Hi Phillipe!
We are actively discussing some of this over in the Telegram channel for
Wikidata Lexicographical data, which I think you are already aware of?
Lucas Werkmeister noted that he has drafted an improvement over and above
my changes from yesterday.
You might go to Telegram and join the discussion there, or stay here and
discuss, that's fine.
Here is the draft that Lucas put together thus far... (green color is his
proposed changes for that Doc page).
On Thu, Jul 1, 2021 at 10:24 PM Philippe Verdy <verdyp(a)gmail.com> wrote:
I still DO NOT AGREE with these statements:
** "Lemma* (plural *Lemmas*) for use as a human readable representation
of the lexeme, e.g. "run" or "when pigs fly".
WRONG. By definition the human readable form is NOT the LEMMA, but the
LEXEME by definition (even if it can have different written forms, e.g. for
plurals, or mutations, or alternate orthographies with minor differences
such as variable accents, or presence/absence of hyphens in compound forms)
* "A Lexeme can have several lemmas, even though it is rare"
The last assertion is completely false: a lexeme VERY FREQUENTLY has
multiple lemmas (each lemma however carry a SINGLE sense, by definition!)
* "A list of *Senses*, describing the different meanings of the lexeme"
The different meanings of the lexeme are given by the list of its lemmas
(so I maintain that LEMMA=SENSE)
We have an unnecessary abstraction level (and this is already visible in
the interface): this just complicates the model by adding an extra object
(meaning it is inefficient to process, requires additional queries, and
maintenance).
Lexemes must be at the root of the tree ! Note that a lexeme can contain
multiple words for a complete expression or necessary particles,
prepositions, postpositions or other terms (like reflective pronouns), e.g.
for verbs (notably in English for verbal particles in prefix or suffix, as
in "to fill in" which as both, or "se"/"s'" in French,
these particles may
be agglutinated and muted, detached or reordered elsewhere in the sentence
depending on forms or combined with other particles (e.g. in German
"hereinkommen"-> "Er kommt herein.", "Für hereinzukommen,
..."), but they
keep their semantic meaning.
Forms of lexemes lowever have restrictions of usage: NOT ALL forms are
usable for EVERY lemma=sense of the same lexeme (e.g. a lemma=sense would
be only valid for some forms and not for others, e.g. plural forms): this
is not frequent but not exceptional.
Note as well that some forms (e.g. the plural) may change the grammatical
gender or case: a singular noun could be masculine, but its plural feminine
(typical example un French: for the same lemma=sense of the lexeme
"amour", the form "amour" found in "mon amour" is masculine
as a singular
noun, but the form "amours" found in "mes amours" i is feminine as a
plural
noun).
So the real schema is:
LEXEME
* 0. is language specific.
* 1. possibly made of several LEXEMES
* 2. has one or more FORMS
- 2a. the first form is the most generic one (e.g. the singular form if
it exists for a noun or adjective ; the present infinitive form if it
exists for a verb, because verbs can be defective some some tense, modes).
The first form generally carries all grammatical characteristic used by
default for all other forms.
- 2b. each additional form can have modifications of the base
grammatical classification but generally they inherit them unless they are
overridden.
- 2c.
- 2c. some forms may be equivalent to other forms of the same lexeme,
so we need one or more REPRESENTATIONS to exhibit them (including in other
script systems, such as Latin, Cyrillic, or under different orthographic
systems and reforms)
* 3. has one or several LEMMAS=SENSES
3a. each lemma=sense could contain some restrictions on the applicable
forms
3b. the lemma has a definition of its sense
3d. the lemma may be valid only in some context (e.g. specialized
terminology for a domain) or forbidden/depreciated in other contexts (e.g.
slang words, popular/vulgar speech, formal declarations)
3c. the lemma is translatable to one or more lemmas in the
target language defined separately within a different lexeme specific to
that target language
In all cases, each lemma belongs to a single lexeme.
Le jeu. 1 juil. 2021 à 00:01, Thad Guidry <thadguidry(a)gmail.com> a écrit :
We've just updated the Data Model with
1. a quick textual hierarchy of the data model from a high level.
2. a few more sentences for "Lemma" bullet point to help explain things a
bit better.
(Thanks to a few folks on our Telegram channel)
Take a look!
