Hey all, quick update with a summary of where we stand and the plan of
attack.
tl;dr: It's probably the known-to-be-busted nginx sequence numbers on the
SSL boxes polluting the average. We should modify PacketLossLogtailer.py to
drop their entries.
1. Ganglia Numbers
As the Ganglia numbers are our main operational metric for
data-integrity/analytics system health, it's essential we understand how
they're generated.
A rough outline:
- The PacketLossLogtailer.py script aggregates the packet-loss.log and
reports to Ganglia
- packet-loss.log, in turn, is generated by bin/packet-loss from the udplog
project. From Andrew's previous email, lines look like (SPOILER ALERT):
[2013-03-20T21:38:47] ssl1 lost: (62.44131 +/- 4.19919)%
[2013-03-20T21:38:47] ssl1001 lost: (66.71974 +/- 0.20411)%
[2013-03-20T21:38:47] ssl1002 lost: (66.78863 +/- 0.19653)%
Andrew is digging into the source to ensure we understand how these error
intervals are generated, especially given the logtailer drops entries with
a high error margin.
We assume we won't find anything shocking in packet-loss.cpp, but we need
to be sure we understand what these numbers mean.
2. Current Alerts
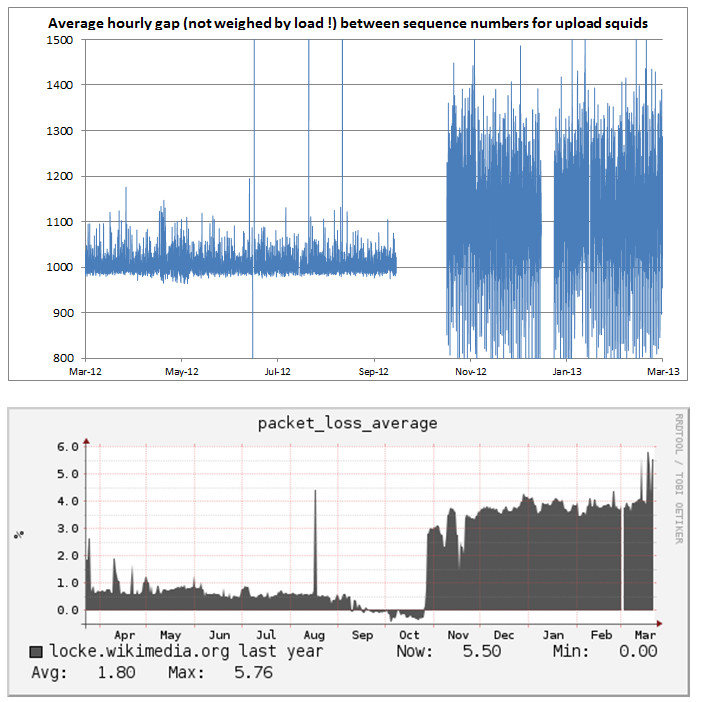
Erik Zachte performed analysis of sequence number deltas via the sampled
1:1000 squid logs, finding the SSL hosts had loss 60%+; Andrew verified
this using the packet-loss logs. It's a known bug that nginx generates
busted sequence numbers, so this is probably the explanation. Andrew is
following up.
There's a clear trend visible if you look at the loss numbers over the last
month -- the 90th shows it most clearly:
- 90th Percentile:
http://ganglia.wikimedia.org/latest/graph.php?r=month&z=xlarge&titl…
- Average:
http://ganglia.wikimedia.org/latest/graph.php?r=month&z=xlarge&titl…
- Last week:
http://ganglia.wikimedia.org/latest/graph.php?r=week&z=xlarge&title…
As Oxygen does not receive logging from the SSL proxies, this seems almost
certain to be the answer.
However, while filtering out entries in the packet-loss log from the SSL
hosts might fix the alerts, it doesn't explain why we're seeing the
increase in the first place. More troubling, there was a huge increase in
Oct that we somehow did not notice:
- Average:
http://ganglia.wikimedia.org/latest/graph.php?r=year&z=xlarge&title…
- 90th:
http://ganglia.wikimedia.org/latest/graph.php?r=year&z=xlarge&title…
There are theories aplenty, with both load and filters contributing to the
loss numbers. Further, different filters run on each box (themselves with a
wide range of hardware), so their performance isn't perfectly comparable.
Andrew's on point looking into these questions, but the immediate next-step
is to ignore the SSL machines in the packet-loss log. Modifying
PacketLossLogtailer.py lets us preserve the data for future analysis.
