The number of Apache busy workers on the image scalers spiked between 2:55 and 3:15 UTC, peaking at about 3:12 and overwhelming rendering.svc.eqiad.wmnet for about a minute.
The outage correlates fairly well with a spike of fatals in TimedMediaHandler, consisting almost entirely of requests to this URL: < http://commons.wikimedia.org/w/thumb_handler.php/2/2c/Closed_Friedmann_unive...
.
The full stack trace is included in < https://bugzilla.wikimedia.org/show_bug.cgi?id=64152%3E, filed by Reedy yesterday. It appears File::getMimeType is returning 'unknown/unknown' and that File::getHandler is consequently not able to find a handler.
On Mon, Apr 21, 2014 at 8:04 AM, Ori Livneh ori@wikimedia.org wrote:
The number of Apache busy workers on the image scalers spiked between 2:55 and 3:15 UTC, peaking at about 3:12 and overwhelming rendering.svc.eqiad.wmnet for about a minute.
The outage correlates fairly well with a spike of fatals in TimedMediaHandler, consisting almost entirely of requests to this URL: < http://commons.wikimedia.org/w/thumb_handler.php/2/2c/Closed_Friedmann_unive...
.
The full stack trace is included in < https://bugzilla.wikimedia.org/show_bug.cgi?id=64152%3E, filed by Reedy yesterday. It appears File::getMimeType is returning 'unknown/unknown' and that File::getHandler is consequently not able to find a handler.
The problem has happened again this morning between 8:25 and 8:35 UTC. This time the load was so high that ganglia stopped graphing data. From an analysis of the logs, while it is true we have a lot of fatals for that url above, it is also true that the number of requests for that url is quite low and does not present a spike in that interval. So the problem is genuine load and that is probably caused by some large processing.
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Giuseppe
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump: https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Aaron/Multimedia team, what do you think?
Regards, Faidon
Thanks for the detailed report, Faidon.
Can you clarify something: for a given set of heavyweight thumbnails that need to be rendered, assuming the the uploads have ceased, would multiple visits of Special:NewFiles in a short timeframe multiply the saturation by the amount of HTTP requests to the same thumbnail URLs? I.e. if you request the URL of a thumbnail which is currently being generated because someone else requested it, does it make the issue worse?
Second question is, how come piling on jobs doesn't just make the jobs that came last complete much later? The same kind of DoS situation could happen with someone bombarding us with HEAD requests on previously unrequested thumbnail sizes for small images, so I think that the issue isn't specific to large jobs. It's more a matter of properly queueing things up so that the imagescalers don't overload, regardless of the mix of job weight.
On Mon, Apr 21, 2014 at 12:05 PM, Faidon Liambotis faidon@wikimedia.orgwrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes,
so
I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump:
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Aaron/Multimedia team, what do you think?
Regards, Faidon
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
On Mon, Apr 21, 2014 at 12:22:36PM +0200, Gilles Dubuc wrote:
Can you clarify something: for a given set of heavyweight thumbnails that need to be rendered, assuming the the uploads have ceased, would multiple visits of Special:NewFiles in a short timeframe multiply the saturation by the amount of HTTP requests to the same thumbnail URLs? I.e. if you request the URL of a thumbnail which is currently being generated because someone else requested it, does it make the issue worse?
Varnish should do some coalescing of requests with the exact same URL and Aaron worked on wrapping thumb calls in PoolCounter on the MediaWiki side lately as well. So, in theory, no, this shouldn't happen.
Note that Special:NewFiles will show thumbnails from multiple files, though, so your browser would request multiple *different* thumbnails (different URLs) in parallel.
Second question is, how come piling on jobs doesn't just make the jobs that came last complete much later? The same kind of DoS situation could happen with someone bombarding us with HEAD requests on previously unrequested thumbnail sizes for small images, so I think that the issue isn't specific to large jobs. It's more a matter of properly queueing things up so that the imagescalers don't overload, regardless of the mix of job weight.
Yes, there are multiple vectors here that can DoS us, including the one you mention :) Note that these aren't "jobs" in the jobqueue sense; thumb generation happens in realtime, for every request that comes for a size that isn't already stored (cached) in Swift.
Faidon
Well the Varnish request coalescing can't work for requests with login Cookie headers. I've seen code in our VCLs to disable it in those cases since the origin response cannot be reused for authenticated requests typically.
On Tue, Apr 22, 2014 at 3:47 AM, Faidon Liambotis faidon@wikimedia.orgwrote:
On Mon, Apr 21, 2014 at 12:22:36PM +0200, Gilles Dubuc wrote:
Can you clarify something: for a given set of heavyweight thumbnails that need to be rendered, assuming the the uploads have ceased, would multiple visits of Special:NewFiles in a short timeframe multiply the saturation
by
the amount of HTTP requests to the same thumbnail URLs? I.e. if you
request
the URL of a thumbnail which is currently being generated because someone else requested it, does it make the issue worse?
Varnish should do some coalescing of requests with the exact same URL and Aaron worked on wrapping thumb calls in PoolCounter on the MediaWiki side lately as well. So, in theory, no, this shouldn't happen.
Note that Special:NewFiles will show thumbnails from multiple files, though, so your browser would request multiple *different* thumbnails (different URLs) in parallel.
Second question is, how come piling on jobs doesn't just make the jobs
that
came last complete much later? The same kind of DoS situation could
happen
with someone bombarding us with HEAD requests on previously unrequested thumbnail sizes for small images, so I think that the issue isn't
specific
to large jobs. It's more a matter of properly queueing things up so that the imagescalers don't overload, regardless of the mix of job weight.
Yes, there are multiple vectors here that can DoS us, including the one you mention :) Note that these aren't "jobs" in the jobqueue sense; thumb generation happens in realtime, for every request that comes for a size that isn't already stored (cached) in Swift.
Faidon
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump: https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded collection of historical plans of the Zurich main station: https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us. ===========
Dear Faidon, Emmanuel and Guiseppe,
Thanks so much for investigating this issue so quickly and sharing the likely cause of the problem with us.