https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Documentation#D…
Thad
https://www.linkedin.com/in/thadguidry/
https://calendly.com/thadguidry/
On Wed, Jun 30, 2021 at 2:03 PM Thad Guidry <thadguidry(a)gmail.com> wrote:
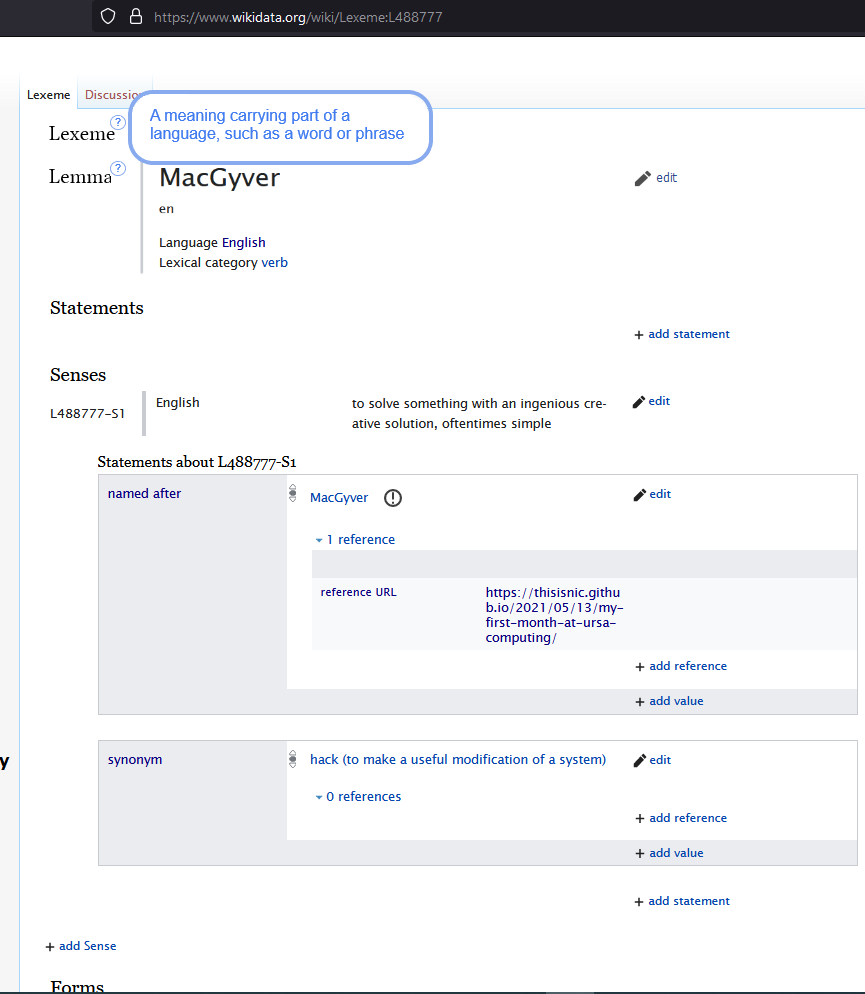
And furthermore... perhaps some small help
iconography buttons added for
newcomers that must be clicked to see the help info (not hoverable, as that
would interfere)
And where the help text would be translatable and the definitions taken
from our Data Model and displayed in your Wikidata language preference.
For Example:
[image: Proposed_Lexeme_Page_Tooltip_Bubble.png]
- Thad
https://www.linkedin.com/in/thadguidry/
https://calendly.com/thadguidry/
On Wed, Jun 30, 2021 at 1:36 PM Thad Guidry <thadguidry(a)gmail.com>
wrote:
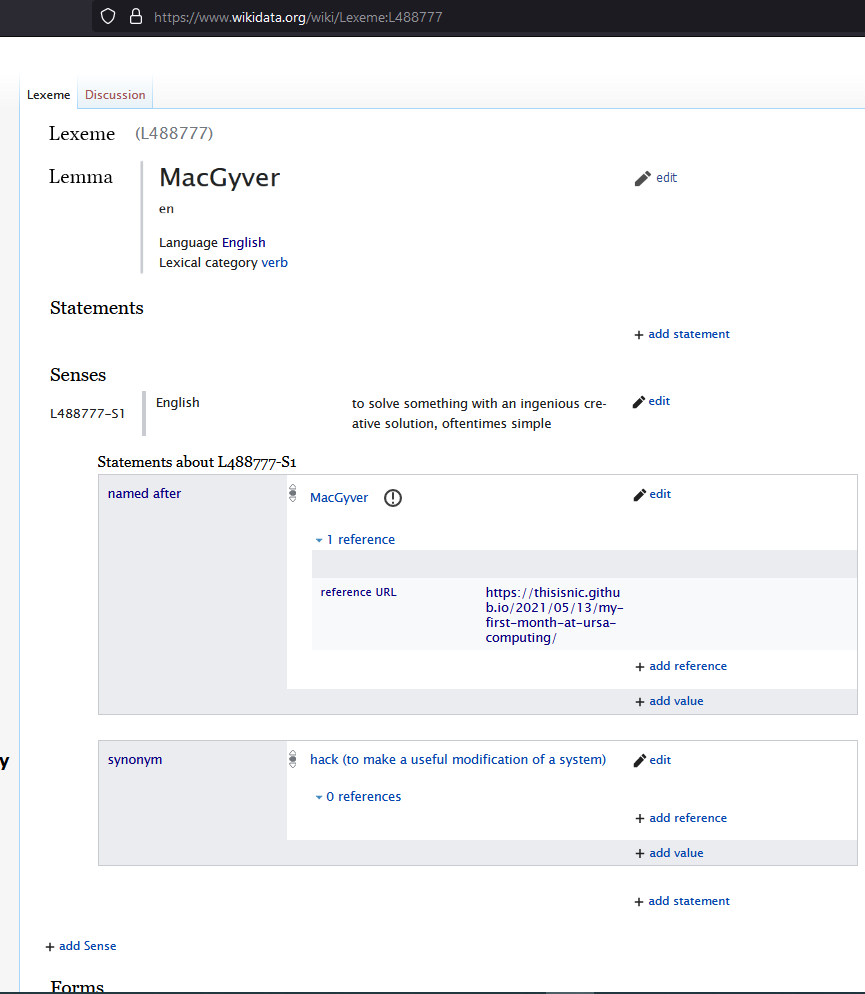
> What do folks think of this for a proposed better view of our existing
> Lexeme page (so that it aligns better with our described Data Model in
> SVG
>
<https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Documentation#/media/File:Lexeme_data_model.svg>)
> to help visualize our data model better on the Lexeme pages themselves?
