Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Hi Edouard,
Thank you for taking the time to respond!
The web start works for me; I had to whitelist the url in Java but otherwise it was fine. So as I said, I have trouble connecting an image with metadata on that image from a CSV file. It might already be helpful if you have some screen shots on how that works. If I can get that to work, this will really be helpful for some of our upcoming GLAM-projects (and one on which I am working now, and for which I hope to do an upload soon).
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*: * Bezoekadres:* Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 15:13 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
I don't know how long it's going to be before it can be used (approx. 4 months) but this tool sounds very promising!
Best of luck with the uploads! Jesse
2016-01-07 15:25 GMT+01:00 Arne Wossink wossink@wikimedia.nl:
Hi Edouard,
Thank you for taking the time to respond!
The web start works for me; I had to whitelist the url in Java but otherwise it was fine. So as I said, I have trouble connecting an image with metadata on that image from a CSV file. It might already be helpful if you have some screen shots on how that works. If I can get that to work, this will really be helpful for some of our upcoming GLAM-projects (and one on which I am working now, and for which I hope to do an upload soon).
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*:
- Bezoekadres:*
Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 15:13 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Ok, a quick answer then :)
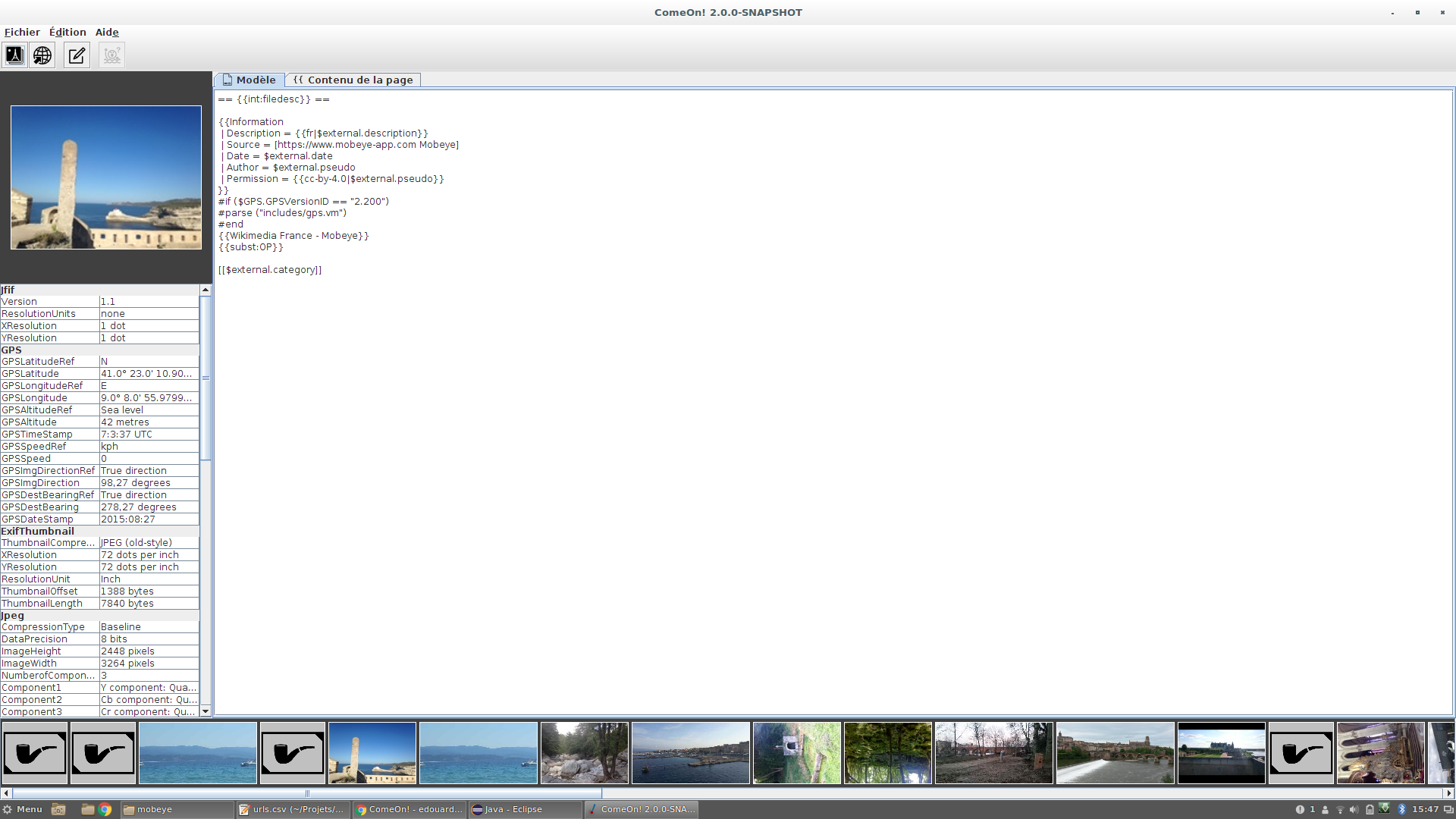
Here is an example from an upload we made at Wikimedia France in september. Metadata matching is done against the last column of the CSV file, which contains the exact name of the picture file. It could be any information available in the EXIF as well.