--
David Schoonover
dsc(a)wikimedia.org
On Wed, Mar 20, 2013 at 3:11 PM, Diederik van Liere <dvanliere(a)wikimedia.org
wrote:
> I do think that the Nginx / SSL servers are skewing the packetloss numbers
> because
https://rt.wikimedia.org/Ticket/Display.html?id=859 has never
> been resolved.
> D
>
>
> On Wed, Mar 20, 2013 at 6:02 PM, Andrew Otto <otto(a)wikimedia.org
wrote:
>
>> (Tim, I'm CCing you here, maybe you can help me interpret udp2log packet
>> loss numbers?)
>>
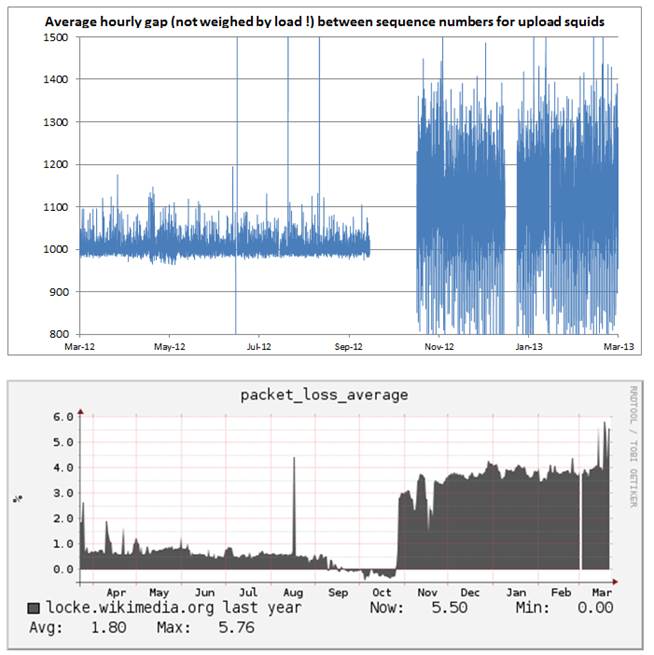
>> Hm, so, I've set up gadolinium as a 4th udp2log webrequest host. It's
>> running some (but not all) of the same filters that locke is currently
>> running. udp2log packet_loss_average has hovered at 4 or 5% the entire
>> time it has been up.
>>
>>
>>
http://ganglia.wikimedia.org/latest/graph_all_periods.php?c=Miscellaneous%2…
>>
>> Is that normal? I don't think so. This leads me to believe that my
>> previous diagnosis (increased traffic hitting some thresholds) was wrong.
>>
>> I see high numbers for packet loss from the SSL machines in both locke
>> and gadolinium's packet-loss.log. e.g.
>>
>> [2013-03-20T21:38:47] ssl1 lost: (62.44131 +/- 4.19919)%
>> [2013-03-20T21:38:47] ssl1001 lost: (66.71974 +/- 0.20411)%
>> [2013-03-20T21:38:47] ssl1002 lost: (66.78863 +/- 0.19653)%
>> …
>>
>> Also, some of
sq*.wikimedia.org hosts (I think these are the Tampa
>> squids) have higher than normal packet loss numbers, whereas the eqiad and
>> exams hosts are mostly close to 0%.
>>
>> Could it be that a few machines here are skewing the packet loss average?
>>
>> The fact that gadolinium is seeing packet loss with not much running on
>> in indicates to me that I'm totally missing something here. Since the data
>> on gadolinium isn't being consumed yet, and its still duplicated on locke,
>> I'm going to turn off pretty much all filters there and see what happens.
>>
>> -Ao
>>
>>
>>
>>
>> On Mar 19, 2013, at 10:11 AM, Andrew Otto <otto(a)wikimedia.org
wrote:
>>
>> (Jeff, I'm CCing you here because you're involved in locke stuff.)
>>
>>
>>
>> 1. how well does the solution reduce/eliminate packet loss? (Erik Z's
>> input useful here)
>>
>> I could be totally wrong with my diagnosis of the problem (especially
>> since there was packet loss on emery yesterday too), but I believe that if
>> we do the proposed solutions (replace locke, reduce filters on oxygen) this
>> should eliminate the regular packet loss for the time being. emery might
>> need some help too. Perhaps we can keep locke around for a while longer
>> and spread out emery's filter's between the locke and gadolinium.
>>
>> 2. is the solution temporary or permanent?
>>
>> If it solves the problem, this is as permanent as it gets. We can expect
>> traffic to only increase, so eventually this problem could happen again.
>> Also, people always want more data, so its possible that there will be
>> enough demand for new filters that our current hardware would reach
>> capacity again. Eventually we'd like for Kafka to replace much of
>> udp2log's functionality. That is our actual permanent solution.
