Hi Dan,
Thanks for a detailed answer!
There may be some confusion here. The timestamps shown on the dumps website
are in the UTC timezone. The time on your computer is
in your local
timezone. I'll answer inline below, but this is an important detail.
...
We move the data as soon as possible to the public dump server, but it's a
large slow transfer. It takes ~50 minutes to process
the raw data, then
some time for the job that copies to run, then at least an hour for the
copy itself. So this is as fast as we can currently make it without
different infrastructure.
I have a UTC+1 time zone and taking into account what you’ve written, the
delay is completely explained, and right now looks like there’s no other
way to do this faster.
In our project, we rely on ML models that are retrained on newly collected
data each 5-30 minutes depending on the model. Hence, it’s crucial to get
the data as soon as possible. Currently, we plan to add Wikipedia pageviews
data (daily & hourly) to the pipeline.
How real is it that the delivery approach of fresh data will be changed?
What is the ETA (very rough estimation: several weeks/months/years)? If
this can be done, the next step I see is to check on our side how the delay
of several hours impacts model quality.
Kind regards,
Maxim
On Fri, May 13, 2022 at 8:19 PM Dan Andreescu <dandreescu(a)wikimedia.org>
wrote:
On Fri, May 13, 2022 at 11:26 AM Maxim Aparovich
<max.aparovich(a)gmail.com>
wrote:
Dear Sir or Madam,
Hi!
Writing to you with a question about Pageviews hourly raw data files
<https://dumps.wikimedia.org/other/pageviews/readme.html>. First of all,
let me know if I chose the right person for a question. If not, could you
please advise to whom I should direct the question? The question is below.
This is the right place to contact the folks at WMF that work on data
engineering, analytics, and public datasets.
I am working on a project where we would like to use Pageviews hourly data
<https://dumps.wikimedia.org/other/pageviews/readme.html>. For us, it is
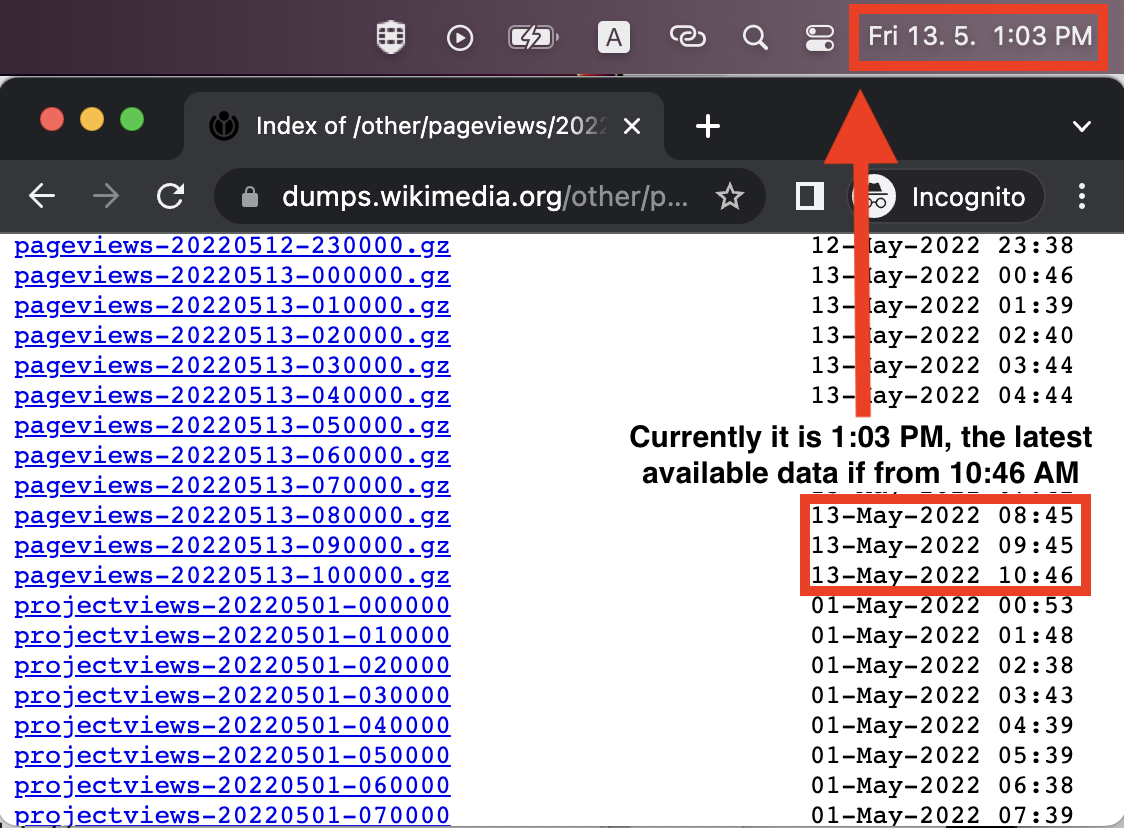
crucial to get data as soon as possible. As I can see on the web page,
hourly data is available in the Wikimedia's file system approximately 45min
after the hour ends. But for an end-user, it is available several hours
later after that (this is shown on the screenshot).
There may be some confusion here. The timestamps shown on the dumps
website are in the UTC timezone. The time on your computer is in your
local timezone. I'll answer inline below, but this is an important detail.
1. Is there any way to get data as soon as it is available on the
Wikimedia filesystem (~45 min after the hour ends)?
We move the data as soon as possible to the public dump server, but it's
a
large slow transfer. It takes ~50 minutes to process the raw data, then
some time for the job that copies to run, then at least an hour for the
copy itself. So this is as fast as we can currently make it without
different infrastructure.
1. Are there any other faster ways to get hourly data? For instance,
faster access to raw data files or access to *wmf.pageview_hourly
<https://wikitech.wikimedia.org/wiki/Analytics/Data_Lake/Traffic/Pageview_hourly>*
or
to *wmf.pageviews_actor
<https://wikitech.wikimedia.org/wiki/Analytics/Data_Lake/Traffic/Pageview_actor>*.
Unfortunately,
API does not provide the opportunity to get data on an hourly level.
We wanted to provide hourly data via the API, but it's very costly in
terms of
storage space. There is no other way to access it, for privacy
reasons. The `pageview_hourly` table needs to be sanitized before we can
publish it, but we're always improving our pipelines. Which brings me to a
question: what is your use case? If we can find enough folks who need
fresh data for good reasons, we can consider different approaches.
_______________________________________________
Analytics mailing list -- analytics(a)lists.wikimedia.org
To unsubscribe send an email to analytics-leave(a)lists.wikimedia.org
{kind=link}