Including the analytics team in case they have a magical solution to our problem.
Currently, our graphs display the mean and standard deviation of metrics, as provided in "mean" and "std" columns coming from our tsvs, generated based on EventLogging data: http://multimedia-metrics.wmflabs.org/dashboards/mmv However we already see that extreme outliers can make the standard deviation and mean skyrocket and as a result make the graphs useless for some metrics. See France, for example, for which a single massive value was able to skew the map into making the country look problematic: http://multimedia-metrics.wmflabs.org/dashboards/mmv#geographical_network_pe... no performance issue with France, but the graph suggests that is the case because of that one outlier.
Ideally, instead of using the mean for our graphs, we would be using what is called the "trimmed mean", i.e. the mean of all values excluding the upper and lower X percentiles. Unfortunately, MariaDB doesn't provide that as a function and calculating it with SQL can be surprisingly complicated, especially since we often have to group values for a given column. The best alternative I could come up with so far for our geographical queries was to exclude values that differ more than X times the standard deviation from the mean. It kind of flattens the mean. It's not ideal, because I think that in the context of our graphs it makes things look like they perform better than they really do.
I think the main issue at the moment is that we're using a shell script to pipe a SQL request directly from db1047 to a tsv file. That limits us to one giant SQL query, and since we don't have the ability to create temporary tables on the log database with the research_prod user, we can't preprocess the data in multiple queries to filter out the upper and lower percentiles. The trimmed mean would be kind of feasible as a single complicated query if it wasn't for the GROUP BY: http://stackoverflow.com/a/8909568
So, my latest idea for a solution is to write a python script that will import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Sending it to the right Analytics email address....
On Wed, Apr 16, 2014 at 1:22 PM, Gilles Dubuc gilles@wikimedia.org wrote:
Including the analytics team in case they have a magical solution to our problem.
Currently, our graphs display the mean and standard deviation of metrics, as provided in "mean" and "std" columns coming from our tsvs, generated based on EventLogging data: http://multimedia-metrics.wmflabs.org/dashboards/mmv However we already see that extreme outliers can make the standard deviation and mean skyrocket and as a result make the graphs useless for some metrics. See France, for example, for which a single massive value was able to skew the map into making the country look problematic: http://multimedia-metrics.wmflabs.org/dashboards/mmv#geographical_network_pe... no performance issue with France, but the graph suggests that is the case because of that one outlier.
Ideally, instead of using the mean for our graphs, we would be using what is called the "trimmed mean", i.e. the mean of all values excluding the upper and lower X percentiles. Unfortunately, MariaDB doesn't provide that as a function and calculating it with SQL can be surprisingly complicated, especially since we often have to group values for a given column. The best alternative I could come up with so far for our geographical queries was to exclude values that differ more than X times the standard deviation from the mean. It kind of flattens the mean. It's not ideal, because I think that in the context of our graphs it makes things look like they perform better than they really do.
I think the main issue at the moment is that we're using a shell script to pipe a SQL request directly from db1047 to a tsv file. That limits us to one giant SQL query, and since we don't have the ability to create temporary tables on the log database with the research_prod user, we can't preprocess the data in multiple queries to filter out the upper and lower percentiles. The trimmed mean would be kind of feasible as a single complicated query if it wasn't for the GROUP BY: http://stackoverflow.com/a/8909568
So, my latest idea for a solution is to write a python script that will import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
So, my latest idea for a solution is to write a python script that will
import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Well, I think this sounds like we need to seriously evaluate how people are using EventLogging data and provide this sort of analysis as a feature. We'd have to hear from more people but I bet it's the right thing to do long term.
Meanwhile, "simple" is highly subjective here. If it was me, I'd clean up the indentation of that giant SQL query you have, then maybe figure out some ways to make it faster, then be happy as a clam. So if sql-lite is the tool you feel happy as a clam with, then that sounds like a great solution. Alternatives would be python, php, etc. I forgot if pandas was allowed where you're working but that's a great python library that would make what you're talking about fairly easy.
