Still comparing a dataset (Wikidata) to an integration hub (DBpedia).
I would assume that popularity of content (e.g. Wikipedia page hits)
directly relates to availability of data in Wikidata.
We have long fused all of this in a "best of" called FlexiFusion:
https://svn.aksw.org/papers/2019/ISWC_FlexiFusion/public.pdf
Future agenda is to:
- stabilize this release variant of DBepdia (fused and enriched)
- mix in external (authoritative) datasets based on the references in WP
and WD to create ultimate lists (total global coverage and correctness)
- export enriched versions either using Wikidata's P's or WP's
infoboxes, so it can be integrated back into Wikimedia (with references)
and also sync it to whoever needs the data.
This is part of GlobalFactSyncRE:
https://meta.wikimedia.org/wiki/Grants:Project/DBpedia/GlobalFactSyncRE
The formula here is quite easy: If you look at DBpedia's data in detail
or a part of it, it will not shine so much since it is extracted, if you
look at the flexibility and scalability of integration it will win. We
are strengthening the tooling for the second part.
-- Sebastian
On 22.09.19 01:35, Andra Waagmeester wrote:
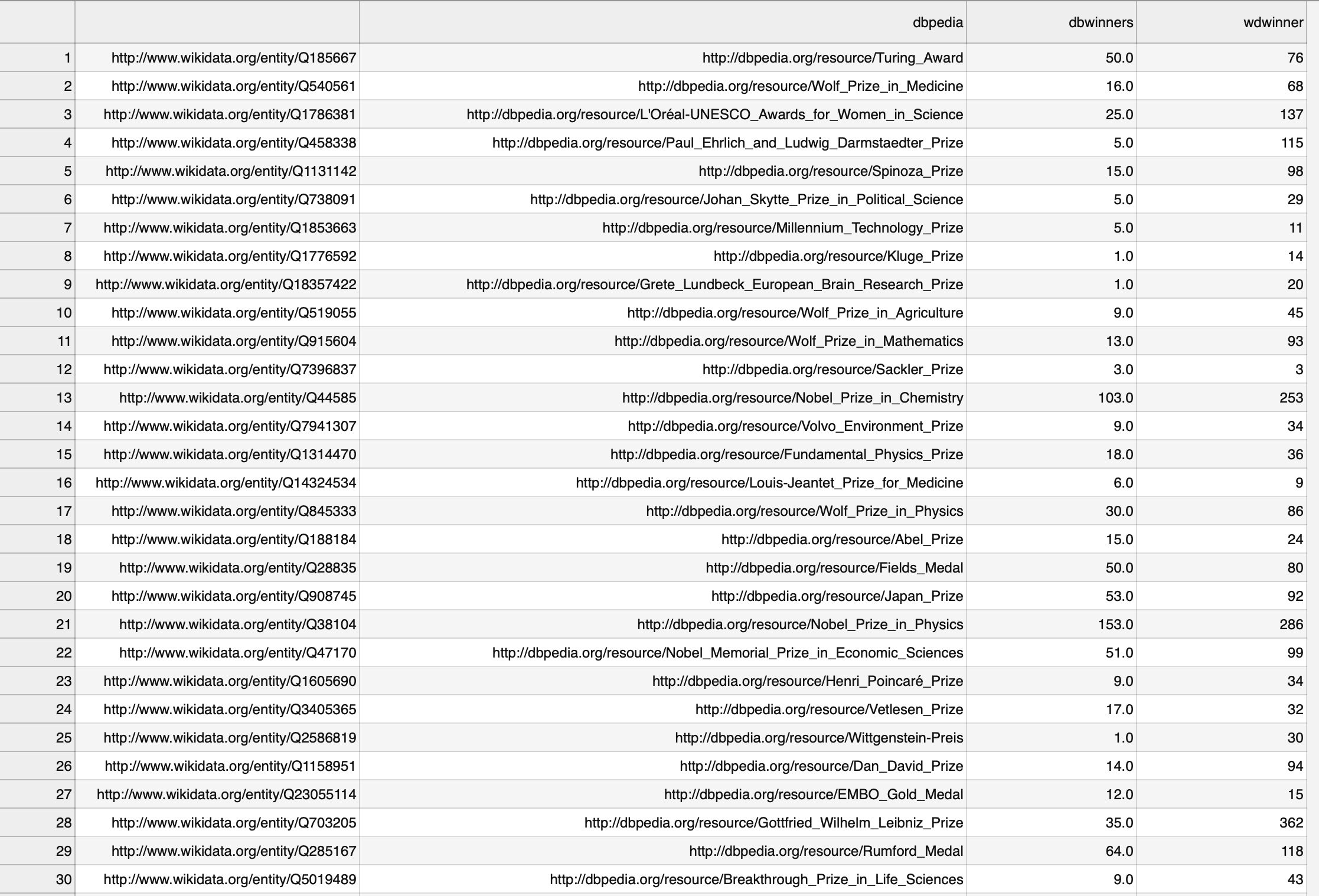
Agree, I am also interested in seeing this. I recently
did a small
comparison on science awards on coverage of laureates in both DBpedia
and wikidata and came to the same conclusion. The difference sometimes
was quite substantial in favour of Wikidata.
image.png
I would also be very interested in seeing this. I had a closer
look at
DBpedia recently for a tutorial and was surprised by how different
the
data is in comparison to Wikidata. A methodological comparison would
surely be helpful.
Of course, it has to be fair, taking into account that DBpedia
editions
are based on a Wikipedia in one language (hence is always missing
entities that Wikidata has). For example, I recently computed the
difference between the following two:
(1) The set of all pairs of ancestors that one can find by following
(paths of) parent relations on EN DBPedia.
(2) The set of all pairs of ancestors that one can find by following
(paths of) mother/father relations on Wikidata, but visiting only
items
that are present in English Wikipedia.
I am not sure if this is fair or not, but I found it an interesting
setup (non-local effects of incompleteness) -- and (2) is a nice
illustration of something you cannot achieve in SPARQL on principled
grounds ;-).
Cheers,
Markus
_______________________________________________
Wikidata mailing list
Wikidata(a)lists.wikimedia.org <mailto:Wikidata@lists.wikimedia.org>
https://lists.wikimedia.org/mailman/listinfo/wikidata
_______________________________________________
Wikidata mailing list
Wikidata(a)lists.wikimedia.org
https://lists.wikimedia.org/mailman/listinfo/wikidata --
All the best,
Sebastian Hellmann
Director of Knowledge Integration and Linked Data Technologies (KILT)
Competence Center
at the Institute for Applied Informatics (InfAI) at Leipzig University
Executive Director of the DBpedia Association
Projects:
http://dbpedia.org,
http://nlp2rdf.org,
http://linguistics.okfn.org,
https://www.w3.org/community/ld4lt
<http://www.w3.org/community/ld4lt>
Homepage:
http://aksw.org/SebastianHellmann
Research Group:
http://aksw.org
{kind=link}