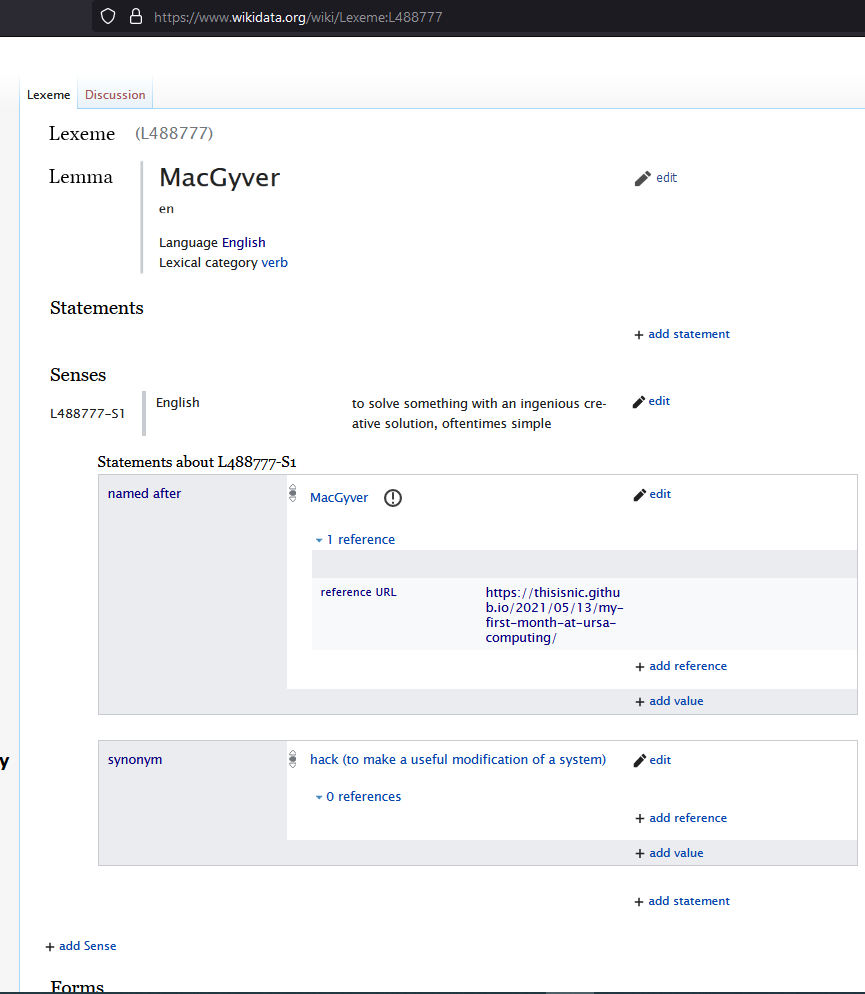
What do folks think of this for a proposed better view of our existing
Lexeme page (so that it aligns better with our described Data Model in SVG
<https://www.wikidata.org/wiki/Wikidata:Lexicographical_data/Documentation#/media/File:Lexeme_data_model.svg>)
to help visualize our data model better on the Lexeme pages themselves?
Does this align with it? Better? Worse? Needs tweaks?
[image: Proposed_Lexeme_Page.png]
Thad
On Wed, Jun 30, 2021 at 1:33 PM Douglas Clark <clarkdd(a)gmail.com> wrote:
Agreed mostly. A lexeme is the head word that
stands-in for all forms of
the same meaning (forms of the same meaning equals lemma or sense). Let's
not forget that a lexeme can be more than one word (fire engine, speak up,
and even RTFM). From a word perspective, a lexeme is many to many, yet
mostly one to many, AND the lexeme as a head word in one repository could
also be a lemma of some lexeme in another repository. Author choice. Just
wait until you get to the rules of how to select the correct lemma-sense
from a lexeme's collection when the clue to the right sense is a sentence
four sentences away. It's just going to get more complicated from here.
Sadly, Abstract is probably the last large scale manual tagging effort, as
there are a plethora of existing tagged corpora that can support Abstract
if you would just use a bit of machine learning. Please don't say it's too
hard to understand where or how the magic happens, as there is actually a
machine learning for dummies book. It's just different.
On Wed, Jun 30, 2021 at 10:49 AM Philippe Verdy <verdyp(a)gmail.com> wrote:
You are again making a sever confusion between
"lexemes" (your comment is
true about them: it is a form in some orthographic system) and "lemmas"
(strictly identical to "senses").
I just said that your schema makes 1-to-many relations between LEMMAS and
SENSES where this should be 1-to-1.
there are 1-to-many relations from LEXEMES to LEMMAS=SENSES, I've not
contested that. but we cannot use LEXEMES as the base of text
abstraction (in an abstract language), we'll use LEMMAS.
We don't need any complex relation like LEXEME --(1-to-N)--> LEMMA
--(1-to-N)--> SENSE (the second pair is non-sense it should be 1-to-1, and
thus merged).
The abstract text will contain LEMMAS (semantic), from which some
rules will decide which lexeme (lexical and very specific to each language)
to use according to the target language and other constraints, and then
which form of the lexeme (grammatical
derivations/inflections/conjugation/contextual mutations or particles, plus
capitalizing rules for some syntaxic or presentation forms)
Le mer. 30 juin 2021 à 13:18, Andy <borucki.andrzej(a)gmail.com> a écrit :
Most of most frequent lexems has more than one
sense, one sense usually
have only rare lexems.
While adding lexem and sense, one must fill not "definition" but
"gloss"
which should be very short. For example for "dog" is gloss "mammal"
although cat and cow are also mammals. It will be good if were both gloss
and definition?
_______________________________________________
Abstract-Wikipedia mailing list --
abstract-wikipedia(a)lists.wikimedia.org
List information:
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
_______________________________________________
Abstract-Wikipedia mailing list -- abstract-wikipedia(a)lists.wikimedia.org
List information:
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
_______________________________________________
Abstract-Wikipedia mailing list -- abstract-wikipedia(a)lists.wikimedia.org
List information:
https://lists.wikimedia.org/postorius/lists/abstract-wikipedia.lists.wikime…
{kind=link}