Fabian,
I suspect that your primary mistake is in only looking at pages with byte
length between 5800 and 6000 bytes. You've severely limited the range of
your regressor and therefor invalidated a set of assumptions for the
correlation. If you still don't think that you made a mistake, I suggest
that you try a scatter plot like the one that I have provided.
Yes, of course I got the HTML from the API in a similar way as you have.
Here's an example that gets the parsed content of the most recent revision
to Anachronism (at the time of writing this email):
Note
that I am looking up page content by revisions ID. When I generated my
page sample, I also gathered the most recent revision ID from the page
history so that when I submitted a follow-up call to get the page's
content, I would gather the parsed content at the same point in time.
As for the regression, it's more informative than a simple pearson
correlation because it separates the fitted slope (beta coef) from the
fitness of the model (R^2). Without the regression, I could not have
plotted the fitted line over the scatter plot.
I've uploaded my code to bitbucket for your reference. Specifically, see:
- Page sample
(also
strips HTML & comments based on regexs)
- R code for generating plot and
-Aaron
On Aug 6, 2013 4:17 AM, "Floeck, Fabian (AIFB)" <fabian.floeck(a)kit.edu>
wrote:
Hi,
thanks for your feedback Jonathan and Aaron.
@Jonathan: You are rightfully pointing at some things that could have been
done differently, as this was just an ad-hoc experiment. What I did was
getting the curl result of "
http://en.wikipedia.org/w/api.php?action=parse&prop=text&pageid=X&q… and
running it through BeautifulSoup [1] in Python.
Regarding references: yes, all the markup was stripped away which you
cannot see in form of readable characters as a human when you look at an
article. Take as an example [2]: in the final output (which was the base
for counting chars) what is left in characters of this reference is the
readable "[1]" and " ^ William Goldenberg at the Internet Movie
Database".
Regarding alt text: it was completely stripped out. This can arguably be
done different, if you see it as "readable main article text" as well.
You are sure right that including these would lead to a higher
correlation. Looking at samples from the output, the increase in
correlation will however not be very big, but that's a mere hunch. Anyway,
this was not what I was looking for. I wanted to compare really only the
readable text you see directly when scrolling through the article.
What is another issue is the inclusion of expandable template listings as
I mentioned in my first mail. Are the long listings of related articles
"main, readable article text"? I suppose not, but we did not filter them
out yet.
@Aaron, I'm pretty sure I didn't make a mistake, but before I can answer
your mail: What exactly does this content_length API call give you back
(I'm not aware of that). Takes the Wikisyntax and strips it of tags and
comments? Or the HTML shown in the front-end including all content
generated by templates minus all mark-up? Only in the ladder case would
this be comparable in any way to what I have done. Please clarify and send
me the concrete API call. I don't think your content_length is the length
of the readable front-end text as I used it.
(On a side note: I'm unsure why you paste the complete results of a linear
regression, as a Pearson correlation will perfectly suffice in such a
simple bivariate case. They - due to the nature of these statistical
methods - of course yield the same results in this case. Or was there any
important extra information that I missed in these regression results?).