Another thing for us to seriously consider is PostgreSQL. This has proper f-ing temporary tables and supports actual people doing actual work with databases. We could dump data, especially really simple schemas like EventLogging, into PostgreSQL for analysis.
Hi Gilles,
I think I know just the thing you're looking for.
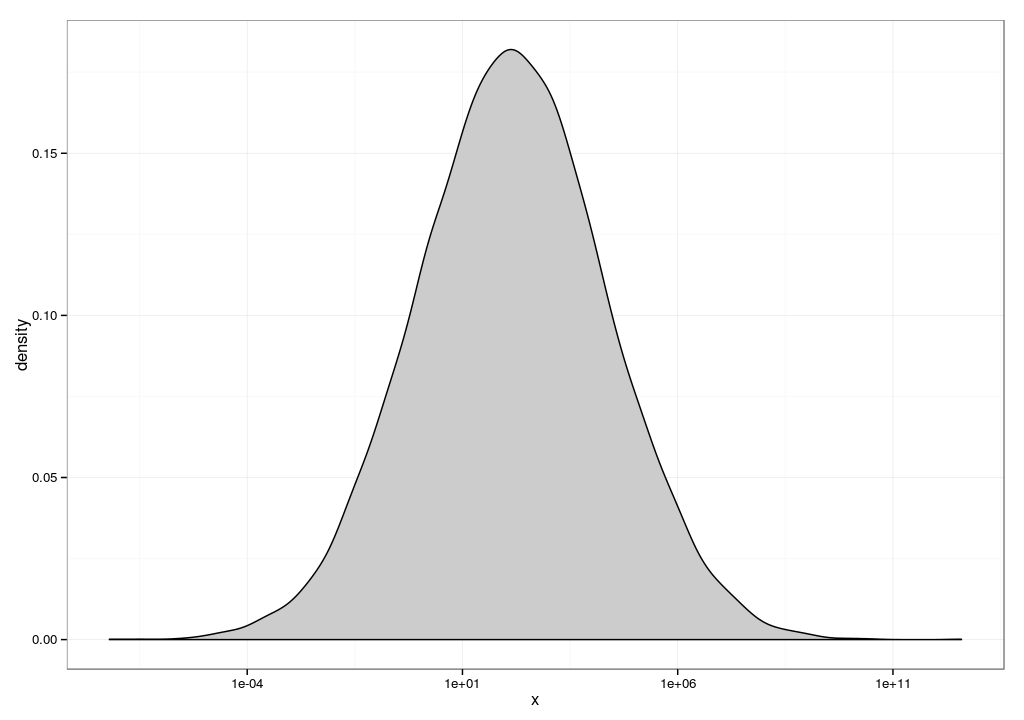
It turns out that much of this performance data is log-normally distributed[1]. Log-normal distributions tend to have a hockey stick shape where most of the values are close to zero, but occasionally very large values appear[3]. Taking the mean of a log-normal distributions tend to be sensitive to outliers like the ones you describe.
A solution to this problem is to generate a geometric mean[2] instead. One convenient thing about log-normal data is that if you log() it, it becomes normal[4] -- and not sensitive to outliers in the usual way. Also convenient, geometric means are super easy to generate. All you need to do is this: (1) pass all of the data through log() (2) pass the same data through mean() (or avg() -- whatever) (3) pass the result through exp(). The best thing about this is that you can do it in MySQL.
