge representation formats, the formal semantics of the definitions vary per conjugation or declension.
CONCLUSION
This letter broached machine wiktionaries and some of the services which could exist at https://machine.wiktionary.org/ . It is my hope that this letter indicated a few of the many exciting topics with regard to machine-utilizable crowdsourced lexicons.
REFERENCES
[1] https://en.wiktionary.org/wiki/Index:All_languages#List_of_languages
[2] https://en.wikipedia.org/wiki/Grammatical_category
[3] https://en.wikipedia.org/wiki/Grammatical_conjugation
[4] https://en.wikipedia.org/wiki/List_of_HTTP_header_fields#Request_fields
Hi Research-l,
My impression is that volunteers on Commons and ENWP spend a lot of time on categorization. I have seen references to analyses of how categorization is done, but I can't recall seeing an analysis of how much use readers make of categories on Commons and ENWP. My guess is that readers often use categories on Commons for media searches, but that ENWP categories are rarely used by readers, although maybe WMF Discovery uses categories to inform search results. Is there data that shows how extensively readers on ENWP and Commons use categories?
Thanks,Pine
( https://meta.wikimedia.org/wiki/User:Pine )
LiAnna, is there any way the filter rules could be adjusted to allow
my followup questions, please?
---------- Forwarded message ----------
From: <education-owner(a)lists.wikimedia.org>
Date: Tue, May 22, 2018 at 5:50 PM
Subject: Re: [Wikimedia Education] Evaluation report on Wikipedia Fellows pilot
To: jsalsman(a)gmail.com
Message rejected by filter rule match
---------- Forwarded message ----------
From: James Salsman <jsalsman(a)gmail.com>
To: Wikimedia Education <education(a)lists.wikimedia.org>
Cc:
Bcc:
Date: Tue, 22 May 2018 17:50:48 -0600
Subject: Re: [Wikimedia Education] Evaluation report on Wikipedia Fellows pilot
LiAnna, thank you so much for sending the list of twelve partner
associations at https://wikiedu.org/partnerships/
I am copying the list here because I have more questions:
American Anthropological Association
American Chemical Society
American Society of Plant Biologists
American Sociological Association
American Studies Association
Association for Psychological Science
Association for Women in Mathematics
Linguistic Society of America
Louisiana State University, Communication across the Curriculum
Midwest Political Science Association
National Communication Association
National Women’s Studies Association
Society for Marine Mammalogy
I'd like to recommend brainstorming what a list of, say 50 such
associations would look like if you picked them specifically to
balance them against e.g.
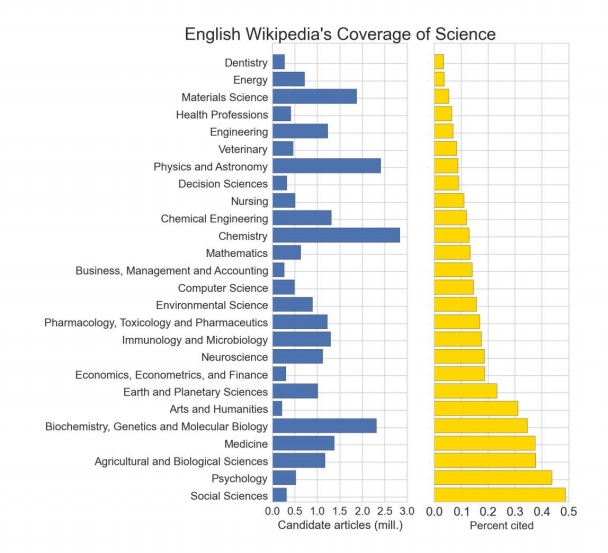
http://blogs.lse.ac.uk/impactofsocialsciences/files/2015/09/figure-1-wikipe…
Since I am certain you will see the merit of such work, I want to take
this time to say a few words about economics. In particular, with
reference to:
https://lists.wikimedia.org/pipermail/wiki-research-l/2018-April/006256.html
and
https://lists.wikimedia.org/pipermail/wikimedia-l/2018-May/090241.html
These are very serious questions impacting the lives, livelihoods, and
years of productive life of billions upon billions of people, and will
probably remain as weighty for years.