Best,
Fabian
[1]
http://www.crummy.com/software/BeautifulSoup/bs4/doc/
[2]
http://en.wikipedia.org/wiki/William_Goldenberg#cite_note-1
On 05.08.2013, at 01:15, Aaron Halfaker <aaron.halfaker(a)gmail.com> wrote:
(note that I posted this yesterday, but the
message bounced due to the
attached scatter plot. I just uploaded the plot to
commons and re-sent)
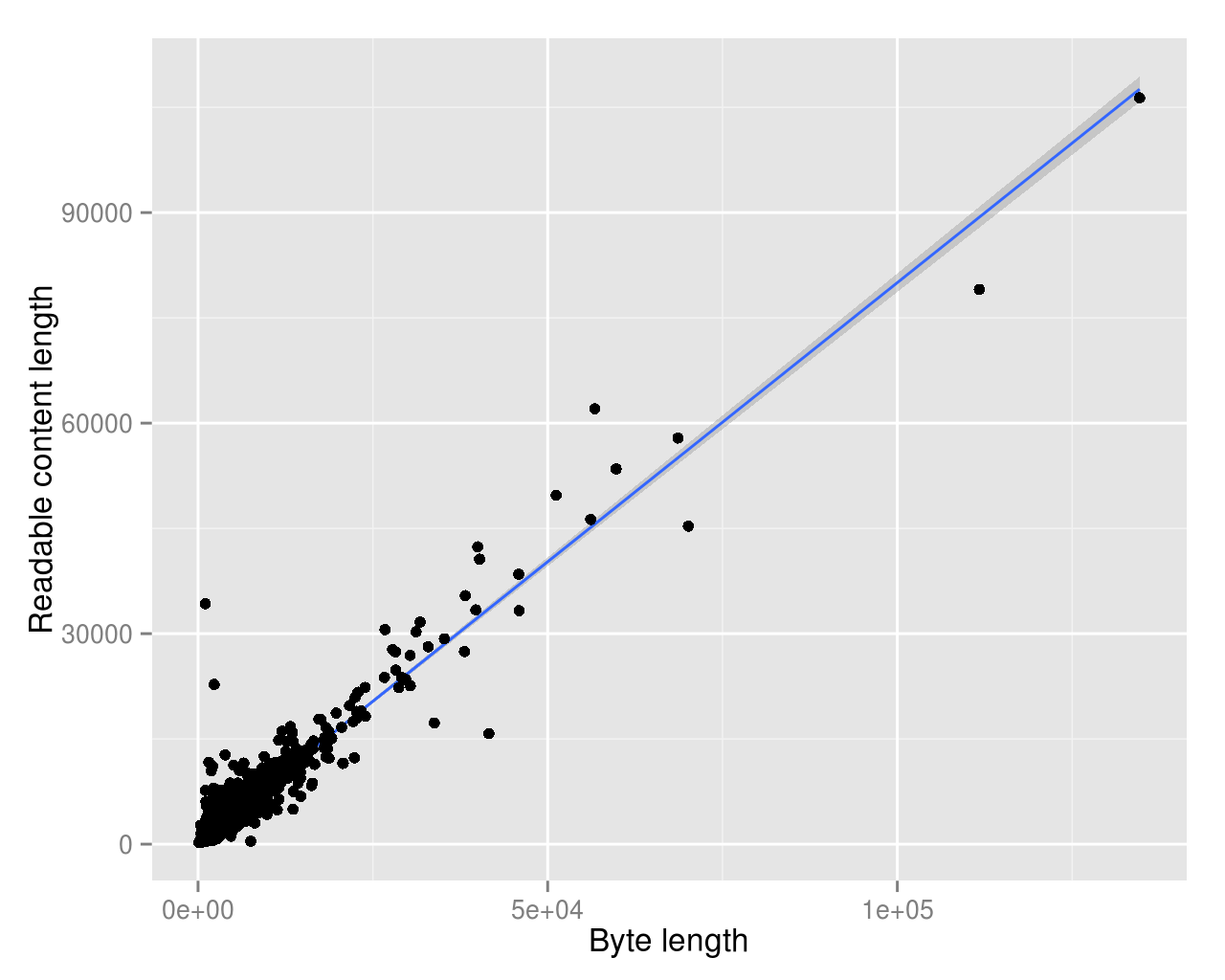
I just replicated this analysis. I think you might have made some
mistakes.
I took a random sample of non-redirect articles from English Wikipedia
and
compared the byte_length (from database) to the content_length (from
API, tags and comments stripped).c
I get a pearson correlation coef of 0,9514766.
See the scatter plot including a linear regression line. See also the
regress
output below.