For example:
SELECT country, mean(timings) AS regular_mean, exp(log(mean(timings)) AS geomteric_mean FROM log.WhateverSchemaYouveGot GROUP BY country
1. https://en.wikipedia.org/wiki/Log-normal_distribution 2. https://en.wikipedia.org/wiki/Geometric_mean 3. See distribution.log_normal.svg (24K)https://mail.google.com/mail/u/0/?ui=2&ik=1aecb4a505&view=att&th=1456ae573a3290c5&attid=0.3&disp=safe&realattid=f_hu2pcu3b2&zw 4. See distribution.log_normal.logged.svg (33K)https://mail.google.com/mail/u/0/?ui=2&ik=1aecb4a505&view=att&th=1456ae58ec7e1f69&attid=0.2&disp=safe&realattid=f_hu2pcu311&zw
-Aaron
On Wed, Apr 16, 2014 at 8:42 AM, Dan Andreescu dandreescu@wikimedia.orgwrote:
So, my latest idea for a solution is to write a python script that will
import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Well, I think this sounds like we need to seriously evaluate how people are using EventLogging data and provide this sort of analysis as a feature. We'd have to hear from more people but I bet it's the right thing to do long term.
Meanwhile, "simple" is highly subjective here. If it was me, I'd clean up the indentation of that giant SQL query you have, then maybe figure out some ways to make it faster, then be happy as a clam. So if sql-lite is the tool you feel happy as a clam with, then that sounds like a great solution. Alternatives would be python, php, etc. I forgot if pandas was allowed where you're working but that's a great python library that would make what you're talking about fairly easy.
Another thing for us to seriously consider is PostgreSQL. This has proper f-ing temporary tables and supports actual people doing actual work with databases. We could dump data, especially really simple schemas like EventLogging, into PostgreSQL for analysis.
Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
The SVGs plots I made don't show up well in gmail, so here's some PNGs
On Wed, Apr 16, 2014 at 9:24 AM, Aaron Halfaker ahalfaker@wikimedia.orgwrote:
Hi Gilles,
I think I know just the thing you're looking for.
It turns out that much of this performance data is log-normally distributed[1]. Log-normal distributions tend to have a hockey stick shape where most of the values are close to zero, but occasionally very large values appear[3]. Taking the mean of a log-normal distributions tend to be sensitive to outliers like the ones you describe.
A solution to this problem is to generate a geometric mean[2] instead. One convenient thing about log-normal data is that if you log() it, it becomes normal[4] -- and not sensitive to outliers in the usual way. Also convenient, geometric means are super easy to generate. All you need to do is this: (1) pass all of the data through log() (2) pass the same data through mean() (or avg() -- whatever) (3) pass the result through exp(). The best thing about this is that you can do it in MySQL.
For example:
SELECT country, mean(timings) AS regular_mean, exp(log(mean(timings)) AS geomteric_mean FROM log.WhateverSchemaYouveGot GROUP BY country
- https://en.wikipedia.org/wiki/Log-normal_distribution
- https://en.wikipedia.org/wiki/Geometric_mean
- See distribution.log_normal.svg (24K)https://mail.google.com/mail/u/0/?ui=2&ik=1aecb4a505&view=att&th=1456ae573a3290c5&attid=0.3&disp=safe&realattid=f_hu2pcu3b2&zw
- See distribution.log_normal.logged.svg (33K)https://mail.google.com/mail/u/0/?ui=2&ik=1aecb4a505&view=att&th=1456ae58ec7e1f69&attid=0.2&disp=safe&realattid=f_hu2pcu311&zw
-Aaron
On Wed, Apr 16, 2014 at 8:42 AM, Dan Andreescu dandreescu@wikimedia.orgwrote:
So, my latest idea for a solution is to write a python script that will
import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Well, I think this sounds like we need to seriously evaluate how people are using EventLogging data and provide this sort of analysis as a feature. We'd have to hear from more people but I bet it's the right thing to do long term.
Meanwhile, "simple" is highly subjective here. If it was me, I'd clean up the indentation of that giant SQL query you have, then maybe figure out some ways to make it faster, then be happy as a clam. So if sql-lite is the tool you feel happy as a clam with, then that sounds like a great solution. Alternatives would be python, php, etc. I forgot if pandas was allowed where you're working but that's a great python library that would make what you're talking about fairly easy.