This quarter, our team’s top priority is to address serious issues related to Upload Wizard — and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which is likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling tickets about this issue, so we can hit the ground running in early may.
Thanks again for your fine work, as well as for your patience and understanding.
Fabrice
On Apr 21, 2014, at 3:53 AM, Emmanuel Engelhart emmanuel.engelhart@wikimedia.ch wrote:
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump: https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded collection of historical plans of the Zurich main station: https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us.
-- Volunteer Technology, GLAM, Trainings Zurich +41 797 670 398
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
_______________________________
Fabrice Florin Product Manager Wikimedia Foundation
Hi Fabrice
On 21.04.2014 17:57, Fabrice Florin wrote:
This quarter, our team’s top priority is to address serious issues related to Upload Wizard — and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which is likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling tickets about this issue, so we can hit the ground running in early may.
That's a great news. Thank you.
Emmanuel
Fabrice,
I don't see how a feature release can be of a higher priority than troubleshooting an outage but regardless:
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps (see the large red banner with the stop sign at the bottom)
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
Sadly, I don't have much to offer them, as I previously explained. I certainly wouldn't commit to anything considering your response on the matter.
Could you communicate your team's priorities to Fæ and the rest of the Commons/GLAM community directly?
Thanks, Faidon
On Mon, Apr 21, 2014 at 08:57:39AM -0700, Fabrice Florin wrote:
Dear Faidon, Emmanuel and Guiseppe,
Thanks so much for investigating this issue so quickly and sharing the likely cause of the problem with us.
This quarter, our team’s top priority is to address serious issues related to Upload Wizard — and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which is likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling tickets about this issue, so we can hit the ground running in early may.
Thanks again for your fine work, as well as for your patience and understanding.
Fabrice
On Apr 21, 2014, at 3:53 AM, Emmanuel Engelhart emmanuel.engelhart@wikimedia.ch wrote:
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump: https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded collection of historical plans of the Zurich main station: https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us.
-- Volunteer Technology, GLAM, Trainings Zurich +41 797 670 398
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
Fabrice Florin Product Manager Wikimedia Foundation
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
Dear Faidon,
Your point is well taken that a major outage should trump a feature release.
We will discuss this issue with the multimedia team in tomorrow’s sprint planning meeting and see if we can take it on right away. If we do, this could push back our release of Media Viewer in coming weeks.
For now, I have filed this high-priority ’spike' ticket for evaluation by our team. We will respond here and onwiki, once our team has had a chance to investigate possible solutions.
https://wikimedia.mingle.thoughtworks.com/projects/multimedia/cards/482
Thanks again to everyone on your team for taking on this issue!
Regards as ever,
Fabrice
______________________________________
#482 Investigate solution for image scalers outage
Narrative As a power user, I can upload large TIFF image files using GWToolset, so that others can view them without crashing the system.
Investigate possible solutions for the image scalers outage that took place over Easter weekend.
User:Fæ uploaded hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them, as reported by Faidon.
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
It appears this project is establishing the limits of what Commons can currently handle, and we invite ideas on how the strain on the servers for the large images involved can be reduced.
According to Emmanuel, it seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
https://wikimedia.mingle.thoughtworks.com/projects/multimedia/cards/482
On Apr 22, 2014, at 4:31 AM, Faidon Liambotis faidon@wikimedia.org wrote:
Fabrice,
I don't see how a feature release can be of a higher priority than troubleshooting an outage but regardless:
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps (see the large red banner with the stop sign at the bottom)
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
Sadly, I don't have much to offer them, as I previously explained. I certainly wouldn't commit to anything considering your response on the matter.
Could you communicate your team's priorities to Fæ and the rest of the Commons/GLAM community directly?
Thanks, Faidon
On Mon, Apr 21, 2014 at 08:57:39AM -0700, Fabrice Florin wrote:
Dear Faidon, Emmanuel and Guiseppe,
Thanks so much for investigating this issue so quickly and sharing the likely cause of the problem with us.
This quarter, our team’s top priority is to address serious issues related to Upload Wizard — and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which is likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling tickets about this issue, so we can hit the ground running in early may.
Thanks again for your fine work, as well as for your patience and understanding.
Fabrice
On Apr 21, 2014, at 3:53 AM, Emmanuel Engelhart emmanuel.engelhart@wikimedia.ch wrote:
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump: https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded collection of historical plans of the Zurich main station: https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us.
-- Volunteer Technology, GLAM, Trainings Zurich +41 797 670 398
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
Fabrice Florin Product Manager Wikimedia Foundation
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
_______________________________
Fabrice Florin Product Manager Wikimedia Foundation
I dont think vips would help this situation very much. (Also the vips patch is only half done. Its waiting on someone to do the other half. It is not waiting for review)
At first glance (by which I mean what is said in this thread without doing any other investigation), it appears that the upload rate of files from gwtoolset is higher than the rate at which we can generate thumbnails that are "instantly" demanded. Obvious solution would be to slow down gwtoolset. Afaik there are currently multiple job runner processes that process gwtoolset jobs (--maxthreads). Lets reduce that to 1. If thats still too speedy, we could add a sleep() call to the job code. After that we could restart fae's batch upload, but with just the next 50 files. Watch ganglia stats like a hawk, if nothing bad happens, do the next 100, then 200, etc until we are reasonably sure that the gwtoolset upload rate is sustainable. Once we are sure, tell the users they can go wild again.
--bawolff
On Apr 22, 2014 2:27 PM, "Fabrice Florin" fflorin@wikimedia.org wrote:
Dear Faidon,
Your point is well taken that a major outage should trump a feature
release.
We will discuss this issue with the multimedia team in tomorrow’s sprint
planning meeting and see if we can take it on right away. If we do, this could push back our release of Media Viewer in coming weeks.
