"I think this is the wrong way round, there
should be an URL/URI there and
a formatter to generate a local string for display
purposes." -JB
Where this URL/URI-to-display is possible, I agree with Jerven; however I'm
(so far) completely naive about wikidata's ingest process (apologies).
Sometimes that accession is all you've got to work with at the start. It is
in some third-party'es database cross reference tables and that's pretty
much it.
Even worse, sometimes the type of the encountered accession is implied by
context but never stated outright (eg. is it gene? genotype? allele?) many
providers of such data have type-specific URLs and integration fails
catastrophically (either collides undetected or 404s) if the wrong type is
assumed. However, if wikidata is ingesting solely data that is *already
well documented with HTTP URIs*, then I agree; start with the HTTP URI.
However, let's first unpack what we mean by 'display' as it is rather
loaded.
*Scenario one: *whatever users 'see' baked in the URLs of wikidata
interface (or other 3rd party #researchparasites like us at Monarch).
*Scenario two: *whatever is actually displayed most prominently in the 3rd
party application web page itself
*Scenario three:* whatever is represented in the land of 3rd party API and
graph stores (RDF)
*For scenario one*, the main objective is stability and identifiability,
rather than immediate human recognition. You could bake in an http uri, for
example:
wikidata.org/record/uri=[http uri]. This works OK if:
A) you're more-or-less in control of the data you're "consuming", and
B) there's one primary URI
C) that URI is not volatile
eagle-i federated search uses this approach, for instance:
[image: Inline image 1]
However, '*control*' and '*uncontested uri*' and* 'permanence'
*occur
infrequently and they almost never co-occur. If 3rd party
consumers/integrators don't have a well-planned strategy a-priori for to
collapse distributed identifier equivalents, they may find it easy to
*aggregate*, but difficult to *integrate*. Especially for highly-accessed
resources (like chembl) with lots of relevant resources that are
distributed and that reference the same chembl entity in endlessly
different ways.
*For scenario two *the main objective is human recognition. On this I'm for
whatever works (labels, names, pictures, whatever), provided that anchor
text is also linked to http URIs and at some point in the link chain
transparent about its origins.
*For scenario three* the main consumer of that format is the tech elite.
Here, the HTTP URI is a first class citizen, however even here, the
self-documenting nature of formats like RDF/JSON is that CURIE identifiers
can still be made easier on the human eye. Many Sporny has a candid and
funny take on this. <http://bit.ly/case-for-curies>
In PrefixCommons <http://bit.ly/biocontext>, we adopt a JSON-LD context
approach (a cornerstone of
schema.org that is already in use in over 10
million websites in the web-at-large). It it is efficient and scaleable for
handling these distributed identifiers, especially for scenarios 1 and 3
above.
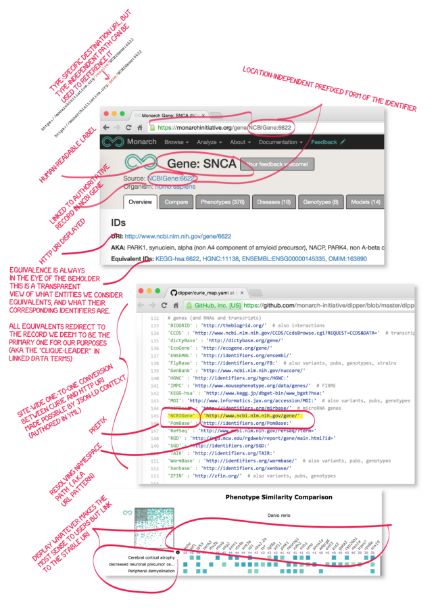
This is the approach we use in Monarch. Wherever possible we display
human-readable labels in the UI; however what we embed in our URLs are
always the location-independent curie version of the ID. I've added to our
identifier documentation marked up screenshots of our identifiers in action
<http://bit.ly/monarch-ids> in our site using NCBIGene:6622 as an example.
[image: Inline image 2]
I've omitted the painful parts about the state of the identifiers when we
find them in ingested data, but just as a quick illustration, see this (38
distinct shortform representations, and 14 distinct http URIs)
<http://bit.ly/ncbi-identifier-permutations>. Note that all these
permutations correspond to *a single identifier, NCBIGene:6622*, not to a
class of identifiers, or a class of providers, or to similar entities
spread across disparate resources. The state-of-affairs in database lookups
is much the same as what you see in the web-at-large but to document that
that would require a lot more effort.
The bottom line is that it doesn't matter how messy the identifiers are
when you find them. Or how many different ways you find them. You can
always create a curie form that links to the right place and you can use
JSON-LD to provide context-specific direction.
For instance: in the following contexts expand the CURIE to the chembl
webpage, in these other contexts, expand to the (sometimes unresolvable)
HTTP URI, in these other contexts, expand to the wikidata page for the
entity. This approach is simple and it works.
Hope this was helpful?
Best wishes,
Julie
ps. The heterogeneity of identifiers also has major implications for data
citation in journals; however, I've not touched that subject here as it is
quite different (there's an archived PDF that can not be dynamically
updated to change the identifiers or links).
{kind=link}