In the mean time, I want to take this opportunity to reiterate my
recommendation to establish an essay contest for students on topics
such as economics, or any of Wikipedia's under-represented sciences or
humanities. The last time we discussed this question I did not
understand the reasons that you suggested such an essay contest would
be inappropriate. Has your view evolved?
Best regards,
Jim
On Tue, May 22, 2018 at 3:57 PM, LiAnna Davis <lianna(a)wikiedu.org> wrote:
> Answers inline!
>
> On Tue, May 22, 2018 at 12:15 PM, Juliana Bastos Marques <
> domusaurea(a)gmail.com> wrote:
>>
>> I’d like to add another question. As you and others may know, I work in a
>> particularly quarrelsome Wikipedia (PT), where there are lots of reversions
>> of edits from newbies, even when they display knowledge of WP rules. What
>> was the reception of the Fellows’ work among the community of editors?
>>
>> There were some minor disagreements with other English Wikipedia editors,
> but conversations were ultimately productive. We did have one article
> nominated for deletion, but the Fellow was able to successfully argue for
> it to not be deleted.
>
>
>
>> Em 22 de mai de 2018, à(s) 16:02, James Salsman <jsalsman(a)gmail.com>
>> escreveu:
>>
>> > Would you please describe how you choose the subject matter of
>> > articles and expertise for inviting Fellows?
>>
>
> Fellows chose their own articles to improve based on their interests and
> expertise. We selected the associations to participate in the pilot based
> on our relationships with them; we're expanding future Fellows cohorts to
> other subject areas.
>
>
>> > It's not clear whether the Fellows were paid or otherwise compensated;
>> > were they?
>>
>
> There's a reference to this in the "Recruiting Wikipedia Fellows" section
> (I know there's a lot in here, so I'm not surprised if you missed it!): "We
> encouraged partners to consider offering Fellows honoraria, travel
> scholarships to their conference, or conference fee waivers. Partners were
> amenable to the idea but most said they needed more time to be able to
> offer it. We hope this might be able to be built into future Fellows
> cohorts."
>
>> "In the past four years, the Wiki Education Foundation (Wiki
>> > Education) has signed formal partnership agreements with academic
>> > associations to improve Wikipedia in their topic area." -- how many?
>> > Is the list public?
>>
>
> We've signed agreements with 12 academic associations; they're listed on
> our website: https://wikiedu.org/partnerships/
>
>
>> > When you select such subjects and topics, do you consider the number
>> > of pageviews? Do you use existing WP:BACKLOG category membership?
>> > Both?
>>
>
> We encouraged Fellows to choose articles that would receive large page
> views or were core articles in their field -- subjects that they would be
> able to improve but a student studying that topic would struggle to
> effectively improve. Beyond that, we left the selection up to the Fellows.
>
>
>> > Do you consider the harm inaccuracy or bias can do to society by
>> > infesting Wikipedia when selecting the subject and topics?
>>
>
> We teach all our program participants about the importance of NPOV and
> stress how writing for Wikipedia needs to be fact-based, encyclopedic
> content, not persuasive, analytical content.
> _______________________________________________
> Education mailing list
> Education(a)lists.wikimedia.org
> https://lists.wikimedia.org/mailman/listinfo/education
Hi everyone,
There's a new full-time Senior-level research position available at WMF
that you should know about. Details below and here.
<https://boards.greenhouse.io/wikimedia/jobs/1158794?gh_src=66fd12661>
Please forward this on to relevant contacts and channels!
I am able to answer some questions about this position—but for best
results, please direct your questions to Margeigh Novotny, Director of Product
Design Strategy
<https://wikimediafoundation.org/wiki/Staff_and_contractors#Product_Design_S…>
.