For now, I have filed this high-priority ’spike' ticket for evaluation by
our team. We will respond here and onwiki, once our team has had a chance to investigate possible solutions.
https://wikimedia.mingle.thoughtworks.com/projects/multimedia/cards/482
Thanks again to everyone on your team for taking on this issue!
Regards as ever,
Fabrice
#482 Investigate solution for image scalers outage
Narrative As a power user, I can upload large TIFF image files using GWToolset, so
that others can view them without crashing the system.
Investigate possible solutions for the image scalers outage that took
place over Easter weekend.
User:Fæ uploaded hundreds of 100-200MB multipage TIFFs via GWToolset over
the course of 4-5 hours (multiple files per minute), and then
random users/bots viewing Special:NewFiles, which attempts to display
a thumbnail for all of those new files in parallel in realtime, and thus
saturating imagescalers' MaxClients setting and basically
inadvertently DoSing them, as reported by Faidon.
The outage's symptoms seem to have been alleviated since, but
the Commons/GLAM communities are waiting for a response from us to resume
their work. They've responded to our "pause" request and in
turn requested our feedback at:
https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
It appears this project is establishing the limits of what Commons can
currently handle, and we invite ideas on how the strain on the servers for the large images involved can be reduced.
According to Emmanuel, it seems that this problem might be fixed by using
the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months:
https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
https://wikimedia.mingle.thoughtworks.com/projects/multimedia/cards/482
On Apr 22, 2014, at 4:31 AM, Faidon Liambotis faidon@wikimedia.org
wrote:
Fabrice,
I don't see how a feature release can be of a higher priority than troubleshooting an outage but regardless:
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps (see the large red banner with the stop sign at the bottom)
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
Sadly, I don't have much to offer them, as I previously explained. I certainly wouldn't commit to anything considering your response on the matter.
Could you communicate your team's priorities to Fæ and the rest of the Commons/GLAM community directly?
Thanks, Faidon
On Mon, Apr 21, 2014 at 08:57:39AM -0700, Fabrice Florin wrote:
Dear Faidon, Emmanuel and Guiseppe,
Thanks so much for investigating this issue so quickly and sharing the
likely cause of the problem with us.
This quarter, our team’s top priority is to address serious issues
related to Upload Wizard — and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which
is likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling
tickets about this issue, so we can hit the ground running in early may.
Thanks again for your fine work, as well as for your patience and
understanding.
Fabrice
On Apr 21, 2014, at 3:53 AM, Emmanuel Engelhart <
emmanuel.engelhart@wikimedia.ch> wrote:
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache
processes, so
I don't have more details - Faidon was investigating as well and may
have
more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display
a
thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically
inadvertently
DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the
user
kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and
then
for as long as the upload activity continued.
I left a comment over at
https://commons.wikimedia.org/wiki/User_talk:F%C3%A6
and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in
the
short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump:
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can
do
about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't
completely
saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a
serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make
it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage
institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded
collection of historical plans of the Zurich main station:
https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for
TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months:
https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the
priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us.
-- Volunteer Technology, GLAM, Trainings Zurich +41 797 670 398
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
Fabrice Florin Product Manager Wikimedia Foundation
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
Fabrice Florin Product Manager Wikimedia Foundation
http://en.wikipedia.org/wiki/User:Fabrice_Florin_(WMF)
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
Hi folks,
I’m happy to let you know that in today’s sprint planning meeting, the multimedia team agreed to take on this issue as our top priority this week.
Gilles will be leading this investigation and report back to us, as we identify practical solutions to this complex problem.
We pushed back some feature development on Media Viewer to make this happen, but are still working on the same release schedule for now.
Many thanks to everyone who helped address this emergency over the weekend — and for all your good advice on how to solve this issue!
Fabrice
On Apr 22, 2014, at 10:26 AM, Fabrice Florin fflorin@wikimedia.org wrote:
Dear Faidon,
Your point is well taken that a major outage should trump a feature release.
We will discuss this issue with the multimedia team in tomorrow’s sprint planning meeting and see if we can take it on right away. If we do, this could push back our release of Media Viewer in coming weeks.
For now, I have filed this high-priority ’spike' ticket for evaluation by our team. We will respond here and onwiki, once our team has had a chance to investigate possible solutions.
https://wikimedia.mingle.thoughtworks.com/projects/multimedia/cards/482
Thanks again to everyone on your team for taking on this issue!
Regards as ever,
Fabrice
#482 Investigate solution for image scalers outage
Narrative As a power user, I can upload large TIFF image files using GWToolset, so that others can view them without crashing the system.
Investigate possible solutions for the image scalers outage that took place over Easter weekend.
User:Fæ uploaded hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them, as reported by Faidon.
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
It appears this project is establishing the limits of what Commons can currently handle, and we invite ideas on how the strain on the servers for the large images involved can be reduced.
According to Emmanuel, it seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
https://wikimedia.mingle.thoughtworks.com/projects/multimedia/cards/482
On Apr 22, 2014, at 4:31 AM, Faidon Liambotis faidon@wikimedia.org wrote:
Fabrice,
I don't see how a feature release can be of a higher priority than troubleshooting an outage but regardless:
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps (see the large red banner with the stop sign at the bottom)
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
Sadly, I don't have much to offer them, as I previously explained. I certainly wouldn't commit to anything considering your response on the matter.
Could you communicate your team's priorities to Fæ and the rest of the Commons/GLAM community directly?
Thanks, Faidon
On Mon, Apr 21, 2014 at 08:57:39AM -0700, Fabrice Florin wrote:
Dear Faidon, Emmanuel and Guiseppe,
Thanks so much for investigating this issue so quickly and sharing the likely cause of the problem with us.
This quarter, our team’s top priority is to address serious issues related to Upload Wizard — and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which is likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling tickets about this issue, so we can hit the ground running in early may.
Thanks again for your fine work, as well as for your patience and understanding.
Fabrice
On Apr 21, 2014, at 3:53 AM, Emmanuel Engelhart emmanuel.engelhart@wikimedia.ch wrote:
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes, so I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump: https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded collection of historical plans of the Zurich main station: https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months: https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us.