In ComeOn!, in the "open pictures" dialog, first pick the CSV file. The combo box will update with the column titles from the file (there is a bug here that won't refresh the combo when you select a file again without closing the dialog). Fill in the right field the expression that selects the field from the picture metadata to match. It may be any EXIF field (as show in the left pane of the main window when displaying a picture) or a special value from a reserved keyword (I need to document these), as " file.name". The "regular expression" and "substitution" fields may be used to transform the picture metadata before matching it against the file. The default is safe as it keeps the information as is, but you could use it to extract a part of the "fichier" column, add a prefix and a suffix and so on.
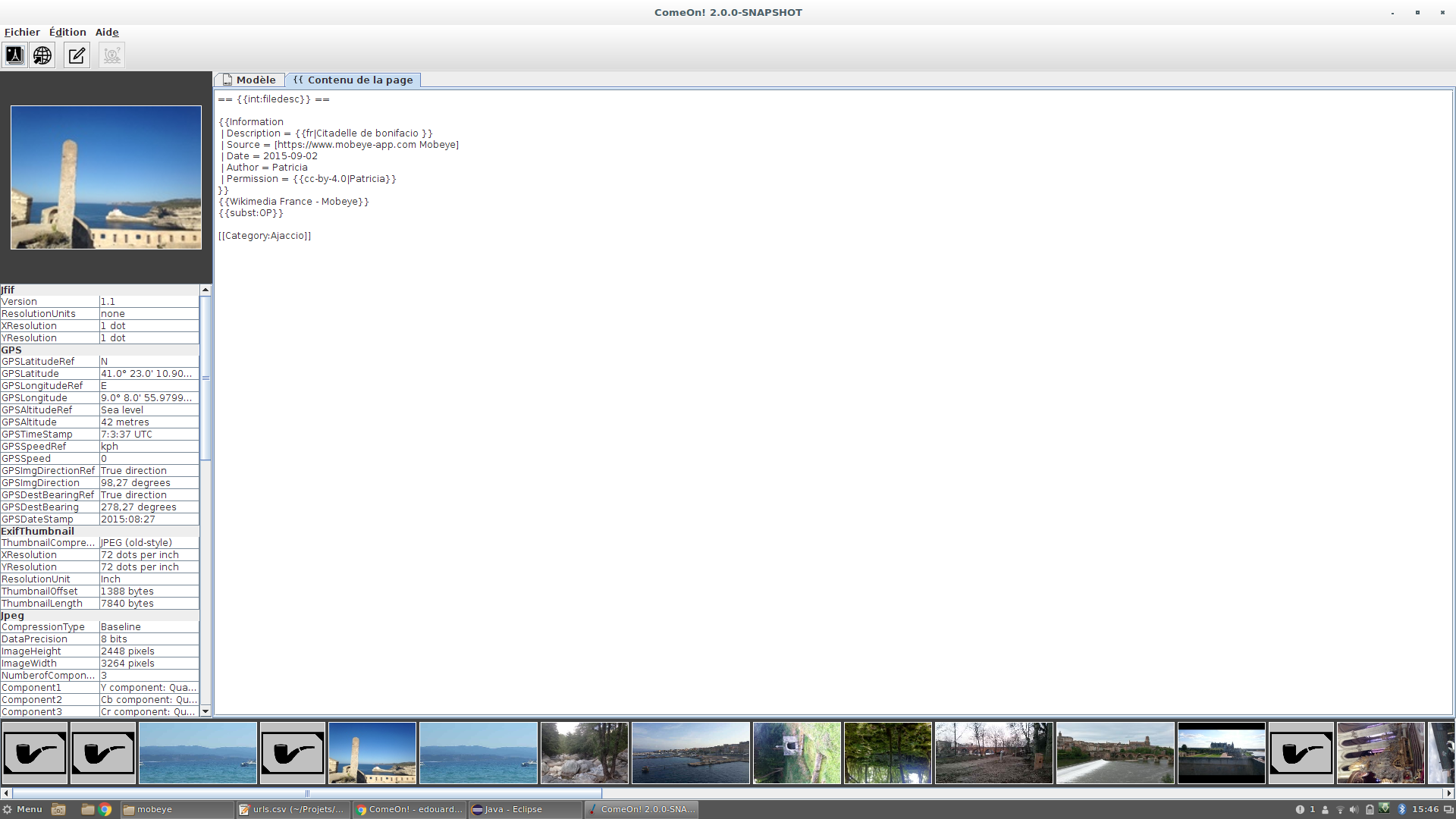
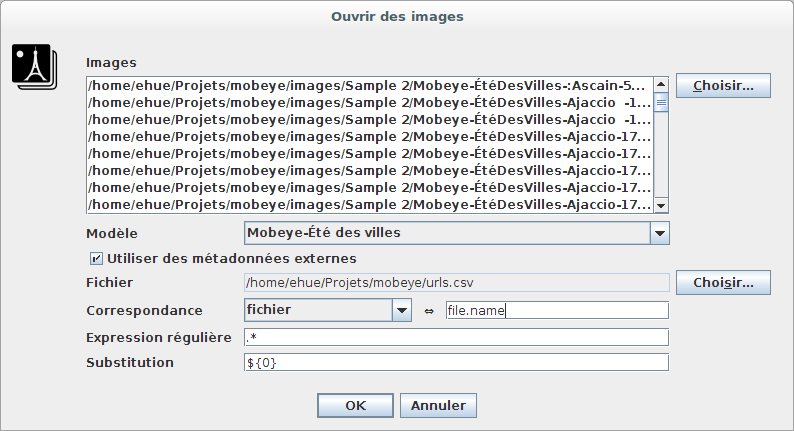
In the file description templates, metadata from the file may be inserted with this stance: "$external." appended with the CSV column title. After loading the pictures, if the matching was succesful, the "content" tab should show a proper page.