>>
>> 3. how soon could we implement the solution?
>>
>> I will work on gadolinium (locke replacement) today. Oxygen filter
>> reduction is pending verification from Evan that it is ok to do so. He's
>> not so sure.
>>
>> 4. what kind of investment in time/resource would it would take and from
>> whom (likely)?
>>
>> locke replacement shouldn't take more than a day. The production
>> frontend cache servers all need config changes deployed to them. I'd need
>> to get that reviewed and a helpful ops babysitter.
>>
>> Jeff Green has special fundraising stuff on locke, so we'd need his help
>> to migrate that off. Perhaps we should leave locke running and let Jeff
>> Green keep it for Fundraising?
>>
>>
>>
>>
>> On Mar 18, 2013, at 9:31 PM, Kraig Parkinson <kparkinson(a)wikimedia.org>
>
wrote:
>>
>> Andrew/Diederik, we've captured a lot of info in this thread so far.
>> Could you briefly articulate/summarize the set of options we have for
>> solving this problem as well as help us understand the trade-offs?
>>
>> I'm interested in seeing the differences in terms of the following:
>> 1. how well does the solution reduce/eliminate packet loss? (Erik Z's
>> input useful here)
>> 2. is the solution temporary or permanent?
>> 3. how soon could we implement the solution?
>> 4. what kind of investment in time/resource would it would take and from
>> whom (likely)?
>>
>> Kraig
>>
>>
>> On Mon, Mar 18, 2013 at 2:02 PM, Rob Lanphier <robla(a)wikimedia.org>wrote;wrote:
>>
>>> Hi Diederik,
>>>
>>> I don't think it'd be responsible to let this go on for another 2-3
>>> days. It's already arguably been going on for too long as it stands.
>>> If you all haven't been cautioning people to adjust their numbers
>>> based on known loss, and you haven't been doing that yourselves, you
>>> probably should let folks know.
>>>
>>> At any rate, I'm probably not the customer here. In the team, Erik
>>> Zachte probably has the best perspective on what is acceptable and
>>> what isn't, so I'm cc'ing him.
>>>
>>> Rob
>>>
>>> On Mon, Mar 18, 2013 at 12:31 PM, Diederik van Liere
>>> <dvanliere(a)wikimedia.org
wrote:
>>> > Robla: when you say 'soonish' what exact timeframe
do you have in mind
>>> for
>>> > solving this?
>>> > D
>>> >
>>> >
>>> > On Mon, Mar 18, 2013 at 3:25 PM, Diederik van Liere
>>> > <dvanliere(a)wikimedia.org
wrote:
>>> >>
>>> >> Office wiki:
https://office.wikimedia.org/wiki/Partner_IP_Ranges
>>> >> udp-filter config:
>>> >>
>>>
https://gerrit.wikimedia.org/r/gitweb?p=operations/puppet.git;a=blob;f=temp…
>>> >> D
>>> >>
>>> >>
>>> >> On Mon, Mar 18, 2013 at 2:51 PM, David Schoonover
<dsc(a)wikimedia.org>
>>> >
wrote:
>>>
>>>
>>> >>> For reference, here's the varnish config in
operations/puppet.
>>> >>>
>>> >>>
>>> >>>
>>>
https://gerrit.wikimedia.org/r/gitweb?p=operations/puppet.git;a=blob;f=temp…
>>> >>>
>>> >>> I don't have links to the office wiki list or the udp-filter
config;
>>> >>> Deiderik, could you link them just to double-check?
>>> >>>
>>> >>>
>>> >>>
>>> >>> --
>>> >>> David Schoonover
>>> >>> dsc(a)wikimedia.org
>>> >>>
>>> >>>
>>> >>> On Mon, Mar 18, 2013 at 11:41 AM, Diederik van Liere
>>> >>> <dvanliere(a)wikimedia.org
wrote:
>>> >>>>
>>> >>>>
>>> >>>>> It's not a big difference, but it seems like good
reason to be a
>>> little
>>> >>>>> wary about switching between the ip logic and the
varnish logic.
>>> Thoughts?
>>> >>>>
>>> >>>>
>>> >>>> There is no fundamental difference between ip logic and
varnish
>>> logic,
>>> >>>> varnish sets the X-CS header on the same ip-ranges as
udp-filter
>>> does. I
>>> >>>> just checked the office wiki, the varnish config and
udp-filter and
>>> for
>>> >>>> Orange Uganda everything looks good.
>>> >>>>
>>> >>>> D
>>> >>>
>>> >>>
>>> >>
>>> >
>>>
>>
>>
>>
>>
>
{kind=link}
{kind=link}
{kind=link}
{kind=link}