-- Volunteer Technology, GLAM, Trainings Zurich +41 797 670 398
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
Fabrice Florin Product Manager Wikimedia Foundation
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
Fabrice Florin Product Manager Wikimedia Foundation
_______________________________
Fabrice Florin Product Manager Wikimedia Foundation
Thanks for the hotfix, Aaron, and the reply to my questions, Faidon. The multimedia team has allocated time this sprint to find a short-term and long-term plan for the general Image Scaler situation, and each subsequent sprint we'll have time allocated as well to act on that plan and implement it.
I'd like to have an engineering meeting with both of you and our team (invite sent), to help us fully understand the various parts involved. At the moment I think we all (multimedia folks) have a lot of catching up to do in terms of knowledge of that code, I don't think any of us would have been capable of writing the hotfix Aaron did. Our team needs to acquire that knowledge ASAP.
Now, let's not wait for the meeting to start discussing the issue and proposed solutions. As I've stated earlier in this thread, I would like to revisit the fact that the thumbnails are being generated in real time, because it's the bigger problem and Image Scalers will still be subject to going down if we don't fix that. I suspect that a solution to that broader problem would solve the GWToolset issue as well.
Aaron worked on wrapping thumb calls in PoolCounter on the MediaWiki side
lately as well
Am I correct to assume that the PoolCounter wrapping is used to dedupe requests from different image scaler servers to generate the same thumbnail?
I've thought about the problem since the incident and I came up with the following rough idea, that I'd like everyone to criticize/validate against their knowledge of the existing setup. Note that it's based on a surface understanding of things, I still don't know the existing code very well, which is why your knowledge applied against my idea will be very useful.
Instead of each image scaler server generating a thumbnail immediately when a new size is requested, the following would happen in the script handling the thumbnail generation request: - the client's connection would be kept open, potentially for a while. All the way from the end-user to the thumb script - a data store (what kind is TBD, whatever is most appropriate, redis might be a good candidate) would be connected to and a virtual resource request would be added to a queue. Basically the script would be queueing an "I need one unit of thumbnail generation" request object - in a loop, the same data store would be read every X milliseconds to check the request object's position in the queue - if the request object's position is below a certain configurable limit, the actual job starts, scaling the image and storing the thumb - when the script is done generating the thumbnail, it removes its request object from the queue, essentially liberating a virtual unit of thumbnail generation ork for another thumb request to use. And of course it returns the generated thumb as it currently does. - if the script dies for whatever reason, an expiry setting on the queued request object would kick in at the data store level, liberating the virtual unit automatically - if the client requesting the thumb gives up and closes the connection because there's a high load and they don't see the thumb appear fast enough to their taste, the script would keep running, wait for its turn in the queue and ultimately render the thumb anyway. This is crucial, because at times of high load when things start taking time, we definitely don't want users refreshing the page to result in aborting and restarting the exact same thumb generation work. Every thumb generation request should complete, even if much later and with no end-user with an open connection to see the result anymore.
Pros: - The limit on virtual units of work means that the image scaler server load should never go over a certain point. No more going down depending on the mix or quantity of thumb requests coming in. The servers would just be handling as much work as they actually can and no more. - This would be agnostic of how long a given thumbnail generation takes. Which means that someone uploading lots of large files that are very time-consuming to generate thumbs for, such as last weekend's incident, wouldn't take down image scalers. They'd just slow down thumb generation across the board. - The queue size could be configurable. The best strategy is to start low (eg. as many units as there are servers) - The queue could be smarter than a plain queue and have weight and client-based priority strategies. For example we could make it so that people uploading a lot of large images don't hog the queue to themselves. I don't see that as a requirement to solve the reliability issues, but it would be nice to have, and such a prioritization would be very relevant to the GWToolset user behavior. It would basically that someone uploading a lot of large images would only have their thumbs take longer to generate than usual, not everyone else's as well. - We could write "attack bots" that would attempt DoSing the image scalers in various ways and let us verify that this new system behaves well under heavy load. We know the weaknesses, we should be testing them and making sure that they're solved, instead of waiting for someone with bad intentions or some accident coming from unusual usage pattern to do that for us.
Cons: - Under high load, HTTP connections could potentially be held for a while. Maybe that's not such a big deal, I guess Ops has the answer. I think it's fair to set a time limit on that too, and still have the thumbnail generation happen even if we closed the connection to the client. From the end-user's perspective, the experience would be that they wait a while for a thumb to appear, the connection dies, but chances are that if they refresh the page a few seconds or minutes later, the thumb will be there. - During high load/DoS attack/whatever people viewing thumbs at new sizes will experience long image load times. Considering that most of the time, the thumb will end up appearing before a timeout occurs, I think that's preferable to the status quo, which is that image scalers would go down entirely in those situations.
On Tue, Apr 22, 2014 at 1:31 PM, Faidon Liambotis faidon@wikimedia.orgwrote:
Fabrice,
I don't see how a feature release can be of a higher priority than troubleshooting an outage but regardless:
The outage's symptoms seem to have been alleviated since, but the Commons/GLAM communities are waiting for a response from us to resume their work. They've responded to our "pause" request and in turn requested our feedback at: https://commons.wikimedia.org/wiki/Commons:Batch_uploading/NYPL_Maps (see the large red banner with the stop sign at the bottom)
...which is also linked from: https://commons.wikimedia.org/wiki/User_talk:F%C3%A6#Large_file_uploads
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
Sadly, I don't have much to offer them, as I previously explained. I certainly wouldn't commit to anything considering your response on the matter.
Could you communicate your team's priorities to Fæ and the rest of the Commons/GLAM community directly?
Thanks, Faidon
On Mon, Apr 21, 2014 at 08:57:39AM -0700, Fabrice Florin wrote:
Dear Faidon, Emmanuel and Guiseppe,
Thanks so much for investigating this issue so quickly and sharing the
likely cause of the problem with us.
This quarter, our team's top priority is to address serious issues
related to Upload Wizard -- and this seems like a good one for us to take on.
