There seem to be weird things going on.
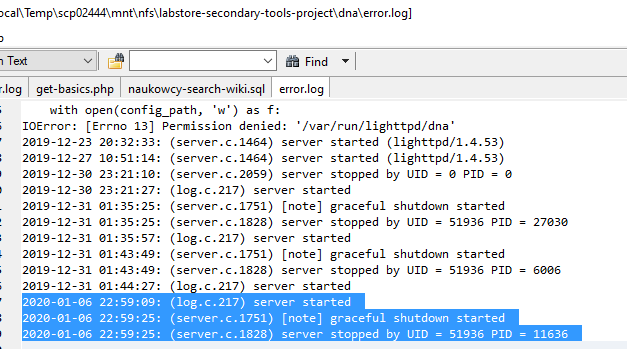
This is error.log for my tool:
The problem is I didn't shut it down. So what did?
Is this is a bug or someone hacking around or something.
I did notice some problems last year. After 2019-12-12. I assumed that was a direct consequence of maintenance that happened on that day.
But just to be sure this my log from 2019-12-12: 2019-12-12 11:47:22: (log.c.217) server started 2019-12-12 11:48:38: (log.c.217) server started Traceback (most recent call last): File "/usr/bin/webservice-runner", line 30, in <module> webservice.run(port) File "/usr/lib/python2.7/dist-packages/toollabs/webservice/services/lighttpdwebservice.py", line 656, in run with open(config_path, 'w') as f: IOError: [Errno 13] Permission denied: '/var/run/lighttpd/dna' 2019-12-12 11:52:26: (server.c.1751) [note] graceful shutdown started 2019-12-12 11:52:26: (server.c.1828) server stopped by UID = 51936 PID = 16488 2019-12-12 11:52:28: (server.c.1751) [note] graceful shutdown started 2019-12-12 11:52:28: (server.c.1828) server stopped by UID = 51936 PID = 29249 2019-12-12 12:39:37: (log.c.217) server started Traceback (most recent call last): File "/usr/bin/webservice-runner", line 30, in <module> webservice.run(port) File "/usr/lib/python2.7/dist-packages/toollabs/webservice/services/lighttpdwebservice.py", line 656, in run with open(config_path, 'w') as f: IOError: [Errno 13] Permission denied: '/var/run/lighttpd/dna' 2019-12-23 20:32:33: (server.c.1464) server started (lighttpd/1.4.53) 2019-12-27 10:51:14: (server.c.1464) server started (lighttpd/1.4.53) 2019-12-30 23:21:10: (server.c.2059) server stopped by UID = 0 PID = 0 2019-12-30 23:21:27: (log.c.217) server started
That on 2019-12-23 was not me either, but that was on request via IRC.
Cheers, Nux.
On Tue, Jan 7, 2020 at 4:26 PM Maciej Jaros egil@wp.pl wrote:
The problem is I didn't shut it down. So what did?
Routine maintenance on the grid engine nodes. The shutdown timestamps line up with this SAL entry [0]: "22:58 <bd808> Depooling tools-sgewebgrid-lighttpd-090[2-9]".
The depooling process is intended to restart running webservice workloads on new nodes in the cluster, but apparently in this case it did not. Sadly this is not horribly surprising. Grid engine is not very good at tracking system state compared to the Kubernetes cluster in Toolforge.
If your tool is capable of running on our Kubernetes system (uses one language runtime and does not rely on special software installed globally) then migrating from Grid Engine to Kubernetes will almost certainly leave you with a more stable webservice. See the Wikitech page on the last Grid Engine migration [1] for some hints on how to migrate.
[0]: https://tools.wmflabs.org/sal/log/AW99FPYQfYQT6VcDfz3h [1]: https://wikitech.wikimedia.org/wiki/News/Toolforge_Trusty_deprecation#Move_a...
Bryan
{kind=link}
{kind=link}