Another thing for us to seriously consider is PostgreSQL. This has proper f-ing temporary tables and supports actual people doing actual work with databases. We could dump data, especially really simple schemas like EventLogging, into PostgreSQL for analysis.
Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
Nice Aaron!
On Apr 16, 2014, at 7:26 AM, Aaron Halfaker ahalfaker@wikimedia.org wrote:
The SVGs plots I made don't show up well in gmail, so here's some PNGs
On Wed, Apr 16, 2014 at 9:24 AM, Aaron Halfaker ahalfaker@wikimedia.org wrote: Hi Gilles,
I think I know just the thing you're looking for.
It turns out that much of this performance data is log-normally distributed[1]. Log-normal distributions tend to have a hockey stick shape where most of the values are close to zero, but occasionally very large values appear[3]. Taking the mean of a log-normal distributions tend to be sensitive to outliers like the ones you describe.
A solution to this problem is to generate a geometric mean[2] instead. One convenient thing about log-normal data is that if you log() it, it becomes normal[4] -- and not sensitive to outliers in the usual way. Also convenient, geometric means are super easy to generate. All you need to do is this: (1) pass all of the data through log() (2) pass the same data through mean() (or avg() -- whatever) (3) pass the result through exp(). The best thing about this is that you can do it in MySQL.
For example:
SELECT country, mean(timings) AS regular_mean, exp(log(mean(timings)) AS geomteric_mean FROM log.WhateverSchemaYouveGot GROUP BY country
- https://en.wikipedia.org/wiki/Log-normal_distribution
- https://en.wikipedia.org/wiki/Geometric_mean
- See distribution.log_normal.svg (24K)
- See distribution.log_normal.logged.svg (33K)
-Aaron
On Wed, Apr 16, 2014 at 8:42 AM, Dan Andreescu dandreescu@wikimedia.org wrote:
So, my latest idea for a solution is to write a python script that will import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... which can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Well, I think this sounds like we need to seriously evaluate how people are using EventLogging data and provide this sort of analysis as a feature. We'd have to hear from more people but I bet it's the right thing to do long term.
Meanwhile, "simple" is highly subjective here. If it was me, I'd clean up the indentation of that giant SQL query you have, then maybe figure out some ways to make it faster, then be happy as a clam. So if sql-lite is the tool you feel happy as a clam with, then that sounds like a great solution. Alternatives would be python, php, etc. I forgot if pandas was allowed where you're working but that's a great python library that would make what you're talking about fairly easy.
Another thing for us to seriously consider is PostgreSQL. This has proper f-ing temporary tables and supports actual people doing actual work with databases. We could dump data, especially really simple schemas like EventLogging, into PostgreSQL for analysis.
Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
<distribution.log_normal.logged.png> <distribution.log_normal.png> _______________________________________________ Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
On Wed, Apr 16, 2014 at 7:24 AM, Aaron Halfaker ahalfaker@wikimedia.orgwrote:
It turns out that much of this performance data is log-normally distributed[1]. Log-normal distributions tend to have a hockey stick shape where most of the values are close to zero, but occasionally very large values appear[3]. Taking the mean of a log-normal distributions tend to be sensitive to outliers like the ones you describe.
A solution to this problem is to generate a geometric mean[2] instead. One convenient thing about log-normal data is that if you log() it, it becomes normal[4] -- and not sensitive to outliers in the usual way. Also convenient, geometric means are super easy to generate. All you need to do is this: (1) pass all of the data through log() (2) pass the same data through mean() (or avg() -- whatever) (3) pass the result through exp(). The best thing about this is that you can do it in MySQL.
For example:
SELECT country, mean(timings) AS regular_mean, exp(log(mean(timings)) AS geomteric_mean FROM log.WhateverSchemaYouveGot GROUP BY country
Thanks, that sounds super simple!