However, we are still in the process of releasing Media Viewer, which is
likely to take most of our attention for the next few weeks.
So we may not be able to troubleshoot it right away. But we are filling
tickets about this issue, so we can hit the ground running in early may.
Thanks again for your fine work, as well as for your patience and
understanding.
Fabrice
On Apr 21, 2014, at 3:53 AM, Emmanuel Engelhart <
emmanuel.engelhart@wikimedia.ch> wrote:
On 21.04.2014 12:05, Faidon Liambotis wrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache
processes, so
I don't have more details - Faidon was investigating as well and may
have
more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display
a
thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically
inadvertently
DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the
user
kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and
then
for as long as the upload activity continued.
I left a comment over at
https://commons.wikimedia.org/wiki/User_talk:F%C3%A6
and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in
the
short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump:
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can
do
about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't
completely
saturate and DoS the cluster.
Commons has big difficulties to deal with big TIFF files and this is a
serious issue, in particular for Wikipedians in Residence. To me it looks like that using the Vipsscaler would help to fix the worse ones.
Here is an email I have sent to Andre and Greg a few days ago. I make
it public with the hope it might help.
=========== As a GLAM volunteer and WIR at the Swiss National Library, I encourage
institutions to upload high quality pictures to increase digital sustainability. But, in the worse case (big TIFF files), Commons is not able to deal with them and fails to compute the thumbnails.
You have a perfect example of the problem with this recently uploaded
collection of historical plans of the Zurich main station:
https://commons.wikimedia.org/wiki/Category:Historical_plans_of_Zurich_Main_...
It seems that this problem might be fixed by using the VipsScaler for
TIFF pictures and Greg has already worked on this and proposed a patch. But this patch has been waiting a review since 7 months:
https://bugzilla.wikimedia.org/show_bug.cgi?id=52045
IMO it would be great if you could do something to increase the
priority and the urgency of this ticket. The movement invests pretty much resources to build successful collaboration with GLAMs and many of them get braked by this "silly" bug.
Hope you can help us.
-- Volunteer Technology, GLAM, Trainings Zurich +41 797 670 398
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
Fabrice Florin Product Manager Wikimedia Foundation
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
Multimedia mailing list Multimedia@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/multimedia
On 04/24/2014 06:00 AM, Gilles Dubuc wrote:
Instead of each image scaler server generating a thumbnail immediately when a new size is requested, the following would happen in the script handling the thumbnail generation request:
It might be helpful to consider this as a fairly generic request limiting / load shedding problem. There are likely simpler and more robust solutions to this using plain Varnish or Nginx, where you basically limit the number of backend connections, and let other requests wait.
Rate limiting without client keys is very limited though. It really only works around the root cause of us allowing clients to start very expensive operations in real time.
A possible way to address the root cause might be to generate screen-sized thumbnails in a standard size ('xxl') in a background process after upload, and then scale all on-demand thumbnails from those. If the base thumb is not yet generated, a placeholder can be displayed and no immediate scaling happens. With the expensive operation of extracting reasonably-sized base thumbs from large originals now happening in a background job, rate limiting becomes easier and won't directly affect the generation of thumbnails of existing images. Creating small thumbs from the smaller base thumb will also be faster than starting from a larger original, and should still yield good quality for typical thumb sizes if the 'xxl' thumb size is large enough.
The disadvantage for multi-page documents would be that we'd create a lot of screen-sized thumbs, some of which might not actually be used. Storage space is relatively cheap though, at least cheaper than service downtime or degraded user experience from normal thumb scale requests being slow.
Gabriel
This is similar to what I proposed to Ori. For multi-page file (pdf,djvu,tiff) we'd prerender base thumbnails and use them for downscaling in thumb.php on demand. The base thumbnails would only be so large (e.g. not 10000px width) since there isn't much use case for massive thumbnails vs just viewing the original. This would also apply to single page TIFFs, where one reference thumbnail of reasonable size would be used for downscaling on demand. The reference files could be created on upload before the file could even appear at places like Special:NewImages. Resizing the reference files would actually be reasonable to do in thumb.php. File purges could exempt the reference thumbnails themselves (or if it didn't then their generation would be pool countered like TMH does at least). The reference thumbnails should also be in Swift even if we move to CDN "only" thumbnail storage. Disk space is cheap enough for this.
On Thu, Apr 24, 2014 at 8:57 AM, Gabriel Wicke gwicke@wikimedia.org wrote:
On 04/24/2014 06:00 AM, Gilles Dubuc wrote:
Instead of each image scaler server generating a thumbnail immediately
when
a new size is requested, the following would happen in the script
handling
the thumbnail generation request:
It might be helpful to consider this as a fairly generic request limiting / load shedding problem. There are likely simpler and more robust solutions to this using plain Varnish or Nginx, where you basically limit the number of backend connections, and let other requests wait.
Rate limiting without client keys is very limited though. It really only works around the root cause of us allowing clients to start very expensive operations in real time.
A possible way to address the root cause might be to generate screen-sized thumbnails in a standard size ('xxl') in a background process after upload, and then scale all on-demand thumbnails from those. If the base thumb is not yet generated, a placeholder can be displayed and no immediate scaling happens. With the expensive operation of extracting reasonably-sized base thumbs from large originals now happening in a background job, rate limiting becomes easier and won't directly affect the generation of thumbnails of existing images. Creating small thumbs from the smaller base thumb will also be faster than starting from a larger original, and should still yield good quality for typical thumb sizes if the 'xxl' thumb size is large enough.
The disadvantage for multi-page documents would be that we'd create a lot of screen-sized thumbs, some of which might not actually be used. Storage space is relatively cheap though, at least cheaper than service downtime or degraded user experience from normal thumb scale requests being slow.
Gabriel
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
On 04/24/2014 12:29 PM, Aaron Schulz wrote:
This is similar to what I proposed to Ori. For multi-page file (pdf,djvu,tiff) we'd prerender base thumbnails and use them for downscaling in thumb.php on demand. The base thumbnails would only be so large (e.g. not 10000px width) since there isn't much use case for massive thumbnails vs just viewing the original. This would also apply to single page TIFFs, where one reference thumbnail of reasonable size would be used for downscaling on demand.