BR,
Édouard
On Thu, Jan 7, 2016 at 3:25 PM, Arne Wossink wossink@wikimedia.nl wrote:
Hi Edouard,
Thank you for taking the time to respond!
The web start works for me; I had to whitelist the url in Java but otherwise it was fine. So as I said, I have trouble connecting an image with metadata on that image from a CSV file. It might already be helpful if you have some screen shots on how that works. If I can get that to work, this will really be helpful for some of our upcoming GLAM-projects (and one on which I am working now, and for which I hope to do an upload soon).
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*:
- Bezoekadres:*
Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 15:13 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Ok, a quick answer then :)
Here is an example from an upload we made at Wikimedia France in september. Metadata matching is done against the last column of the CSV file, which contains the exact name of the picture file. It could be any information available in the EXIF as well.
In ComeOn!, in the "open pictures" dialog, first pick the CSV file. The combo box will update with the column titles from the file (there is a bug here that won't refresh the combo when you select a file again without closing the dialog). Fill in the right field the expression that selects the field from the picture metadata to match. It may be any EXIF field (as show in the left pane of the main window when displaying a picture) or a special value from a reserved keyword (I need to document these), as " file.name". [1] The "regular expression" and "substitution" fields may be used to transform the picture metadata before matching it against the file. The default is safe as it keeps the information as is, but you could use it to extract a part of the "fichier" column, add a prefix and a suffix and so on.
In the file description templates, metadata from the file may be inserted with this stance: "$external." appended with the CSV column title. After loading the pictures, if the matching was succesful, the "content" tab should show a proper page.
1 : https://www.flickr.com/photos/ehue/23605723883/ Open dialog example. See attachment for the example CSV used. 2 : https://www.flickr.com/photos/ehue/23605723803/ External metadata insertion in template 3 : https://www.flickr.com/photos/ehue/24124478782/ External metadata rendering
BR,
Édouard
On Thu, Jan 7, 2016 at 3:25 PM, Arne Wossink wossink@wikimedia.nl wrote:
Hi Edouard,
Thank you for taking the time to respond!
The web start works for me; I had to whitelist the url in Java but otherwise it was fine. So as I said, I have trouble connecting an image with metadata on that image from a CSV file. It might already be helpful if you have some screen shots on how that works. If I can get that to work, this will really be helpful for some of our upcoming GLAM-projects (and one on which I am working now, and for which I hope to do an upload soon).
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*:
- Bezoekadres:*
Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 15:13 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Hi Edouard,
Thank you, that was really helpful! I got the link between the image and the CSV to work. I will now start testing and adapting the template for the actual upload. I'll keep you updated.
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*: * Bezoekadres:* Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 17:11 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Ok, a quick answer then :)
Here is an example from an upload we made at Wikimedia France in september. Metadata matching is done against the last column of the CSV file, which contains the exact name of the picture file. It could be any information available in the EXIF as well.
In ComeOn!, in the "open pictures" dialog, first pick the CSV file. The combo box will update with the column titles from the file (there is a bug here that won't refresh the combo when you select a file again without closing the dialog). Fill in the right field the expression that selects the field from the picture metadata to match. It may be any EXIF field (as show in the left pane of the main window when displaying a picture) or a special value from a reserved keyword (I need to document these), as " file.name". [1] The "regular expression" and "substitution" fields may be used to transform the picture metadata before matching it against the file. The default is safe as it keeps the information as is, but you could use it to extract a part of the "fichier" column, add a prefix and a suffix and so on.
In the file description templates, metadata from the file may be inserted with this stance: "$external." appended with the CSV column title. After loading the pictures, if the matching was succesful, the "content" tab should show a proper page.
1 : https://www.flickr.com/photos/ehue/23605723883/ Open dialog example. See attachment for the example CSV used. 2 : https://www.flickr.com/photos/ehue/23605723803/ External metadata insertion in template 3 : https://www.flickr.com/photos/ehue/24124478782/ External metadata rendering
BR,
Édouard
On Thu, Jan 7, 2016 at 3:25 PM, Arne Wossink wossink@wikimedia.nl wrote:
Hi Edouard,
Thank you for taking the time to respond!