What about quantiles in general? Even if the outlier issue is solved, we planned to have stats like speed of image display in the 90th percentile, and that still poses the same SQL problem. Or are quantiles unhelpful for lognormal distributions in general?
I'd say quantiles are a great idea for describing data of any distribution. They're hard/impossible to do in SQL though.
On Wed, Apr 16, 2014 at 2:09 PM, Gergo Tisza gtisza@wikimedia.org wrote:
On Wed, Apr 16, 2014 at 7:24 AM, Aaron Halfaker ahalfaker@wikimedia.orgwrote:
It turns out that much of this performance data is log-normally distributed[1]. Log-normal distributions tend to have a hockey stick shape where most of the values are close to zero, but occasionally very large values appear[3]. Taking the mean of a log-normal distributions tend to be sensitive to outliers like the ones you describe.
A solution to this problem is to generate a geometric mean[2] instead. One convenient thing about log-normal data is that if you log() it, it becomes normal[4] -- and not sensitive to outliers in the usual way. Also convenient, geometric means are super easy to generate. All you need to do is this: (1) pass all of the data through log() (2) pass the same data through mean() (or avg() -- whatever) (3) pass the result through exp(). The best thing about this is that you can do it in MySQL.
For example:
SELECT country, mean(timings) AS regular_mean, exp(log(mean(timings)) AS geomteric_mean FROM log.WhateverSchemaYouveGot GROUP BY country
Thanks, that sounds super simple!
What about quantiles in general? Even if the outlier issue is solved, we planned to have stats like speed of image display in the 90th percentile, and that still poses the same SQL problem. Or are quantiles unhelpful for lognormal distributions in general?
Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
A solution to this problem is to generate a geometric mean[2] instead.
Thanks a lot for the help, it literally instantly solved my problem!
There was a small mistake in the order of functions in your example, for the record it should be:
EXP(AVG(LOG(event_total))) AS geometric_mean
And conveniently the geometric standard deviation can be calculated the same way:
EXP(STDDEV(LOG(event_total))) AS geometric_stddev
I put it to the test on a specific set of data where we had a huge outlier, and for that data it seems equivalent to excluding the lower and upper 10 percentiles, which is exactly what I was after.
On Wed, Apr 16, 2014 at 4:24 PM, Aaron Halfaker ahalfaker@wikimedia.orgwrote:
Hi Gilles,
I think I know just the thing you're looking for.
It turns out that much of this performance data is log-normally distributed[1]. Log-normal distributions tend to have a hockey stick shape where most of the values are close to zero, but occasionally very large values appear[3]. Taking the mean of a log-normal distributions tend to be sensitive to outliers like the ones you describe.
A solution to this problem is to generate a geometric mean[2] instead. One convenient thing about log-normal data is that if you log() it, it becomes normal[4] -- and not sensitive to outliers in the usual way. Also convenient, geometric means are super easy to generate. All you need to do is this: (1) pass all of the data through log() (2) pass the same data through mean() (or avg() -- whatever) (3) pass the result through exp(). The best thing about this is that you can do it in MySQL.
For example:
SELECT country, mean(timings) AS regular_mean, exp(log(mean(timings)) AS geomteric_mean FROM log.WhateverSchemaYouveGot GROUP BY country
- https://en.wikipedia.org/wiki/Log-normal_distribution
- https://en.wikipedia.org/wiki/Geometric_mean
- See distribution.log_normal.svg (24K)https://mail.google.com/mail/u/0/?ui=2&ik=1aecb4a505&view=att&th=1456ae573a3290c5&attid=0.3&disp=safe&realattid=f_hu2pcu3b2&zw
- See distribution.log_normal.logged.svg (33K)https://mail.google.com/mail/u/0/?ui=2&ik=1aecb4a505&view=att&th=1456ae58ec7e1f69&attid=0.2&disp=safe&realattid=f_hu2pcu311&zw
-Aaron
On Wed, Apr 16, 2014 at 8:42 AM, Dan Andreescu dandreescu@wikimedia.orgwrote:
So, my latest idea for a solution is to write a python script that will
import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Well, I think this sounds like we need to seriously evaluate how people are using EventLogging data and provide this sort of analysis as a feature. We'd have to hear from more people but I bet it's the right thing to do long term.