It might even improve performance to do this for all (or at least overly large) images after looking a bit more into the distribution of typical thumb sizes and their quality when scaled from a reasonably-sized base thumb. With higher camera resolutions even JPG originals can be fairly large. 2560×1600 for example should cover the vast majority of current screens well, and could be referenced by the MultimediaViewer on high-res screens where it currently falls back to the (potentially huge) original.
Gabriel
I changed the failure limiting to detecting fatals in https://gerrit.wikimedia.org/r/#/c/127642/ and also tweaked the "large source file download" pool counter config timeouts in https://gerrit.wikimedia.org/r/#/c/127654/. Hopefully that should help for now.
On Mon, Apr 21, 2014 at 3:05 AM, Faidon Liambotis faidon@wikimedia.orgwrote:
On Mon, Apr 21, 2014 at 10:56:40AM +0200, Giuseppe Lavagetto wrote:
The problem resolved before I could get to strace the apache processes,
so
I don't have more details - Faidon was investigating as well and may have more info.
Indeed, I do: this had nothing to do with TMH. The trigger was Commons User:Fæ uploading hundreds of 100-200MB multipage TIFFs via GWToolset over the course of 4-5 hours (multiple files per minute), and then random users/bots viewing Special:NewFiles, which attempts to display a thumbnail for all of those new files in parallel in realtime, and thus saturating imagescalers' MaxClients setting and basically inadvertently DoSing them.
The issue was temporary because of https://bugzilla.wikimedia.org/show_bug.cgi?id=49118 but since the user kept uploading new files, it was recurrent, with different files every time. Essentially, we would keep having short outages every now and then for as long as the upload activity continued.
I left a comment over at https://commons.wikimedia.org/wiki/User_talk:F%C3%A6 and contacted Commons admins over at #wikimedia-commons, as a courtesy to both before I used my root to elevate my privileges and ban a long-time prominent Wikimedia user as an emergency countermeasure :)
It was effective, as Fæ immediately responded and ceased the activity until further discussion; the Commons community was also helpful in the short discussion that followed.
Andre also pointed out that Fæ had previously began the "Images so big they break Commons" thread at the Commons Village Pump:
https://commons.wikimedia.org/wiki/Commons:Village_pump#Images_so_big_they_b...
As for the more permanent solution: there's not much we, as ops, can do about this but say "no, don't upload all these files", which is obviously not a great solution :) The root cause is an architecture issue with how imagescalers behave with regards to resource-intensive jobs coming in a short period of time. Perhaps a combination of poolcounter per file and more capacity (servers) would alleviate the effect, but ideally we should be able to have some grouping & prioritization of imagescaling jobs so that large jobs can't completely saturate and DoS the cluster.
Aaron/Multimedia team, what do you think?
Regards, Faidon
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
The discussion between WMF multimedia team<->Commons/GLAM communities has happened in a few places (various project/user talkpages, glamtools@, personal emails) and to be honest I've lost track of it, so I'm not sure what the outcome was.
Uploads seem to have been restarted per https://commons.wikimedia.org/w/index.php?title=Commons:Batch_uploading/NYPL...
We just had a brief imagescaler outage today at approx. 11:20 UTC that was investigated and NYPL maps were found to be the cause of the outage. Besides the complete outage of imagescaling, Swift's (4Gbps) bandwidth was saturated again, which would cause slowdowns and timeouts in file serving as well.
I found 7396 NYPL Maps in GWToolset's queue under Fæ's account and subsequently removed them as of approx. 11:51 UTC to restore site stability.
I've notified the NYPL Maps project of a requested pause with: https://commons.wikimedia.org/w/index.php?title=Commons:Batch_uploading/NYPL...
Regards, Faidon
On Sun, May 11, 2014 at 5:04 AM, Faidon Liambotis faidon@wikimedia.orgwrote:
The discussion between WMF multimedia team<->Commons/GLAM communities has happened in a few places (various project/user talkpages, glamtools@, personal emails) and to be honest I've lost track of it, so I'm not sure what the outcome was.
I think the short-term outcome was to throttle GWToolset until there is a better fix. There is a patch pending to do that: https://gerrit.wikimedia.org/r/#/c/132111/ https://gerrit.wikimedia.org/r/#/c/132112/
I described the thinking behind the limits in this mail and the followups: http://thread.gmane.org/gmane.org.wikimedia.glamtools/24/focus=104 tl;dr it tries to limit the GWToolset-uploaded thumbnails appearing in Special:* at one time to 10% (5 with default settings), based on the total upload rate in the slowest hour of an average day. That's about one image per two minutes.
This is not live yet; Fae has apparently been running the upload with three threads (as a side note, GWToolset should probably log this), which means about one image per 20 sec (more precisely, three upload jobs are generated per minute; how the job queue picks them is not controlled).
(I haven't been paying the issue much attention because I assumed that GWToolset is inoperational anyway until the next deploy due to bug 64931. Apparently I misunderstood how the job queue handles jobs that throw exceptions.)
On Sun, May 11, 2014 at 11:33 AM, Gergo Tisza gtisza@wikimedia.org wrote:
I think the short-term outcome was to throttle GWToolset until there is a better fix. There is a patch pending to do that: https://gerrit.wikimedia.org/r/#/c/132111/ https://gerrit.wikimedia.org/r/#/c/132112/
I described the thinking behind the limits in this mail and the followups: http://thread.gmane.org/gmane.org.wikimedia.glamtools/24/focus=104 tl;dr it tries to limit the GWToolset-uploaded thumbnails appearing in Special:* at one time to 10% (5 with default settings), based on the total upload rate in the slowest hour of an average day. That's about one image per two minutes.
The core patch is merged now so we could backport and merge the config patch, and restart GWToolset uploads, in a few days, if we think the throttling is enough to prevent further outages. That is a big if though - it is not clear that throttling would be a good way to avoid overloading the scalers.