The web start works for me; I had to whitelist the url in Java but otherwise it was fine. So as I said, I have trouble connecting an image with metadata on that image from a CSV file. It might already be helpful if you have some screen shots on how that works. If I can get that to work, this will really be helpful for some of our upcoming GLAM-projects (and one on which I am working now, and for which I hope to do an upload soon).
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*:
- Bezoekadres:*
Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 15:13 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Hi,
I finally completed the missing section of ComeOn's starter guide about external metadata: https://github.com/edouardhue/comeon/wiki/Demarrage.
I apologize for this guide not being translated in english yet. I'm getting in touch with translators at Wikimedia France to get things done.
I also plan to acquire a code signing certificate to get rid off Java's security warnings and cut a final release.
Meanwhile, I'm extremely interested in any kind of comment!
BR,
Édouard
On Fri, Jan 8, 2016 at 3:29 PM, Arne Wossink wossink@wikimedia.nl wrote:
Hi Edouard,
Thank you, that was really helpful! I got the link between the image and the CSV to work. I will now start testing and adapting the template for the actual upload. I'll keep you updated.
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*:
- Bezoekadres:*
Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 17:11 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Ok, a quick answer then :)
Here is an example from an upload we made at Wikimedia France in september. Metadata matching is done against the last column of the CSV file, which contains the exact name of the picture file. It could be any information available in the EXIF as well.
In ComeOn!, in the "open pictures" dialog, first pick the CSV file. The combo box will update with the column titles from the file (there is a bug here that won't refresh the combo when you select a file again without closing the dialog). Fill in the right field the expression that selects the field from the picture metadata to match. It may be any EXIF field (as show in the left pane of the main window when displaying a picture) or a special value from a reserved keyword (I need to document these), as " file.name". [1] The "regular expression" and "substitution" fields may be used to transform the picture metadata before matching it against the file. The default is safe as it keeps the information as is, but you could use it to extract a part of the "fichier" column, add a prefix and a suffix and so on.
In the file description templates, metadata from the file may be inserted with this stance: "$external." appended with the CSV column title. After loading the pictures, if the matching was succesful, the "content" tab should show a proper page.
1 : https://www.flickr.com/photos/ehue/23605723883/ Open dialog example. See attachment for the example CSV used. 2 : https://www.flickr.com/photos/ehue/23605723803/ External metadata insertion in template 3 : https://www.flickr.com/photos/ehue/24124478782/ External metadata rendering
BR,
Édouard
On Thu, Jan 7, 2016 at 3:25 PM, Arne Wossink wossink@wikimedia.nl wrote:
Hi Edouard,
Thank you for taking the time to respond!
The web start works for me; I had to whitelist the url in Java but otherwise it was fine. So as I said, I have trouble connecting an image with metadata on that image from a CSV file. It might already be helpful if you have some screen shots on how that works. If I can get that to work, this will really be helpful for some of our upcoming GLAM-projects (and one on which I am working now, and for which I hope to do an upload soon).
Best,
Arne Wossink
Projectleider / Project Lead Wikimedia Nederland
Tel. +31 (0)6 11000505 (di, wo, do)
*Postadres*:
- Bezoekadres:*
Postbus 167 Mariaplaats 3 3500 AD Utrecht Utrecht
2016-01-07 15:13 GMT+01:00 Edouard Hue edouard.hue@gmail.com:
Hi there,
I was notified that ComeOn! was discussed here. I'm the author :-) Thank you for your intereste in my humble tool.
ComeOn! used to work with OpenJDK. I did not check lastly though, but it has no dependency on Oracle's proprietary parts of the JDK and works with Oracle's JDK 8. Java Web Start might be a pain
I'm aware the most interesting part of the documentation part is missing. It was not such a problem as long as I was the only user, but times are changing. I'll do my best to write this part soon, but time is the critical resource. I'll try to send you later an exemple of how to use the feature.
BR,
Édouard
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Dear all,
In the Netherlands and elsewhere GLAMs pay companies like picturae.com to produce images of their collections, resulting in thousands of .tifs etcetera.
Up to now, as far as i know these company websites have not been whitelisted for uploads to Commons. It could be practical if GLAMs which want to donate images, can do so directly from such a company's domain. (A GLAM asked me whether to ask a scanning company to allow this from their company side.)
As i don't (yet) have a specific URL as a test, i can't at this point ask whitelisting on Phabricator. So i would like to test the waters here. If whitelisting of a company is a "no-no", it makes no sense aa company to allow this anyway. GLAMs (and I) must use other more indirect upload inroads.
* What's your view?
Thanks, hans muller
Hi,
From my point of view: certainly. Commons already has loads of images sourced from e.g. Flickr (and many GLAMs don't run their own servers but put media in commercial providers servers).
As long as the media objects have the correct file formats and licenses/rights status I don't see why it would matter that they're fetched from a server run by a commercial company.