Thanks,
Jonathan
Senior Design Researcher at Wikimedia Foundation (View all jobs)
<https://boards.greenhouse.io/wikimedia?t=66fd12661>
San Francisco, CA or Remote
*Location: *San Francisco, CA or Remote
*Duration: *Permanent
*Hours: *Full time
*Summary*
The Wikimedia Foundation’s Product Design Strategy Group is seeking a
senior design researcher to whose primary focus will be to work with
the Anti-Harassment
Tools (AHT) Team to support the development of tools
<https://meta.wikimedia.org/wiki/Community_health_initiative#Anti-Harassment…>
and policies
<https://meta.wikimedia.org/wiki/Community_health_initiative#Policy_Growth_&…>
aimed at reducing online harassment and other disruptive behavior on
Wikipedia and Wikimedia projects. Formed in 2017, the AHT team’s mission
is to address a wide range of behavior: from content vandalism, stalking,
name-calling, trolling, doxxing, and discrimination, to anything that
targets individuals for unfair and harmful attention. As the world’s
largest encyclopedia, and a cornerstone of the open content movement,
Wikimedia seeks to build and model an online community that aligns with its
mission of inclusion and diversity.
The team is building tools that will: help detect harassment and stalking;
make it easier for people to report harassment; help wiki administrators to
evaluate reports; and block unwanted harassers from our projects. Working
closely with product managers, developers, community advocates and many
passionate volunteers, the Sr. Researcher will design qualitative and
quantitative research that results in actionable insights that can drive
the development of these new tools. Wikipedia and the other Wikimedia
projects are complex places, both socially and technically — this position
requires enthusiasm for learning about new communities, processes, and
cultural norms.
The WMF Product Design Strategy Group provides strategic research and
experimentation to help inform and inspire future product and platform
decisions.
*Responsibilities:*
- Design, drive and support qualitative and quantitative research agenda
to better understand the needs of Wikipedia contributors who have
experienced or witnessed harassment, and administrators who are working to
protect the editing community
- Perform analysis of complex, dynamic online communities to identify
opportunities and problematic areas of existing tools and workflows
- Help design a set of interdependent software features, in
collaboration with the editors who will use those features
- Consult and collaborate with other researchers to ensure quality and
usability of output
*Requirements: *
- Expertise in multiple qualitative research methodologies, e.g.
surveys, textual analysis, and ethnographic interviewing and observation,
including qualitative analysis methods.
- A strong sense of mission and energy for this initiative
- Experience with quantitative research methodologies, e.g. statistical
analysis, data visualization, data manipulation
- Outstanding written and verbal communication skills
- Aptitude for defining and measuring project success
- Strong time-management skills
- Self sufficiency and ability to resolve what blocks your work within a
cross-functional team environment
- Comfortable working on short deadlines and the ability to pivot quickly
- Experience leading research projects from start to finish (solo and in
collaboration with others)
- Collaborative nature (willingness to make collaboration across time
zones via remote functionality work, as well as in person collaboration)
- Academic training in Behavioral or Social Sciences (e.g. sociology,
social psychology, anthropology), Information Science, or Human-Computer
Interaction background
- 5+ years of professional experience in a research role
- Masters Degree or PhD in a related field
- Experience working collaboratively with design teams to translate
insights into actionable recommendations
*Pluses: *
- A nuanced understanding of group dynamics and online cultural practices
- Experience working in interdisciplinary teams with data scientists and
designers
- A history of social activism, volunteering, and/or open source
contribution
- Experience contributing to Wikimedia projects
- A strong portfolio of public presentations of research work (e.g.
conference presentations, white papers, peer-reviewed manuscripts)
* The Wikimedia Foundation is... *
...the nonprofit organization that supports Wikipedia and the other
Wikimedia free knowledge projects. Our vision is a world in which every
single human can freely share in the sum of all knowledge. We believe that
everyone has the potential to contribute something to our shared knowledge,
and that everyone should be able to access that knowledge, free of
interference. We host the Wikimedia projects, build software experiences
for reading, contributing, and sharing Wikimedia content, support the
volunteer communities and partners who make Wikimedia possible, and
advocate for policies that enable Wikimedia and free knowledge to thrive.
The Wikimedia Foundation is a charitable, not-for-profit organization that
relies on donations. We receive financial support from millions of
individuals around the world, with an average donation of about $15. We
also receive donations through institutional grants and gifts. The
Wikimedia Foundation is a United States 501(c)(3) tax-exempt organization
with offices in San Francisco, California, USA.