My understanding is that there were three ways in which the NYPL map uploads were causing problems:
1. the scalers did not have enough processing power to handle all the thumbnail requests that were coming in simultaneously. This was presumably because Special:NewFiles and Special:ListFiles were filled with the NYPL maps, and users looking at those pages sent dozens of thumbnailing requests in parallel. 2. Swift traffic was saturated by GWToolset-uploaded files, making the serving of everything else very slow. I assume this was because of the scalers fetching the original files? Or could this be directly caused by the uploading somehow? 3. GWToolset jobs piling up in the job queue (Faidon said he cleared out 7396 jobs).
== Scaler overload ==
For the first problem, we can make an educated guess of the level of throttling required: if we want to keep the number of simultaneous GWToolset-related scaling requests below X, that means Special:NewFiles and Special:ListFiles should not have more than X/2 GWToolset files on them at any given time. Those pages show the last 50 files, so GWToolset should not upload more than X files in the time that takes normal users to upload 100 of them. I counted the number of uploads per hour on Commons on a weekday, and there were 240 uploads in the slowest hour, which is about 25 minutes for 100 files. so GWToolset should be limited to X files in 25 minutes, for some value of X that ops are happy with.
This is the best we can do with the current throttling options of the job queue, I think, but it has a lot of holes. The rate of normal uploads could drop extremely low for a short time for some reason. New file patrollers could be looking at the special pages with non-default settings (500 images instead of 50). Someone could look at the associated category (200 thumbnails at a time). This is not a problem if people are continuosly keeping watch on Special:NewFiles, because that would mean that the thumbnails get rendered soon after the uploads; but that's an untested assumption.
So I am not confident that throttling would be enough to avoid further meltdowns. I think Dan is working on a patch to make the upload jobs pre-render the thumbnails; we might have to wait for that before allowing GWToolset uploads again.
== Swift bandwidth overuse ==
This seems simple: just limit the bandwidth available for a single transfer; if the throttling+prerendering is in place, that ensures that there are no more than a set number scaling requests running in parallel. If the bandwidth use is still an issue after that, just come up with a per-transfer bandwidth limit such that even if the number of scaling requests maxes out, there is still enough bandwidth remaining to serve normal requests. (In the future, the bandwidth usage could be avoided completely by using the same server for uploading and thumbnail rendering, but that sounds like a more complex change.) Gilles already started a thread about this ("Limiting bandwidth when reading from swift").
== Job queue filling up ==
I am not sure if this is a real problem or just a symptom; does this cause any issues directly? At any rate, this seems like a bug in the code of the GWToolset jobs, which have some logic to bail out if there more than 1000 pending jobs, but apparently that does not work.
Any thoughts on this?
On Tue, May 13, 2014 at 2:45 PM, Gergo Tisza gtisza@wikimedia.org wrote:
For the first problem, we can make an educated guess of the level of throttling required: if we want to keep the number of simultaneous GWToolset-related scaling requests below X, that means Special:NewFiles and Special:ListFiles should not have more than X/2 GWToolset files on them at any given time. Those pages show the last 50 files, so GWToolset should not upload more than X files in the time that takes normal users to upload 100 of them. I counted the number of uploads per hour on Commons on a weekday, and there were 240 uploads in the slowest hour, which is about 25 minutes for 100 files. so GWToolset should be limited to X files in 25 minutes, for some value of X that ops are happy with.
This is the best we can do with the current throttling options of the job queue, I think, but it has a lot of holes. The rate of normal uploads could drop extremely low for a short time for some reason. New file patrollers could be looking at the special pages with non-default settings (500 images instead of 50). Someone could look at the associated category (200 thumbnails at a time). This is not a problem if people are continuosly keeping watch on Special:NewFiles, because that would mean that the thumbnails get rendered soon after the uploads; but that's an untested assumption.
Maybe we could create scaling priority groups? Tag GWToolset-uploaded images as belonging to the "expensive" group, then use PoolCounter to ensure that no more than X expensive thumbnails are scaled at the same time. That would throttle thumbnail rendering directly, instead of throttling the upload speed and making guesses about how that translates a throttle on rendering.
We already pool counter thumbnails on a per-file level (e.g. no more than 2 processes at a time for any thumbnails having to do with an original file at a time). Since pool counter calls cannot be nested, we can't add another layer of pool countering based on file type grouping anything of the sort.
The biggest hole right now is that either: a) A bunch of new files come in quickly, say 100. There could be 200 workers rendering those files (given pool counter). Many more, 50 * 100, could also be waiting on pool counter until they timeout, tying up thumb.php even more (though at least not using cpu or bandwith). The throttling config change could help with this if low limits are picked. b) Files come in more slowly but nobody views them until there are, say 100, and then they all get viewed at once for some reason. I'm not sure how likely this is, but it's not impossible. This would require possibly pre-rendering some thumbnails first via jobs or something in addition to the throttling config change. c) In any case, someone could still view a bunch of non-standard sizes and could tie up dozens of processes for a while before getting rate limited for a short time (and they could repeat the process). The number of threads this could tie up is lower than (b) since rate limiting would apply before the pool queue sizes would get as large. Still, it would use a lot of bandwidth and cpu. If there was throttling that was weighted (instead of using 1 for all files), then it could help.
I'm not worried about ~7000 jobs in the queue though, as it seems to just make a backlog that doesn't take up much space.
On Tue, May 13, 2014 at 2:50 PM, Gergo Tisza gtisza@wikimedia.org wrote:
On Tue, May 13, 2014 at 2:45 PM, Gergo Tisza gtisza@wikimedia.org wrote:
For the first problem, we can make an educated guess of the level of throttling required: if we want to keep the number of simultaneous GWToolset-related scaling requests below X, that means Special:NewFiles and Special:ListFiles should not have more than X/2 GWToolset files on them at any given time. Those pages show the last 50 files, so GWToolset should not upload more than X files in the time that takes normal users to upload 100 of them. I counted the number of uploads per hour on Commons on a weekday, and there were 240 uploads in the slowest hour, which is about 25 minutes for 100 files. so GWToolset should be limited to X files in 25 minutes, for some value of X that ops are happy with.