Cheers, David
________________________________________ From: Glamtools [glamtools-bounces@lists.wikimedia.org] on behalf of Hans Muller [j.m.muller@hccnet.nl] Sent: 11 January 2016 17:45 To: Conversations revolving around the development of GLAM Digital Tools Subject: [Glamtools] Can commercial GLAM companiy domains be whitelisted for GWT?
Dear all,
In the Netherlands and elsewhere GLAMs pay companies like picturae.com to produce images of their collections, resulting in thousands of .tifs etcetera.
Up to now, as far as i know these company websites have not been whitelisted for uploads to Commons. It could be practical if GLAMs which want to donate images, can do so directly from such a company's domain. (A GLAM asked me whether to ask a scanning company to allow this from their company side.)
As i don't (yet) have a specific URL as a test, i can't at this point ask whitelisting on Phabricator. So i would like to test the waters here. If whitelisting of a company is a "no-no", it makes no sense aa company to allow this anyway. GLAMs (and I) must use other more indirect upload inroads.
* What's your view?
Thanks, hans muller
_______________________________________________ Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
+1
Op 11 jan. 2016, om 17:51 heeft David Haskiya david.haskiya@europeana.eu het volgende geschreven:
Hi, From my point of view: certainly. Commons already has loads of images sourced from e.g. Flickr (and many GLAMs don't run their own servers but put media in commercial providers servers).
As long as the media objects have the correct file formats and licenses/rights status I don't see why it would matter that they're fetched from a server run by a commercial company.
Cheers, David
From: Glamtools [glamtools-bounces@lists.wikimedia.org] on behalf of Hans Muller [j.m.muller@hccnet.nl] Sent: 11 January 2016 17:45 To: Conversations revolving around the development of GLAM Digital Tools Subject: [Glamtools] Can commercial GLAM companiy domains be whitelisted for GWT?
Dear all,
In the Netherlands and elsewhere GLAMs pay companies like picturae.com to produce images of their collections, resulting in thousands of .tifs etcetera.
Up to now, as far as i know these company websites have not been whitelisted for uploads to Commons. It could be practical if GLAMs which want to donate images, can do so directly from such a company's domain. (A GLAM asked me whether to ask a scanning company to allow this from their company side.)
As i don't (yet) have a specific URL as a test, i can't at this point ask whitelisting on Phabricator. So i would like to test the waters here. If whitelisting of a company is a "no-no", it makes no sense aa company to allow this anyway. GLAMs (and I) must use other more indirect upload inroads.
- What's your view?
Thanks, hans muller
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
To further David's point - Flickr.com staticflickr.com panoramio.com and two amazon web services urls
are all already whitelisted for the GWT. So, there are already several examples of commercially operated services that host freely-licensed media files being acceptable sources for the GWT.
-Liam
wittylama.com Peace, love & metadata
On 11 January 2016 at 17:52, Maarten Brinkerink wmnl@maartenbrinkerink.net wrote:
+1
Op 11 jan. 2016, om 17:51 heeft David Haskiya <
david.haskiya@europeana.eu> het volgende geschreven:
Hi, From my point of view: certainly. Commons already has loads of images
sourced from e.g. Flickr (and many GLAMs don't run their own servers but put media in commercial providers servers).
As long as the media objects have the correct file formats and
licenses/rights status I don't see why it would matter that they're fetched from a server run by a commercial company.
Cheers, David
From: Glamtools [glamtools-bounces@lists.wikimedia.org] on behalf of
Hans Muller [j.m.muller@hccnet.nl]
Sent: 11 January 2016 17:45 To: Conversations revolving around the development of GLAM Digital Tools Subject: [Glamtools] Can commercial GLAM companiy domains be whitelisted
for GWT?
Dear all,
In the Netherlands and elsewhere GLAMs pay companies like picturae.com
to
produce images of their collections, resulting in thousands of .tifs etcetera.
Up to now, as far as i know these company websites have not been whitelisted for uploads to Commons. It could be practical if GLAMs which want to donate images, can do so directly from such a company's domain.
(A
GLAM asked me whether to ask a scanning company to allow this from their company side.)
As i don't (yet) have a specific URL as a test, i can't at this point ask whitelisting on Phabricator. So i would like to test the waters here. If whitelisting of a company is a "no-no", it makes no sense aa company to allow this anyway. GLAMs (and I) must use other more indirect upload inroads.
- What's your view?