Meanwhile, "simple" is highly subjective here. If it was me, I'd clean up the indentation of that giant SQL query you have, then maybe figure out some ways to make it faster, then be happy as a clam. So if sql-lite is the tool you feel happy as a clam with, then that sounds like a great solution. Alternatives would be python, php, etc. I forgot if pandas was allowed where you're working but that's a great python library that would make what you're talking about fairly easy.
Another thing for us to seriously consider is PostgreSQL. This has proper f-ing temporary tables and supports actual people doing actual work with databases. We could dump data, especially really simple schemas like EventLogging, into PostgreSQL for analysis.
Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
Analytics mailing list Analytics@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/analytics
On Wed, Apr 16, 2014 at 6:42 AM, Dan Andreescu dandreescu@wikimedia.orgwrote:
So, my latest idea for a solution is to write a python script that will
import the section (last X days) of data from the EventLogging tables that we're interested in into a temporary sqlite database, then proceed with removing the upper and lower percentiles of the data, according to any column grouping that might be necessary. And finally, once the data preprocessing is done in sqlite, run similar queries as before to export the mean, standard deviation, etc. for given metrics to tsvs. I think using sqlite is cleaner than doing the preprocessing on db1047 anyway.
It's quite an undertaking, it basically means rewriting all our current SQL => TSV conversion. The ability to use more steps in the conversion means that we'd be able to have simpler, more readable SQL queries. It would also be a good opportunity to clean up the giant performance query with a bazillion JOINS: https://gitorious.org/analytics/multimedia/source/a949b1c8723c4c41700cedf6e9... can actually be divided into several data sources all used in the same graph.
Does that sound like a good idea, or is there a simpler solution out there that someone can think of?
Well, I think this sounds like we need to seriously evaluate how people are using EventLogging data and provide this sort of analysis as a feature. We'd have to hear from more people but I bet it's the right thing to do long term.
Yes, I think so too. We used to pipe the data into a MongoDB instance (besides being the butt of webscale jokes, MongoDB does have an expressive query framework) but I wasn't able to convince anyone to use it, so I quietly decommissioned it at one point. It has been missed by no one.
When I have to produce summary statistics these days, I use Pandas and IPython, either reading the data directly from db1047 to a DataFrame object or dumping the table to a CSV file first and using that. (See < http://pandas.pydata.org/pandas-docs/stable/io.html%3E)
It'd be nice if stat1001 (or whatevever) had simple packages in Python and R (and maybe Julia) that knew about db1047 and the credentials required for accessing it, and provided some simple API for retrieving EventLogging datasets. I used to have this set up with IPython (I think Aaron and Dario used it briefly) but I didn't have the chance to polish it and drive adoption.
The other database backends that I think are worth considering are RethinkDB (document-oriented, http://rethinkdb.com/) and BayesDB (table-oriented, http://probcomp.csail.mit.edu/bayesdb/).
RethinkDB has the nicest query interface of all the document-oriented databases I know of. See < http://rethinkdb.com/docs/cookbook/python/#computing-the-average-value-of-a-... to get a taste.
Postgres's support for column-oriented data is really interesting, but my hunch is that it won't provide enough of an edge over MariaDB to win people over. Everyone is familiar with MariaDB / MySQL's dialect of SQL, and you're already forced to use it by dint of it being the primary backend of Wikimedia wikis.
I am still really excited by this, and it remains an open requirement for a lot of performance analysis work, so if there was interest from the analytics team, I'd be very happy to collaborate. The pubsub setup of EventLogging makes it very easy to pipe the data into a new medium without perturbing the existing setup.
multimedia@lists.wikimedia.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}