This is the best we can do with the current throttling options of the job queue, I think, but it has a lot of holes. The rate of normal uploads could drop extremely low for a short time for some reason. New file patrollers could be looking at the special pages with non-default settings (500 images instead of 50). Someone could look at the associated category (200 thumbnails at a time). This is not a problem if people are continuosly keeping watch on Special:NewFiles, because that would mean that the thumbnails get rendered soon after the uploads; but that's an untested assumption.
Maybe we could create scaling priority groups? Tag GWToolset-uploaded images as belonging to the "expensive" group, then use PoolCounter to ensure that no more than X expensive thumbnails are scaled at the same time. That would throttle thumbnail rendering directly, instead of throttling the upload speed and making guesses about how that translates a throttle on rendering.
Ops mailing list Ops@lists.wikimedia.org https://lists.wikimedia.org/mailman/listinfo/ops
On Tue, May 13, 2014 at 3:29 PM, Aaron Schulz aschulz@wikimedia.org wrote:
We already pool counter thumbnails on a per-file level (e.g. no more than 2 processes at a time for any thumbnails having to do with an original file at a time). Since pool counter calls cannot be nested, we can't add another layer of pool countering based on file type grouping anything of the sort.
For files which belong to a priority group, instead of using the file name as a key, couldn't we just hash the filename into one of the available slots for that group? That would still ensure only one process per file, but it would also limit the number of files processed from the whole group. The pool would be underused due to hash conflicts when the number of files waiting is not significantly larger than the pool itself, but that doesn't seem like a huge problem for a small pool.
Yes, if for certain files we use a different pool counter type and key (that is bucketed) that could work; as long as there is no nesting. Using a short prefix of the file name hash could work for bucketing. Membership in the "expensive" group could be determined by the media handler, since only it really knows how efficient the rendering will be (you can't just use large vs small files for example). Some config variable could decide the prefix length.
Collisions do kind of suck since they serialize operations that are known to be slow needlessly, but that's a lessor problem that what we have to deal with now.
On Tue, May 13, 2014 at 4:08 PM, Gergo Tisza gtisza@wikimedia.org wrote:
On Tue, May 13, 2014 at 3:29 PM, Aaron Schulz aschulz@wikimedia.orgwrote:
We already pool counter thumbnails on a per-file level (e.g. no more than 2 processes at a time for any thumbnails having to do with an original file at a time). Since pool counter calls cannot be nested, we can't add another layer of pool countering based on file type grouping anything of the sort.
For files which belong to a priority group, instead of using the file name as a key, couldn't we just hash the filename into one of the available slots for that group? That would still ensure only one process per file, but it would also limit the number of files processed from the whole group. The pool would be underused due to hash conflicts when the number of files waiting is not significantly larger than the pool itself, but that doesn't seem like a huge problem for a small pool.
On Tue, May 13, 2014 at 02:45:21PM -0700, Gergo Tisza wrote:
- the scalers did not have enough processing power to handle all the
thumbnail requests that were coming in simultaneously. This was presumably because Special:NewFiles and Special:ListFiles were filled with the NYPL maps, and users looking at those pages sent dozens of thumbnailing requests in parallel.
Sort of, yes. CPU was spiking but also MaxClient limits were being hit, as requests were piling up due to the large duration of those large scaling requests, both due to the time it takes to actually run it, as well as due to the time it takes to actually transfer the files.
It's unlikely we'd survive this if we increased MaxClients, though.
- Swift traffic was saturated by GWToolset-uploaded files, making the
serving of everything else very slow. I assume this was because of the scalers fetching the original files? Or could this be directly caused by the uploading somehow?
The former. The network spike graphs correlated exactly with equivalent imagescaler network spike graphs. Note that this has a secondary effect: when the network gets saturated, imagescaler original transfers become slower and hence scaling requests pile up (see above).
- GWToolset jobs piling up in the job queue (Faidon said he cleared out 7396
jobs).
Not exactly, no. I found 34 XML files in Swift under the container wikipedia-commons-gwtoolset-metadata starting with "Fæ/". A "grep -hr '<filename>' | sort -u | wc -l" showed 7396 *files* (all containing "NYPL" in the name) that would be eventually be uploaded (AIUI), not jobs in the job queue. I'm not exactly sure how GWToolset maps these into jobs in the jobqueue, but I remember reading something about a "master" job that uploads multiple files when it runs.
So I am not confident that throttling would be enough to avoid further meltdowns. I think Dan is working on a patch to make the upload jobs pre-render the thumbnails; we might have to wait for that before allowing GWToolset uploads again.
That sounds acceptable to me, preferrably in combination with the reference thumbnail idea.
Faidon
multimedia@lists.wikimedia.org
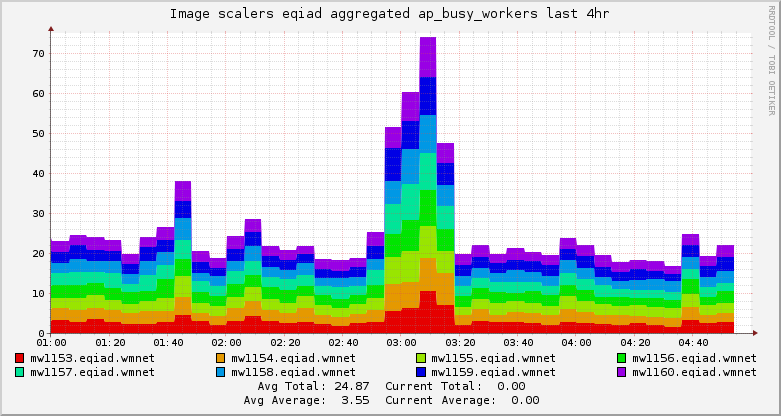{kind=link}