Thanks, hans muller
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains: * Is the bounce (click and immediately/quickly gone) component included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
Dear all,
I noticed that Baglama 2 mentioned a new service: an API. I am under the impression that the API is going to replace the current service. Does anyone know wether this is true? I tried to work with the API but I am not a JSON expert and so far got no understandable data…. Best wishes Lizzy Jongma, Rijksmuseum
On 18 Jan 2016, at 14:21, Hans Muller j.m.muller@hccnet.nl wrote:
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains:
- Is the bounce (click and immediately/quickly gone) component
included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
https://twitter.com/MagnusManske/status/686886792545615874 https://twitter.com/MagnusManske/status/686886792545615874
Op 18 jan. 2016, om 14:28 heeft Lizzy Jongma L.Jongma@rijksmuseum.nl het volgende geschreven:
Dear all,
I noticed that Baglama 2 mentioned a new service: an API. I am under the impression that the API is going to replace the current service. Does anyone know wether this is true? I tried to work with the API but I am not a JSON expert and so far got no understandable data…. Best wishes Lizzy Jongma, Rijksmuseum
On 18 Jan 2016, at 14:21, Hans Muller j.m.muller@hccnet.nl wrote:
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains:
- Is the bounce (click and immediately/quickly gone) component
included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
As far as i can see, the API does not answer the bounce question.
Please, does some one know if bounce is included in the numbers? Thanks, regards, hansmuller
Op Ma, 18 januari, 2016 2:31 pm schreef Maarten Brinkerink:
https://twitter.com/MagnusManske/status/686886792545615874 https://twitter.com/MagnusManske/status/686886792545615874
Op 18 jan. 2016, om 14:28 heeft Lizzy Jongma L.Jongma@rijksmuseum.nl het volgende geschreven:
Dear all,
I noticed that Baglama 2 mentioned a new service: an API. I am under the impression that the API is going to replace the current service. Does anyone know wether this is true? I tried to work with the API but I am not a JSON expert and so far got no understandable dataâ¦. Best wishes Lizzy Jongma, Rijksmuseum
On 18 Jan 2016, at 14:21, Hans Muller j.m.muller@hccnet.nl wrote:
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains:
- Is the bounce (click and immediately/quickly gone) component
included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
I am so free as to start a new thread for Lizzy, to keep questions about API and Bounce separate
hansmuller
Op Ma, 18 januari, 2016 2:31 pm schreef Maarten Brinkerink:
https://twitter.com/MagnusManske/status/686886792545615874 https://twitter.com/MagnusManske/status/686886792545615874
Op 18 jan. 2016, om 14:28 heeft Lizzy Jongma L.Jongma@rijksmuseum.nl het volgende geschreven:
Dear all,
I noticed that Baglama 2 mentioned a new service: an API. I am under the impression that the API is going to replace the current service. Does anyone know wether this is true? I tried to work with the API but I am not a JSON expert and so far got no understandable dataâ¦. Best wishes Lizzy Jongma, Rijksmuseum
On 18 Jan 2016, at 14:21, Hans Muller j.m.muller@hccnet.nl wrote:
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains:
- Is the bounce (click and immediately/quickly gone) component
included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Hans Muller, 18/01/2016 14:52:
As far as i can see, the API does not answer the bounce question.
The API talks of pageviews https://wikitech.wikimedia.org/wiki/pageviews_API ; your question is IMHO the wrong one, i.e. "how can we estimate how many pageviews are real?". The real question is "how many times are the files actually seen?".
To answer the real question, you have to use mediacounts instead: https://wikitech.wikimedia.org/wiki/Analytics/Data/Mediacounts You can see an example at http://wiki.wikimedia.it/wiki/File:2015-10-beic-counts.ods The results are very similar to what baglama yields, for this specific case (BEIC media).
Nemo
OK, I am not sure I understand the issue correctly, so I'll just throw out some notes:
* I do not count the pageviews. They are counted by the Wikimedia Foundation, I just use them as-is.
* The official definition of page views seems to be at https://wikitech.wikimedia.org/wiki/Analytics/Pageviews
* AFAIK, the data before 2015-12 used only desktop views; the new one uses also mobile, but removes "views" by bots and crawlers.
* Not sure what the "bounce" feature is; the preview thing in the mobile app? Or the MediaViewer? (I believe page views count neither of those)
Finally, a "view" in the baglama2 tool means an image was included on a page that a human loaded in his/her browser. I have no data if that image was actually on the screen ("below the fold", no scrolling), but since "important" images in an article tend to be near the top, I just count the page view.
Hope that helps, Magnus
On Mon, Jan 18, 2016 at 2:19 PM Federico Leva (Nemo) nemowiki@gmail.com wrote:
Hans Muller, 18/01/2016 14:52:
As far as i can see, the API does not answer the bounce question.
The API talks of pageviews https://wikitech.wikimedia.org/wiki/pageviews_API ; your question is IMHO the wrong one, i.e. "how can we estimate how many pageviews are real?". The real question is "how many times are the files actually seen?".
To answer the real question, you have to use mediacounts instead: https://wikitech.wikimedia.org/wiki/Analytics/Data/Mediacounts You can see an example at http://wiki.wikimedia.it/wiki/File:2015-10-beic-counts.ods The results are very similar to what baglama yields, for this specific case (BEIC media).
Nemo
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Dear Federico and Magnus,
Thank you for your links and further help.
Perhaps WMF is not that obsessed with dwell time of a surfer on a webpage, as are commercial websites and so Google Analytics with its concept of bounce: the user request of another webpage within a sec, an immediate rejection of the webpage.
Or perhaps this cannot be logged server-side.