Call:
lm(formula = byte_len ~ content_length, data = pages)
Residuals:
Min 1Q Median 3Q Max
-38263 -419 82 592 37605
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -97.40412 72.46523 -1.344 0.179
content_length 1.14991 0.00832 138.210 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2722 on 1998 degrees of freedom
Multiple R-squared: 0.9053, Adjusted R-squared: 0.9053
F-statistic: 1.91e+04 on 1 and 1998 DF, p-value: < 2.2e-16
On Mon, Aug 5, 2013 at 12:59 AM, WereSpielChequers <
werespielchequers(a)gmail.com> wrote:
Hi Fabian,
That's interesting. When you say you stripped out the html did you also
strip
out the other parts of the references? Some citation styles will take
up more bytes than others, and citation style is supposed to be consistent
at the article level.
It would also make a difference whether you included or excluded alt
text from
readable material as I suspect it is non granular - ie if someone
is going to create alt text for one picture in an article they will do so
for all pictures.
More significantly there is a big difference in standards of referencing
, broadly
the higher the assessed quality and or the more contentious the
article the more references there will be.
I would expect that if you factored that in there would be some
correlation
between readable length and bytes within assessed classes of
quality, and the outliers would include some of the controversial articles
like Jerusalem (353 references)
Hope that helps.
Jonathan
On 2 August 2013 18:24, Floeck, Fabian (AIFB) <fabian.floeck(a)kit.edu>
wrote:
Hi,
to whoever is interested in this (and I hope I didn't just repeat
someone
else's experiments on this):
I wanted to know if a "long" or "short" article in terms of how much
readable material (excluding pictures) is presented to the reader in the
front-end is correlated to the byte size of the Wikisyntax which can be
obtained from the DB or API; as people often define the "length" of an
article by its length in bytes.
TL;DR: Turns out size in bytes is a really, really bad indicator for the
actual,
readable content of a Wikipedia article, even worse than I thought.
We "curl"ed the front-end HTML of all articles of the English Wikipedia
(ns=0, no disambiguation, no redirects) between 5800 and 6000 bytes (as
around 5900 bytes is the total en.wiki average for these articles). = 41981
articles.
Results for size in characters (w/ whitespaces)
after cleaning the HTML
out:
Min= 95 Max= 49441 Mean=4794.41 Std.
Deviation=1712.748
Especially the gap between Min and Max was interesting. But templates
make it
possible.
(See e.g. "Veer Teja Vidhya Mandir
School", "Martin Callanan" --
Allthough for the ladder you could
argue that expandable template listings
are not really main "reading" content..)
Effectively, correlation for readable character size with byte size =
0.04 (i.e.
none) in the sample.
If someone already did this or a similar analysis, I'd appreciate
pointers.
Best,
Fabian
--
Karlsruhe Institute of Technology (KIT)
Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck
Research Associate
Building 11.40, Room 222
KIT-Campus South
D-76128 Karlsruhe
Phone: +49 721 608 4 6584
Fax: +49 721 608 4 6580
Skype: f.floeck_work
E-Mail: fabian.floeck(a)kit.edu
WWW:
http://www.aifb.kit.edu/web/Fabian_Flöck
KIT – University of the State of Baden-Wuerttemberg and
National Research Center of the Helmholtz Association
_______________________________________________
Wiki-research-l mailing list
Wiki-research-l(a)lists.wikimedia.org
https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
_______________________________________________
Wiki-research-l mailing list
Wiki-research-l(a)lists.wikimedia.org
https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
<ATT00001.c>
--
Karlsruhe Institute of Technology (KIT)
Institute of Applied Informatics and Formal Description Methods
Dipl.-Medwiss. Fabian Flöck
Research Associate
Building 11.40, Room 222
KIT-Campus South
D-76128 Karlsruhe
Phone: +49 721 608 4 6584
Fax: +49 721 608 4 6580
Skype: f.floeck_work
E-Mail: fabian.floeck(a)kit.edu
WWW:
http://www.aifb.kit.edu/web/Fabian_Flöck
KIT – University of the State of Baden-Wuerttemberg and
National Research Center of the Helmholtz Association
_______________________________________________
Wiki-research-l mailing list
Wiki-research-l(a)lists.wikimedia.org
https://lists.wikimedia.org/mailman/listinfo/wiki-research-l
{kind=link}
{kind=link}
{kind=link}
{kind=link}