*The Wikimedia Foundation is an equal opportunity employer, and we
encourage people with a diverse range of backgrounds to apply*
*Benefits & Perks **
- Fully paid medical, dental and vision coverage for employees and their
eligible families (yes, fully paid premiums!)
- The Wellness Program provides reimbursement for mind, body and soul
activities such as fitness memberships, baby sitting, continuing
education and much more
- The 401(k) retirement plan offers matched contributions at 4% of
annual salary
- Flexible and generous time off - vacation, sick and volunteer days,
plus 19 paid holidays - including the last week of the year.
- Family friendly! 100% paid new parent leave for seven weeks plus an
additional five weeks for pregnancy, flexible options to phase back in
after leave, fully equipped lactation room.
- For those emergency moments - long and short term disability, life
insurance (2x salary) and an employee assistance program
- Pre-tax savings plans for health care, child care, elder care, public
transportation and parking expenses
- Telecommuting and flexible work schedules available
- Appropriate fuel for thinking and coding (aka, a pantry full of
treats) and monthly massages to help staff relax
- Great colleagues - diverse staff and contractors speaking dozens of
languages from around the world, fantastic intellectual discourse,
mission-driven and intensely passionate people
--
Jonathan T. Morgan
Senior Design Researcher
Wikimedia Foundation
User:Jmorgan (WMF) <https://meta.wikimedia.org/wiki/User:Jmorgan_(WMF)>
INTRODUCTION
Some technical topics are broached toward the crowdsourcing of dialogue system content and behavior.
COLLABORATIVE AUTHORING
The content and behavior of a dialogue system can be represented in a number of ways.
Firstly, the content and behavior of a dialogue system can be represented in programming language source code files. Collaborative authoring, in this case, is a matter of integrated development environments and source code repositories, version control systems.
Secondly, some or all of the content and behavior of a dialogue system can be separated from the source code files as data stored in some data format or in a database. Collaborative authoring, in this case, could require custom software tools.
Thirdly, a number of services, cognitive services, can encapsulate the content and behavior of a dialogue system. Collaborative authoring, in this case, could require utilization of such services or related user interfaces.
Fourthly, the content and behavior of a dialogue system can be represented as a set of interrelated, URL-addressable, editable pages. Servers can provide content for a number of different content types, for example hypertext for content authors and other formats for dialogue system user agents. Server-side scripting can be utilized to generate pages and generated pages can contain client-side scripting.
Fifthly, the content and behavior of a dialogue system can be represented as a set of interrelated, URL-addressable, editable diagrams.
Sixthly, the content and behavior of a dialogue system can be represented in transcript form. Transcript-based user interfaces may resemble instant messaging applications, scrollable sequences of speech bubbles, with speech bubbles coming from the left and right sides, such that users can edit the content in dialogue systems’ speech bubbles. Users could opt to view more than plain text in speech bubbles. There could also be vertical, colored bands in one or both margins, visually indicating discourse behaviors, moves, objectives or plans which span one or multiple utterances.
COLLABORATIVE DEBUGGING
Debugging dialogue systems is an important topic. Debugging scenarios include switching from interactions with dialogue systems to authoring processes such that dialogue context data is preserved.
NATURAL LANGUAGE GENERATION AND UNDERSTANDING
Natural language generation can produce editable structured documents from the data stored in databases and knowledgebases. Generated content can contain, beyond natural language, data and program logic to facilitate the processing of constrained or unconstrained edits. Edits to generated content can result in changes to stored data.
COMPUTER-AIDED WRITING
Computer-aided writing can convenience content authors and assure quality. Software can, generally speaking, provide users with information, warnings and errors with regard to tentative edits. Software can support users including with regard to their spelling, grammar, word selection, readability, text coherence and cohesion. Software can measure the neutral point of view of natural language. Software can also process tentative edits with regard to their logical consistency with respect to data stored in databases and knowledgebases.
WIKI DIALOGUE SYSTEMS
Exploration into the collaborative authoring and debugging of dialogue systems could result in new wiki technologies. Wiki dialogue systems could resemble spoken language dialogue systems with transcript-based user interfaces, users able to easily switch between dialogue-based interactions and the editing of dialogue system content and behavior.
Best regards,
Adam Sobieski
http://www.phoster.com/contents/
{kind=link}