Best regards, hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
Op Ma, 18 januari, 2016 9:49 pm schreef Magnus Manske:
OK, I am not sure I understand the issue correctly, so I'll just throw out some notes:
- I do not count the pageviews. They are counted by the Wikimedia
Foundation, I just use them as-is.
- The official definition of page views seems to be at
https://wikitech.wikimedia.org/wiki/Analytics/Pageviews
- AFAIK, the data before 2015-12 used only desktop views; the new one
uses also mobile, but removes "views" by bots and crawlers.
- Not sure what the "bounce" feature is; the preview thing in the mobile
app? Or the MediaViewer? (I believe page views count neither of those)
Finally, a "view" in the baglama2 tool means an image was included on a page that a human loaded in his/her browser. I have no data if that image was actually on the screen ("below the fold", no scrolling), but since "important" images in an article tend to be near the top, I just count the page view.
Hope that helps, Magnus
On Mon, Jan 18, 2016 at 2:19 PM Federico Leva (Nemo) nemowiki@gmail.com wrote:
Hans Muller, 18/01/2016 14:52:
As far as i can see, the API does not answer the bounce question.
The API talks of pageviews https://wikitech.wikimedia.org/wiki/pageviews_API ; your question is IMHO the wrong one, i.e. "how can we estimate how many pageviews are real?". The real question is "how many times are the files actually seen?".
To answer the real question, you have to use mediacounts instead: https://wikitech.wikimedia.org/wiki/Analytics/Data/Mediacounts You can see an example at http://wiki.wikimedia.it/wiki/File:2015-10-beic-counts.ods The results are very similar to what baglama yields, for this specific case (BEIC media).
Nemo
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Seconding: yes, this ‘bounce’ concept is extremely important in web analytics and it’s a core metric in Google Analytics. It makes a huge difference if a user clicks away after less than a second, or reads just a bit, or spends several minutes reading a webpage.
On 25 Jan 2016, at 11:46, Hans Muller j.m.muller@hccnet.nl wrote:
Dear Federico and Magnus,
Thank you for your links and further help.
Perhaps WMF is not that obsessed with dwell time of a surfer on a webpage, as are commercial websites and so Google Analytics with its concept of bounce: the user request of another webpage within a sec, an immediate rejection of the webpage.
Or perhaps this cannot be logged server-side.
Best regards, hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
Op Ma, 18 januari, 2016 9:49 pm schreef Magnus Manske:
OK, I am not sure I understand the issue correctly, so I'll just throw out some notes:
- I do not count the pageviews. They are counted by the Wikimedia
Foundation, I just use them as-is.
- The official definition of page views seems to be at
https://wikitech.wikimedia.org/wiki/Analytics/Pageviews
- AFAIK, the data before 2015-12 used only desktop views; the new one
uses also mobile, but removes "views" by bots and crawlers.
- Not sure what the "bounce" feature is; the preview thing in the mobile
app? Or the MediaViewer? (I believe page views count neither of those)
Finally, a "view" in the baglama2 tool means an image was included on a page that a human loaded in his/her browser. I have no data if that image was actually on the screen ("below the fold", no scrolling), but since "important" images in an article tend to be near the top, I just count the page view.
Hope that helps, Magnus
On Mon, Jan 18, 2016 at 2:19 PM Federico Leva (Nemo) nemowiki@gmail.com wrote:
Hans Muller, 18/01/2016 14:52:
As far as i can see, the API does not answer the bounce question.
The API talks of pageviews https://wikitech.wikimedia.org/wiki/pageviews_API ; your question is IMHO the wrong one, i.e. "how can we estimate how many pageviews are real?". The real question is "how many times are the files actually seen?".
To answer the real question, you have to use mediacounts instead: https://wikitech.wikimedia.org/wiki/Analytics/Data/Mediacounts You can see an example at http://wiki.wikimedia.it/wiki/File:2015-10-beic-counts.ods The results are very similar to what baglama yields, for this specific case (BEIC media).
Nemo
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
I imagine it more has to do with privacy concerns. I assume (might be wrong, not really knowlegable about this area) to track bounce rate we need to uniquely identify each user, including logged out users. I imagine including that type of user tracking, well probably not totally out of the question, would be quite a hot-button issue with our userbase.
-- bawolff
On Monday, January 25, 2016, Hans Muller j.m.muller@hccnet.nl wrote:
Dear Federico and Magnus,
Thank you for your links and further help.
Perhaps WMF is not that obsessed with dwell time of a surfer on a webpage, as are commercial websites and so Google Analytics with its concept of bounce: the user request of another webpage within a sec, an immediate rejection of the webpage.
Or perhaps this cannot be logged server-side.
Best regards, hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
Op Ma, 18 januari, 2016 9:49 pm schreef Magnus Manske:
OK, I am not sure I understand the issue correctly, so I'll just throw out some notes:
- I do not count the pageviews. They are counted by the Wikimedia
Foundation, I just use them as-is.