> Does this align with it? Better? Worse? Needs tweaks?
>
> [image: Proposed_Lexeme_Page.png]
>
> Thad
>
https://www.linkedin.com/in/thadguidry/
>
https://calendly.com/thadguidry/
>
>
> On Wed, Jun 30, 2021 at 1:33 PM Douglas Clark <clarkdd(a)gmail.com>
> wrote:
>
>> Agreed mostly. A lexeme is the head word that stands-in for all forms
>> of the same meaning (forms of the same meaning equals lemma or sense).
>> Let's not forget that a lexeme can be more than one word (fire engine,
>> speak up, and even RTFM). From a word perspective, a lexeme is many to
>> many, yet mostly one to many, AND the lexeme as a head word in one
>> repository could also be a lemma of some lexeme in another repository.
>> Author choice. Just wait until you get to the rules of how to select the
>> correct lemma-sense from a lexeme's collection when the clue to the right
>> sense is a sentence four sentences away. It's just going to get more
>> complicated from here. Sadly, Abstract is probably the last large
>> scale manual tagging effort, as there are a plethora of existing tagged
>> corpora that can support Abstract if you would just use a bit of machine
>> learning. Please don't say it's too hard to understand where or how the
>> magic happens, as there is actually a machine learning for dummies book.
>> It's just different.
>>
>> On Wed, Jun 30, 2021 at 10:49 AM Philippe Verdy <verdyp(a)gmail.com>
>> wrote:
>>
>>> You are again making a sever confusion between "lexemes" (your
>>> comment is true about them: it is a form in some orthographic system) and
>>> "lemmas" (strictly identical to "senses").
>>>
>>> I just said that your schema makes 1-to-many relations between LEMMAS
>>> and SENSES where this should be 1-to-1.
>>>
>>> there are 1-to-many relations from LEXEMES to LEMMAS=SENSES, I've not
>>> contested that. but we cannot use LEXEMES as the base of text
>>> abstraction (in an abstract language), we'll use LEMMAS.
>>>
>>> We don't need any complex relation like LEXEME --(1-to-N)--> LEMMA
>>> --(1-to-N)--> SENSE (the second pair is non-sense it should be 1-to-1,
and
>>> thus merged).
>>>
>>> The abstract text will contain LEMMAS (semantic), from which some
>>> rules will decide which lexeme (lexical and very specific to each language)
>>> to use according to the target language and other constraints, and then
>>> which form of the lexeme (grammatical
>>> derivations/inflections/conjugation/contextual mutations or particles, plus
>>> capitalizing rules for some syntaxic or presentation forms)
>>>
>>>
>>> Le mer. 30 juin 2021 à 13:18, Andy <borucki.andrzej(a)gmail.com> a
>>> écrit :
>>>
>>>> Most of most frequent lexems has more than one sense, one sense
>>>> usually have only rare lexems.
>>>> While adding lexem and sense, one must fill not "definition"
but
>>>> "gloss" which should be very short. For example for
"dog" is gloss "mammal"
>>>> although cat and cow are also mammals. It will be good if were both
gloss
>>>> and definition?
>>>> _______________________________________________
>>>> Abstract-Wikipedia mailing list --
>>>> abstract-wikipedia(a)lists.wikimedia.org
>>>> List information:
>>>>
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
>>>>
>>> _______________________________________________
>>> Abstract-Wikipedia mailing list --
>>> abstract-wikipedia(a)lists.wikimedia.org
>>> List information:
>>>
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
>>>
>> _______________________________________________
>> Abstract-Wikipedia mailing list --
>> abstract-wikipedia(a)lists.wikimedia.org
>> List information:
>>
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
>>
> _______________________________________________
Abstract-Wikipedia mailing
list -- abstract-wikipedia(a)lists.wikimedia.org
List information:
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
_______________________________________________
Abstract-Wikipedia mailing list -- abstract-wikipedia(a)lists.wikimedia.org
List information:
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
{kind=link}
{kind=link}