- The official definition of page views seems to be at
https://wikitech.wikimedia.org/wiki/Analytics/Pageviews
- AFAIK, the data before 2015-12 used only desktop views; the new one
uses also mobile, but removes "views" by bots and crawlers.
- Not sure what the "bounce" feature is; the preview thing in the mobile
app? Or the MediaViewer? (I believe page views count neither of those)
Finally, a "view" in the baglama2 tool means an image was included on a page that a human loaded in his/her browser. I have no data if that image was actually on the screen ("below the fold", no scrolling), but since "important" images in an article tend to be near the top, I just count the page view.
Hope that helps, Magnus
On Mon, Jan 18, 2016 at 2:19 PM Federico Leva (Nemo) nemowiki@gmail.com wrote:
Hans Muller, 18/01/2016 14:52:
As far as i can see, the API does not answer the bounce question.
The API talks of pageviews https://wikitech.wikimedia.org/wiki/pageviews_API ; your question is IMHO the wrong one, i.e. "how can we estimate how many pageviews are real?". The real question is "how many times are the files actually seen?".
To answer the real question, you have to use mediacounts instead: https://wikitech.wikimedia.org/wiki/Analytics/Data/Mediacounts You can see an example at http://wiki.wikimedia.it/wiki/File:2015-10-beic-counts.ods The results are very similar to what baglama yields, for this specific case (BEIC media).
Nemo
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Thanks Maarten! I read this tweet but think I misunderstood the message. I thought the human readable version would be replaced by the JSON API.
Thanks Best wishes Lizzy On 18 Jan 2016, at 14:31, Maarten Brinkerink <wmnl@maartenbrinkerink.netmailto:wmnl@maartenbrinkerink.net> wrote:
https://twitter.com/MagnusManske/status/686886792545615874
Op 18 jan. 2016, om 14:28 heeft Lizzy Jongma <L.Jongma@rijksmuseum.nlmailto:L.Jongma@rijksmuseum.nl> het volgende geschreven:
Dear all,
I noticed that Baglama 2 mentioned a new service: an API. I am under the impression that the API is going to replace the current service. Does anyone know wether this is true? I tried to work with the API but I am not a JSON expert and so far got no understandable data…. Best wishes Lizzy Jongma, Rijksmuseum On 18 Jan 2016, at 14:21, Hans Muller <j.m.muller@hccnet.nlmailto:j.m.muller@hccnet.nl> wrote:
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains: * Is the bounce (click and immediately/quickly gone) component included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
_______________________________________________ Glamtools mailing list Glamtools@lists.wikimedia.orgmailto:Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
_______________________________________________ Glamtools mailing list Glamtools@lists.wikimedia.orgmailto:Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
_______________________________________________ Glamtools mailing list Glamtools@lists.wikimedia.orgmailto:Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
The problem was that Magnus didn't reply to my mail...., Cheers, Hansmuller
Op Ma, 18 januari, 2016 3:04 pm schreef Lizzy Jongma:
Thanks Maarten! I read this tweet but think I misunderstood the message. I thought the human readable version would be replaced by the JSON API.
Thanks Best wishes Lizzy On 18 Jan 2016, at 14:31, Maarten Brinkerink <wmnl@maartenbrinkerink.netmailto:wmnl@maartenbrinkerink.net> wrote:
https://twitter.com/MagnusManske/status/686886792545615874
Op 18 jan. 2016, om 14:28 heeft Lizzy Jongma <L.Jongma@rijksmuseum.nlmailto:L.Jongma@rijksmuseum.nl> het volgende geschreven:
Dear all,
I noticed that Baglama 2 mentioned a new service: an API. I am under the impression that the API is going to replace the current service. Does anyone know wether this is true? I tried to work with the API but I am not a JSON expert and so far got no understandable dataâ¦. Best wishes Lizzy Jongma, Rijksmuseum On 18 Jan 2016, at 14:21, Hans Muller <j.m.muller@hccnet.nlmailto:j.m.muller@hccnet.nl> wrote:
Dear all,
Magnus' tool BaGLAMa 2 (detailed Pageview analysis) is extremely valuable to track interest for GLAM donations, and to convince GLAMs how useful their donation is or could be.
One question remains:
- Is the bounce (click and immediately/quickly gone) component
included/excluded in the number of pageviews?
I always thought that bounce was included because it is much harder to exclude it, so i used the numbers with a caveat and only relatively to each other, but then perhaps the tool tacitly assumes that a pageview only counts when the dwell time exceeds say ...?? sec?
With Google analytics on other websites one finds that the bounce component routinely is of the order of 30%, so perhaps for wikimedia sites the same amount holds.
Perhaps someone knows, thanks and best regards,
User:Hansmuller https://commons.wikimedia.org/wiki/User:Hansmuller
PS Example: https://tools.wmflabs.org/glamtools/baglama2/#gid=205&month=201512
with many pageviews thanks to the often-clicked article Mumbai
Glamtools mailing list Glamtools@lists.wikimedia.orgmailto:Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.orgmailto:Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.orgmailto:Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
Glamtools mailing list Glamtools@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/glamtools
{kind=link}
{kind=link}
{kind=link}